 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemEval-2025 Task 3: Mu-SHROOM, the Multilingual Shared Task on Hallucinations and Related Observable Overgeneration Mistakes
Apr 16, 2025We present the Mu-SHROOM shared task which is focused on detecting hallucinations and other overgeneration mistakes in the output of instruction-tuned large language models (LLMs). Mu-SHROOM addresses general-purpose LLMs in 14 languages, and frames the hallucination detection problem as a span-labeling task. We received 2,618 submissions from 43 participating teams employing diverse methodologies. The large number of submissions underscores the interest of the community in hallucination detection. We present the results of the participating systems and conduct an empirical analysis to identify key factors contributing to strong performance in this task. We also emphasize relevant current challenges, notably the varying degree of hallucinations across languages and the high annotator disagreement when labeling hallucination spans.
Semantic Library Adaptation: LoRA Retrieval and Fusion for Open-Vocabulary Semantic Segmentation
Mar 27, 2025Open-vocabulary semantic segmentation models associate vision and text to label pixels from an undefined set of classes using textual queries, providing versatile performance on novel datasets. However, large shifts between training and test domains degrade their performance, requiring fine-tuning for effective real-world applications. We introduce Semantic Library Adaptation (SemLA), a novel framework for training-free, test-time domain adaptation. SemLA leverages a library of LoRA-based adapters indexed with CLIP embeddings, dynamically merging the most relevant adapters based on proximity to the target domain in the embedding space. This approach constructs an ad-hoc model tailored to each specific input without additional training. Our method scales efficiently, enhances explainability by tracking adapter contributions, and inherently protects data privacy, making it ideal for sensitive applications. Comprehensive experiments on a 20-domain benchmark built over 10 standard datasets demonstrate SemLA's superior adaptability and performance across diverse settings, establishing a new standard in domain adaptation for open-vocabulary semantic segmentation.
Are We Wasting Time? A Fast, Accurate Performance Evaluation Framework for Knowledge Graph Link Predictors
Jan 25, 2024The standard evaluation protocol for measuring the quality of Knowledge Graph Completion methods - the task of inferring new links to be added to a graph - typically involves a step which ranks every entity of a Knowledge Graph to assess their fit as a head or tail of a candidate link to be added. In Knowledge Graphs on a larger scale, this task rapidly becomes prohibitively heavy. Previous approaches mitigate this problem by using random sampling of entities to assess the quality of links predicted or suggested by a method. However, we show that this approach has serious limitations since the ranking metrics produced do not properly reflect true outcomes. In this paper, we present a thorough analysis of these effects along with the following findings. First, we empirically find and theoretically motivate why sampling uniformly at random vastly overestimates the ranking performance of a method. We show that this can be attributed to the effect of easy versus hard negative candidates. Second, we propose a framework that uses relational recommenders to guide the selection of candidates for evaluation. We provide both theoretical and empirical justification of our methodology, and find that simple and fast methods can work extremely well, and that they match advanced neural approaches. Even when a large portion of true candidates for a property are missed, the estimation barely deteriorates. With our proposed framework, we can reduce the time and computation needed similar to random sampling strategies while vastly improving the estimation; on ogbl-wikikg2, we show that accurate estimations of the full, filtered ranking can be obtained in 20 seconds instead of 30 minutes. We conclude that considerable computational effort can be saved by effective preprocessing and sampling methods and still reliably predict performance accurately of the true performance for the entire ranking procedure.
