Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Speaker Diarization that is Agnostic to Language, Overlap-Aware, and Tuning Free
Paper and Code
Jul 25, 2022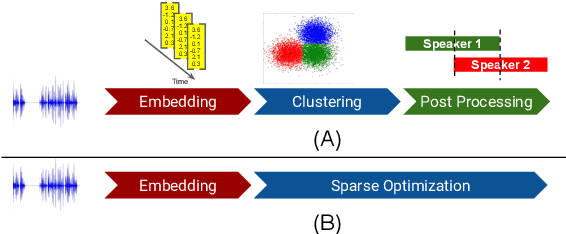
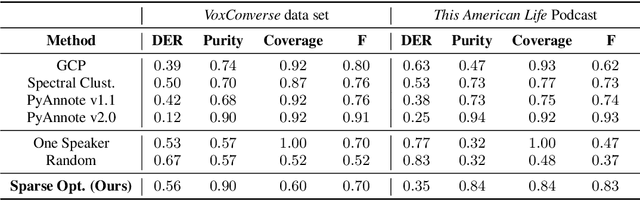
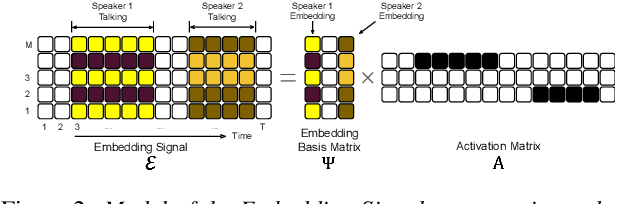
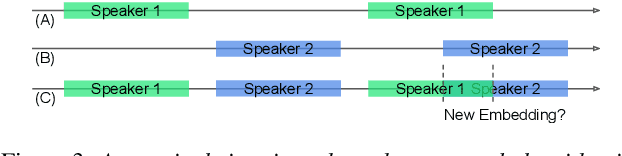
Podcasts are conversational in nature and speaker changes are frequent -- requiring speaker diarization for content understanding. We propose an unsupervised technique for speaker diarization without relying on language-specific components. The algorithm is overlap-aware and does not require information about the number of speakers. Our approach shows 79% improvement on purity scores (34% on F-score) against the Google Cloud Platform solution on podcast data.
* Published at Interspeech 2022
View paper on