 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShopping Queries Image Dataset (SQID): An Image-Enriched ESCI Dataset for Exploring Multimodal Learning in Product Search
May 24, 2024Recent advances in the fields of Information Retrieval and Machine Learning have focused on improving the performance of search engines to enhance the user experience, especially in the world of online shopping. The focus has thus been on leveraging cutting-edge learning techniques and relying on large enriched datasets. This paper introduces the Shopping Queries Image Dataset (SQID), an extension of the Amazon Shopping Queries Dataset enriched with image information associated with 190,000 products. By integrating visual information, SQID facilitates research around multimodal learning techniques that can take into account both textual and visual information for improving product search and ranking. We also provide experimental results leveraging SQID and pretrained models, showing the value of using multimodal data for search and ranking. SQID is available at: https://github.com/Crossing-Minds/shopping-queries-image-dataset.
Captions Are Worth a Thousand Words: Enhancing Product Retrieval with Pretrained Image-to-Text Models
Feb 13, 2024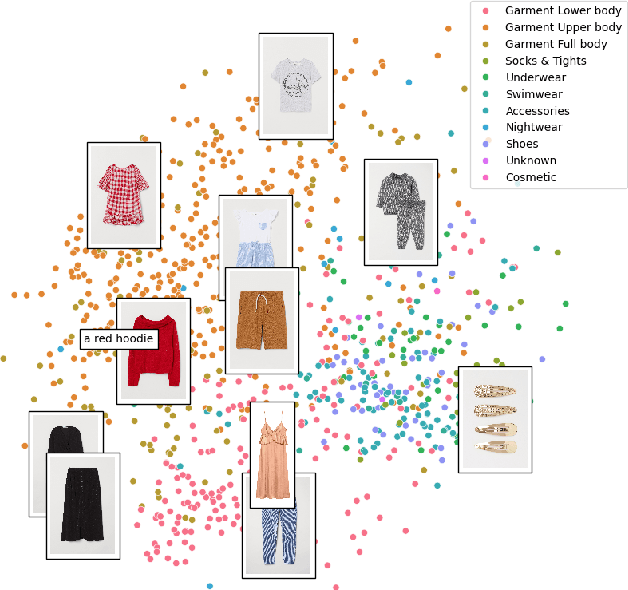

