 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePractical Bandits: An Industry Perspective
Feb 02, 2023The bandit paradigm provides a unified modeling framework for problems that require decision-making under uncertainty. Because many business metrics can be viewed as rewards (a.k.a. utilities) that result from actions, bandit algorithms have seen a large and growing interest from industrial applications, such as search, recommendation and advertising. Indeed, with the bandit lens comes the promise of direct optimisation for the metrics we care about. Nevertheless, the road to successfully applying bandits in production is not an easy one. Even when the action space and rewards are well-defined, practitioners still need to make decisions regarding multi-arm or contextual approaches, on- or off-policy setups, delayed or immediate feedback, myopic or long-term optimisation, etc. To make matters worse, industrial platforms typically give rise to large action spaces in which existing approaches tend to break down. The research literature on these topics is broad and vast, but this can overwhelm practitioners, whose primary aim is to solve practical problems, and therefore need to decide on a specific instantiation or approach for each project. This tutorial will take a step towards filling that gap between the theory and practice of bandits. Our goal is to present a unified overview of the field and its existing terminology, concepts and algorithms -- with a focus on problems relevant to industry. We hope our industrial perspective will help future practitioners who wish to leverage the bandit paradigm for their application.
Episodes Discovery Recommendation with Multi-Source Augmentations
Jan 17, 2023



Recommender systems (RS) commonly retrieve potential candidate items for users from a massive number of items by modeling user interests based on historical interactions. However, historical interaction data is highly sparse, and most items are long-tail items, which limits the representation learning for item discovery. This problem is further augmented by the discovery of novel or cold-start items. For example, after a user displays interest in bitcoin financial investment shows in the podcast space, a recommender system may want to suggest, e.g., a newly released blockchain episode from a more technical show. Episode correlations help the discovery, especially when interaction data of episodes is limited. Accordingly, we build upon the classical Two-Tower model and introduce the novel Multi-Source Augmentations using a Contrastive Learning framework (MSACL) to enhance episode embedding learning by incorporating positive episodes from numerous correlated semantics. Extensive experiments on a real-world podcast recommendation dataset from a large audio streaming platform demonstrate the effectiveness of the proposed framework for user podcast exploration and cold-start episode recommendation.
Sequential Recommendation via Stochastic Self-Attention
Jan 16, 2022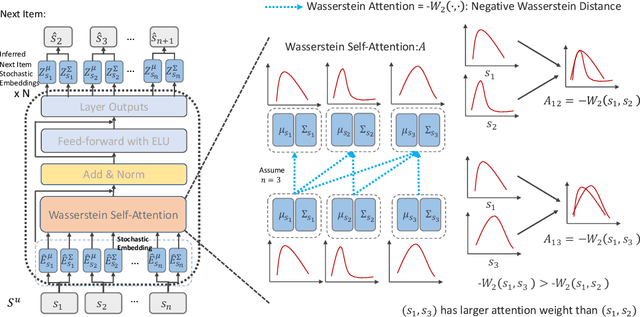
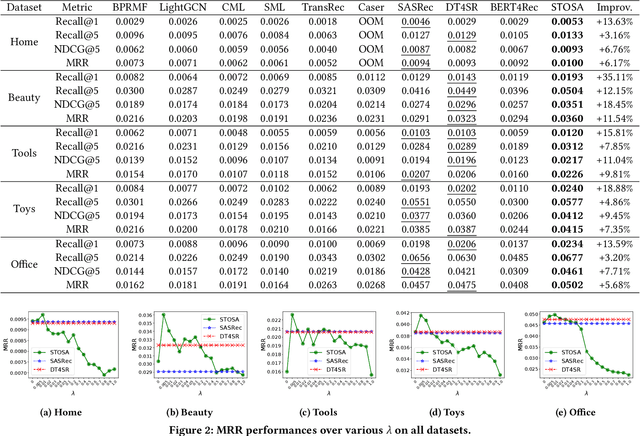
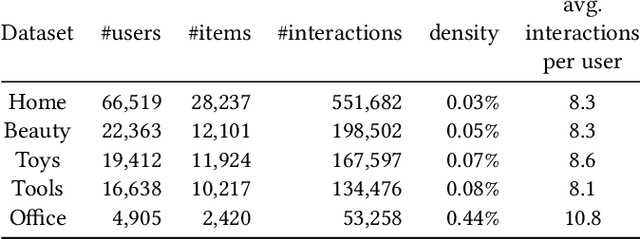