Cem Mil Podcasts: A Spoken Portuguese Document Corpus
Sep 23, 2022
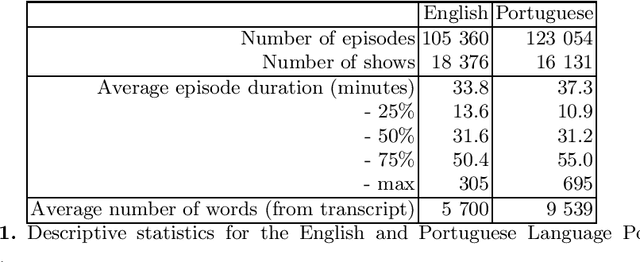
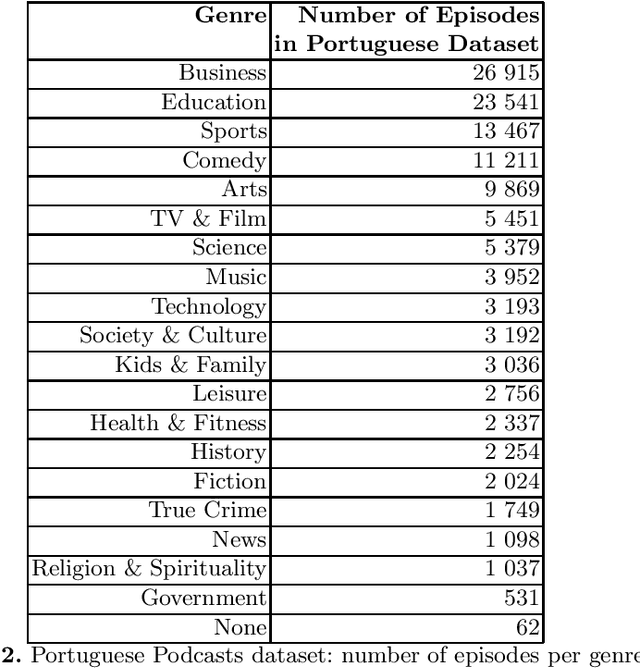
This document describes the Portuguese language podcast dataset released by Spotify for academic research purposes. We give an overview of how the data was sampled, some basic statistics over the collection, as well as brief information of distribution over Brazilian and Portuguese dialects.
Unsupervised Speaker Diarization that is Agnostic to Language, Overlap-Aware, and Tuning Free
Jul 25, 2022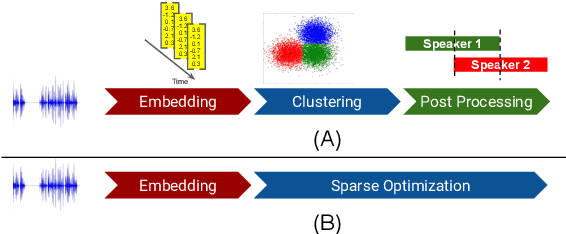
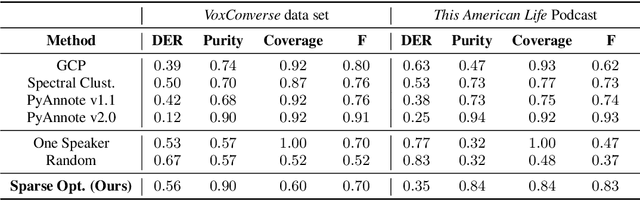
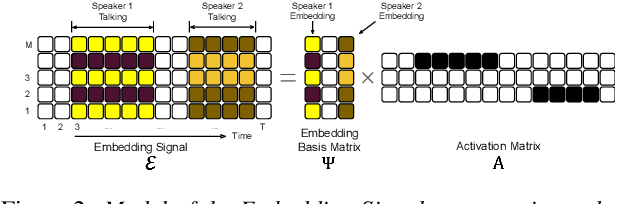
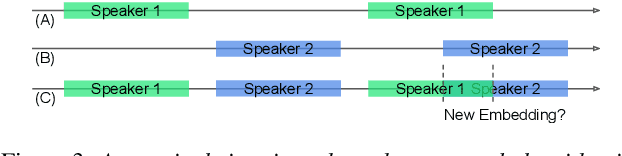
Podcasts are conversational in nature and speaker changes are frequent -- requiring speaker diarization for content understanding. We propose an unsupervised technique for speaker diarization without relying on language-specific components. The algorithm is overlap-aware and does not require information about the number of speakers. Our approach shows 79% improvement on purity scores (34% on F-score) against the Google Cloud Platform solution on podcast data.