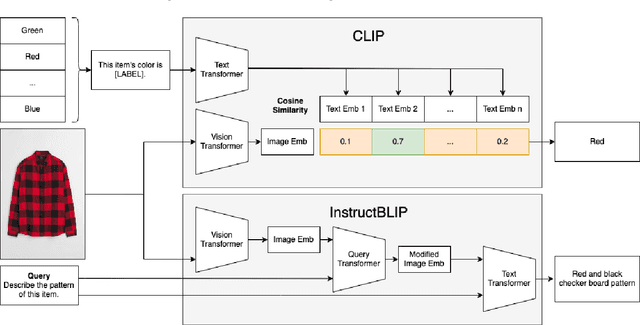

This paper explores the usage of multimodal image-to-text models to enhance text-based item retrieval. We propose utilizing pre-trained image captioning and tagging models, such as instructBLIP and CLIP, to generate text-based product descriptions which are combined with existing text descriptions. Our work is particularly impactful for smaller eCommerce businesses who are unable to maintain the high-quality text descriptions necessary to effectively perform item retrieval for search and recommendation use cases. We evaluate the searchability of ground-truth text, image-generated text, and combinations of both texts on several subsets of Amazon's publicly available ESCI dataset. The results demonstrate the dual capability of our proposed models to enhance the retrieval of existing text and generate highly-searchable standalone descriptions.
Current Challenges and Future Directions in Podcast Information Access
Jun 17, 2021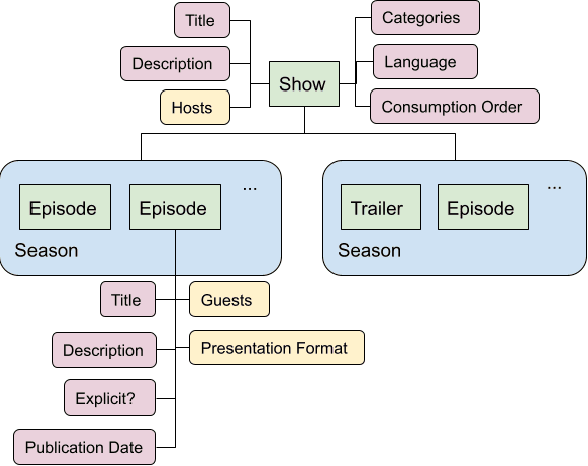
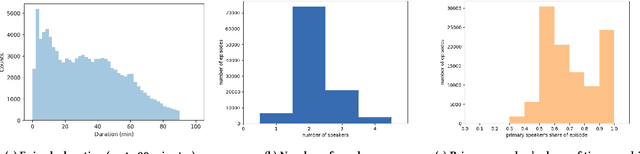
Podcasts are spoken documents across a wide-range of genres and styles, with growing listenership across the world, and a rapidly lowering barrier to entry for both listeners and creators. The great strides in search and recommendation in research and industry have yet to see impact in the podcast space, where recommendations are still largely driven by word of mouth. In this perspective paper, we highlight the many differences between podcasts and other media, and discuss our perspective on challenges and future research directions in the domain of podcast information access.
An Analysis of Approaches Taken in the ACM RecSys Challenge 2018 for Automatic Music Playlist Continuation
Oct 02, 2018
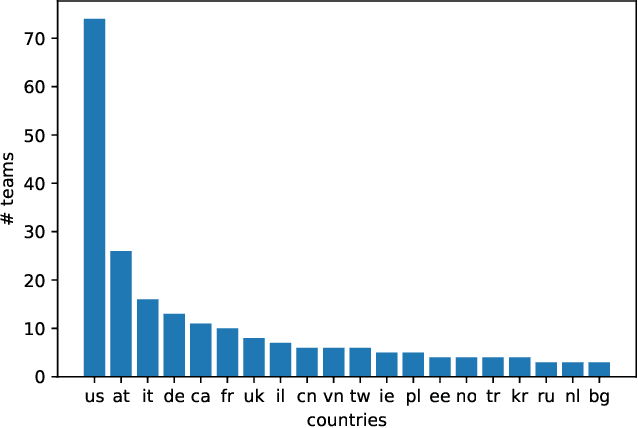
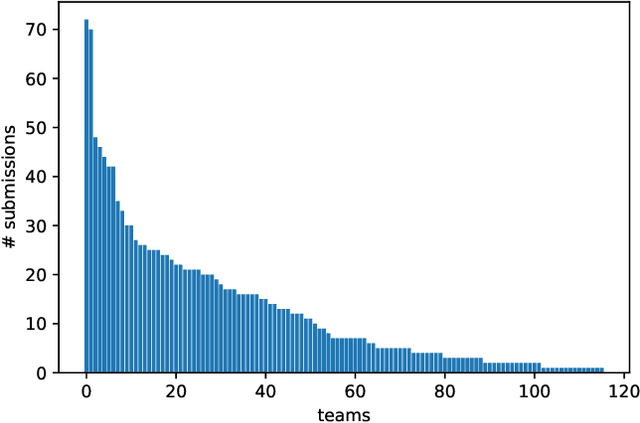

The ACM Recommender Systems Challenge 2018 focused on the task of automatic music playlist continuation, which is a form of the more general task of sequential recommendation. Given a playlist of arbitrary length with some additional meta-data, the task was to recommend up to 500 tracks that fit the target characteristics of the original playlist. For the RecSys Challenge, Spotify released a dataset of one million user-generated playlists. Participants could compete in two tracks, i.e., main and creative tracks. Participants in the main track were only allowed to use the provided training set, however, in the creative track, the use of external public sources was permitted. In total, 113 teams submitted 1,228 runs to the main track; 33 teams submitted 239 runs to the creative track. The highest performing team in the main track achieved an R-precision of 0.2241, an NDCG of 0.3946, and an average number of recommended songs clicks of 1.784. In the creative track, an R-precision of 0.2233, an NDCG of 0.3939, and a click rate of 1.785 was obtained by the best team. This article provides an overview of the challenge, including motivation, task definition, dataset description, and evaluation. We further report and analyze the results obtained by the top performing teams in each track and explore the approaches taken by the winners. We finally summarize our key findings and list the open avenues and possible future directions in the area of automatic playlist continuation.