Sequential recommendation models the dynamics of a user's previous behaviors in order to forecast the next item, and has drawn a lot of attention. Transformer-based approaches, which embed items as vectors and use dot-product self-attention to measure the relationship between items, demonstrate superior capabilities among existing sequential methods. However, users' real-world sequential behaviors are \textit{\textbf{uncertain}} rather than deterministic, posing a significant challenge to present techniques. We further suggest that dot-product-based approaches cannot fully capture \textit{\textbf{collaborative transitivity}}, which can be derived in item-item transitions inside sequences and is beneficial for cold start items. We further argue that BPR loss has no constraint on positive and sampled negative items, which misleads the optimization. We propose a novel \textbf{STO}chastic \textbf{S}elf-\textbf{A}ttention~(STOSA) to overcome these issues. STOSA, in particular, embeds each item as a stochastic Gaussian distribution, the covariance of which encodes the uncertainty. We devise a novel Wasserstein Self-Attention module to characterize item-item position-wise relationships in sequences, which effectively incorporates uncertainty into model training. Wasserstein attentions also enlighten the collaborative transitivity learning as it satisfies triangle inequality. Moreover, we introduce a novel regularization term to the ranking loss, which assures the dissimilarity between positive and the negative items. Extensive experiments on five real-world benchmark datasets demonstrate the superiority of the proposed model over state-of-the-art baselines, especially on cold start items. The code is available in \url{https://github.com/zfan20/STOSA}.
Current Challenges and Future Directions in Podcast Information Access
Jun 17, 2021
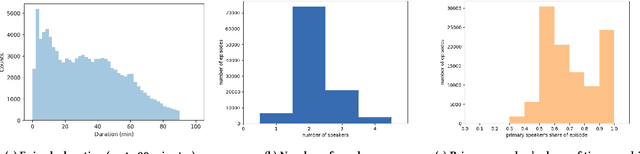
Podcasts are spoken documents across a wide-range of genres and styles, with growing listenership across the world, and a rapidly lowering barrier to entry for both listeners and creators. The great strides in search and recommendation in research and industry have yet to see impact in the podcast space, where recommendations are still largely driven by word of mouth. In this perspective paper, we highlight the many differences between podcasts and other media, and discuss our perspective on challenges and future research directions in the domain of podcast information access.
Recommending Podcasts for Cold-Start Users Based on Music Listening and Taste
Jul 27, 2020
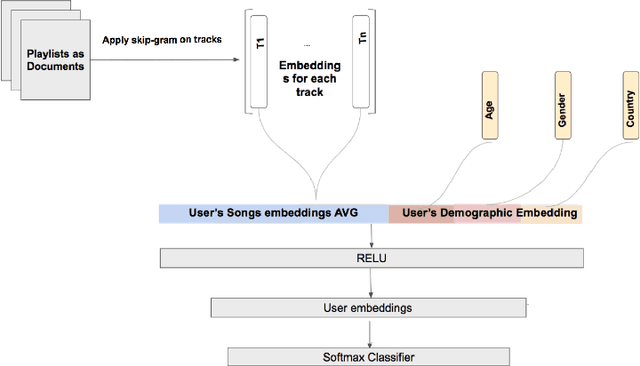

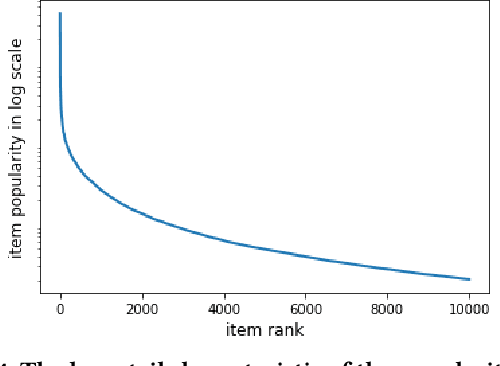
Recommender systems are increasingly used to predict and serve content that aligns with user taste, yet the task of matching new users with relevant content remains a challenge. We consider podcasting to be an emerging medium with rapid growth in adoption, and discuss challenges that arise when applying traditional recommendation approaches to address the cold-start problem. Using music consumption behavior, we examine two main techniques in inferring Spotify users preferences over more than 200k podcasts. Our results show significant improvements in consumption of up to 50\% for both offline and online experiments. We provide extensive analysis on model performance and examine the degree to which music data as an input source introduces bias in recommendations.