Conventions and Mutual Expectations -- understanding sources for web genres
May 01, 2022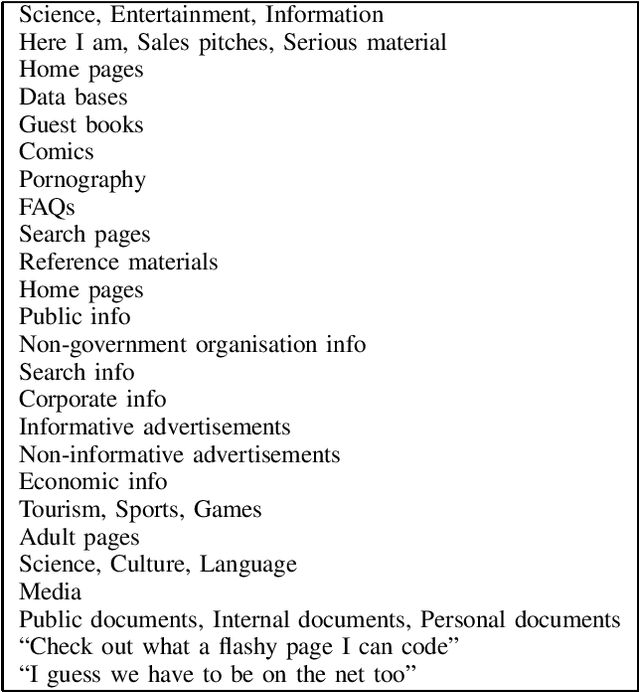

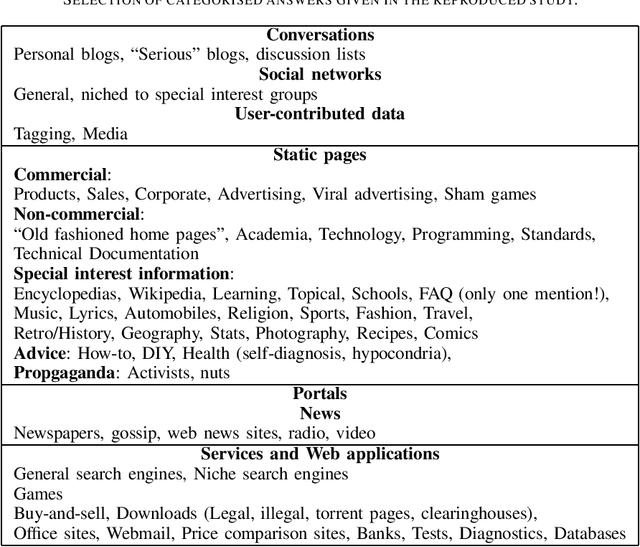
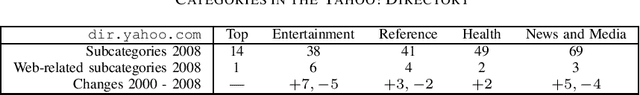
Genres can be understood in many different ways. They are often perceived as a primarily sociological construction, or, alternatively, as a stylostatistically observable objective characteristic of texts. The latter view is more common in the research field of information and language technology. These two views can be quite compatible and can inform each other; this present investigation discusses knowledge sources for studying genre variation and change by observing reader and author behaviour rather than performing analyses on the information objects themselves.
Textual Stylistic Variation: Choices, Genres and Individuals
May 01, 2022

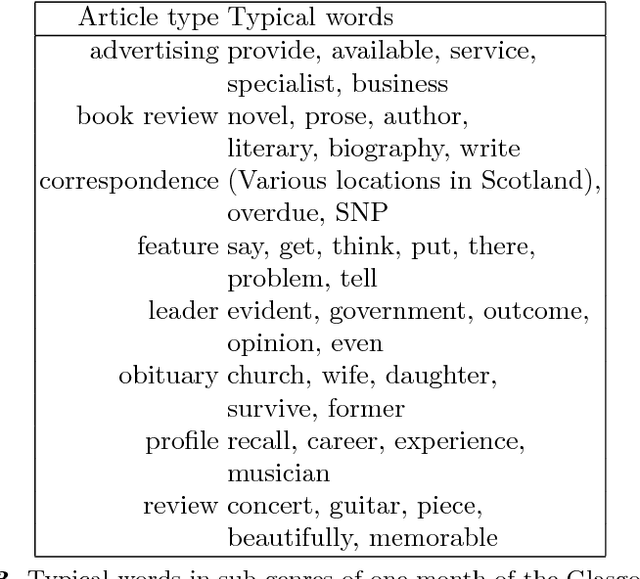

This chapter argues for more informed target metrics for the statistical processing of stylistic variation in text collections. Much as operationalised relevance proved a useful goal to strive for in information retrieval, research in textual stylistics, whether application oriented or philologically inclined, needs goals formulated in terms of pertinence, relevance, and utility - notions that agree with reader experience of text. Differences readers are aware of are mostly based on utility - not on textual characteristics per se. Mostly, readers report stylistic differences in terms of genres. Genres, while vague and undefined, are well-established and talked about: very early on, readers learn to distinguish genres. This chapter discusses variation given by genre, and contrasts it to variation occasioned by individual choice.
Podcast Metadata and Content: Episode Relevance andAttractiveness in Ad Hoc Search
Aug 25, 2021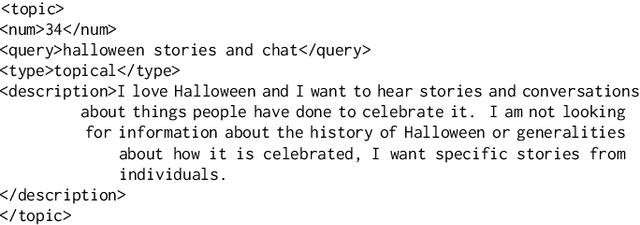

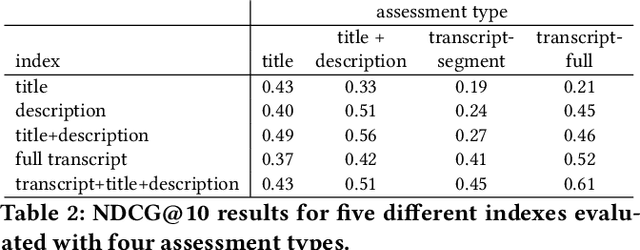
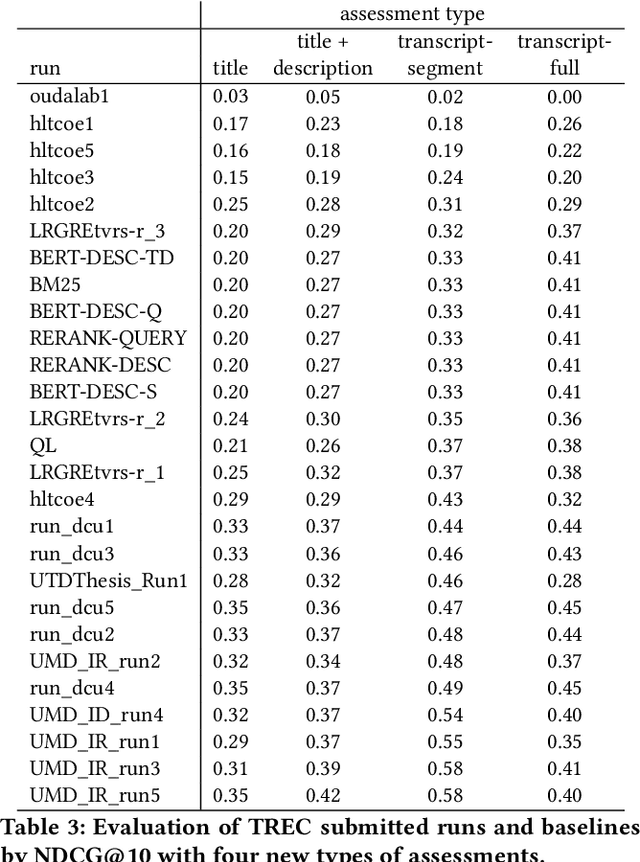
Rapidly growing online podcast archives contain diverse content on a wide range of topics. These archives form an important resource for entertainment and professional use, but their value can only be realized if users can rapidly and reliably locate content of interest. Search for relevant content can be based on metadata provided by content creators, but also on transcripts of the spoken content itself. Excavating relevant content from deep within these audio streams for diverse types of information needs requires varying the approach to systems prototyping. We describe a set of diverse podcast information needs and different approaches to assessing retrieved content for relevance. We use these information needs in an investigation of the utility and effectiveness of these information sources. Based on our analysis, we recommend approaches for indexing and retrieving podcast content for ad hoc search.