The Engagement-Diversity Connection: Evidence from a Field Experiment on Spotify
Mar 17, 2020
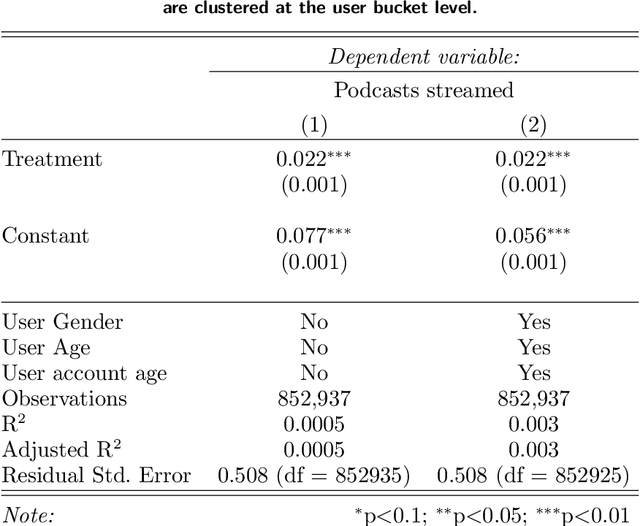
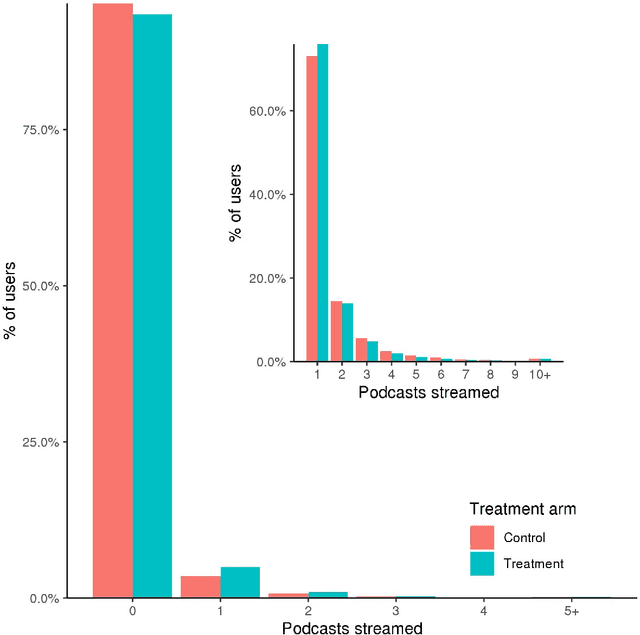
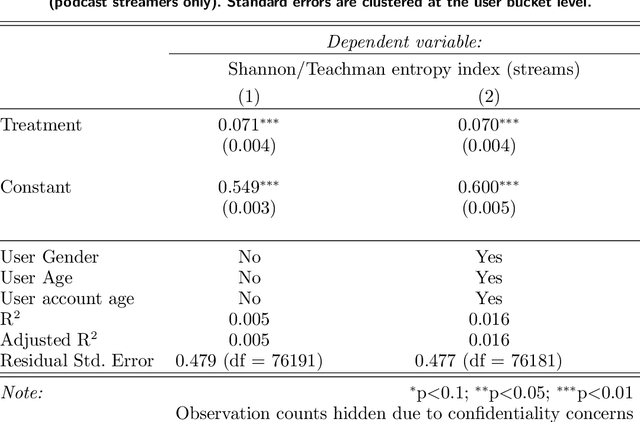
It remains unknown whether personalized recommendations increase or decrease the diversity of content people consume. We present results from a randomized field experiment on Spotify testing the effect of personalized recommendations on consumption diversity. In the experiment, both control and treatment users were given podcast recommendations, with the sole aim of increasing podcast consumption. Treatment users' recommendations were personalized based on their music listening history, whereas control users were recommended popular podcasts among users in their demographic group. We find that, on average, the treatment increased podcast streams by 28.90%. However, the treatment also decreased the average individual-level diversity of podcast streams by 11.51%, and increased the aggregate diversity of podcast streams by 5.96%, indicating that personalized recommendations have the potential to create patterns of consumption that are homogenous within and diverse across users, a pattern reflecting Balkanization. Our results provide evidence of an "engagement-diversity trade-off" when recommendations are optimized solely to drive consumption: while personalized recommendations increase user engagement, they also affect the diversity of consumed content. This shift in consumption diversity can affect user retention and lifetime value, and impact the optimal strategy for content producers. We also observe evidence that our treatment affected streams from sections of Spotify's app not directly affected by the experiment, suggesting that exposure to personalized recommendations can affect the content that users consume organically. We believe these findings highlight the need for academics and practitioners to continue investing in personalization methods that explicitly take into account the diversity of content recommended.