Current Challenges and Future Directions in Podcast Information Access
Jun 17, 2021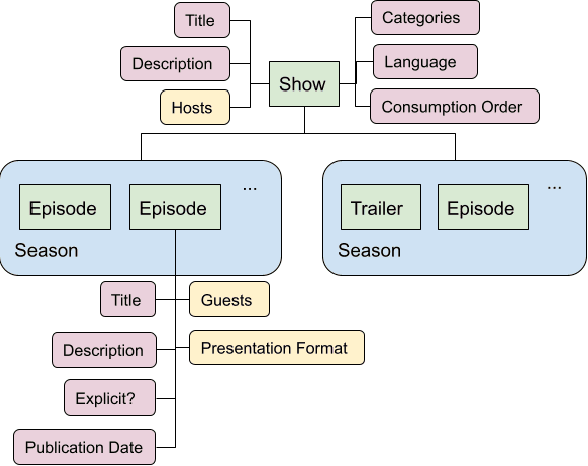
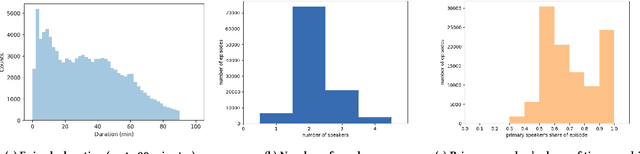
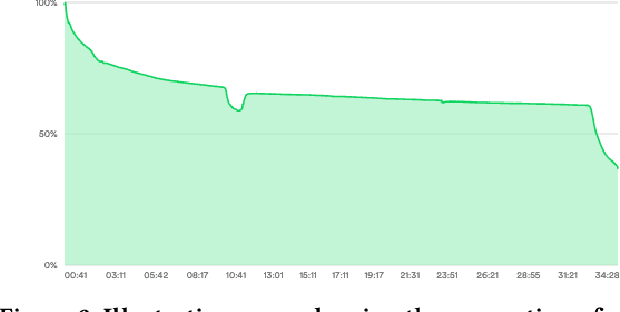
Podcasts are spoken documents across a wide-range of genres and styles, with growing listenership across the world, and a rapidly lowering barrier to entry for both listeners and creators. The great strides in search and recommendation in research and industry have yet to see impact in the podcast space, where recommendations are still largely driven by word of mouth. In this perspective paper, we highlight the many differences between podcasts and other media, and discuss our perspective on challenges and future research directions in the domain of podcast information access.
How Lexical Gold Standards Have Effects On The Usefulness Of Text Analysis Tools For Digital Scholarship
May 31, 2021
This paper describes how the current lexical similarity and analogy gold standards are built to conform to certain ideas about what the models they are designed to evaluate are used for. Topical relevance has always been the most important target notion for information access tools and related language technology technologies, and while this has proven a useful starting point for much of what information technology is used for, it does not always align well with other uses to which technologies are being put, most notably use cases from digital scholarship in the humanities or social sciences. This paper argues for more systematic formulation of requirements from the digital humanities and social sciences and more explicit description of the assumptions underlying model design.