 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQini curve estimation under clustered network interference
Feb 27, 2025



Qini curves are a widely used tool for assessing treatment policies under allocation constraints as they visualize the incremental gain of a new treatment policy versus the cost of its implementation. Standard Qini curve estimation assumes no interference between units: that is, that treating one unit does not influence the outcome of any other unit. In many real-life applications such as public policy or marketing, however, the presence of interference is common. Ignoring interference in these scenarios can lead to systematically biased Qini curves that over- or under-estimate a treatment policy's cost-effectiveness. In this paper, we address the problem of Qini curve estimation under clustered network interference, where interfering units form independent clusters. We propose a formal description of the problem setting with an experimental study design under which we can account for clustered network interference. Within this framework, we introduce three different estimation strategies suited for different conditions. Moreover, we introduce a marketplace simulator that emulates clustered network interference in a typical e-commerce setting. From both theoretical and empirical insights, we provide recommendations in choosing the best estimation strategy by identifying an inherent bias-variance trade-off among the estimation strategies.
Rethinking Knowledge Transfer in Learning Using Privileged Information
Aug 26, 2024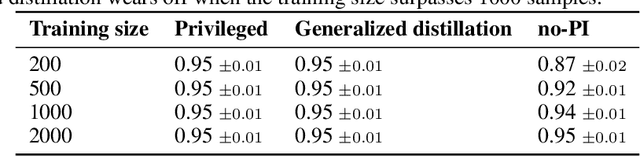
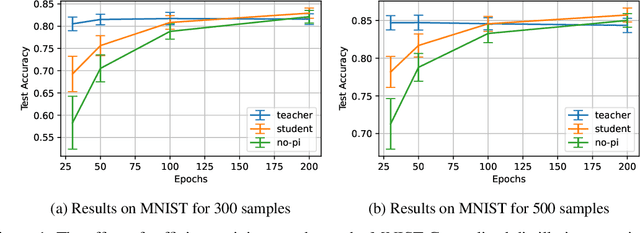
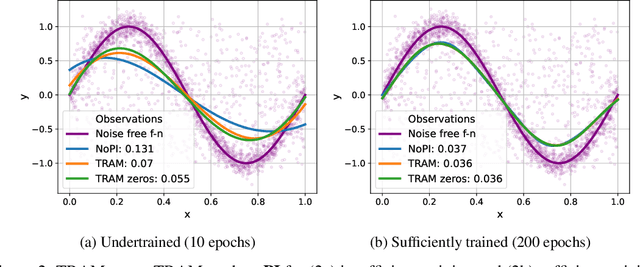
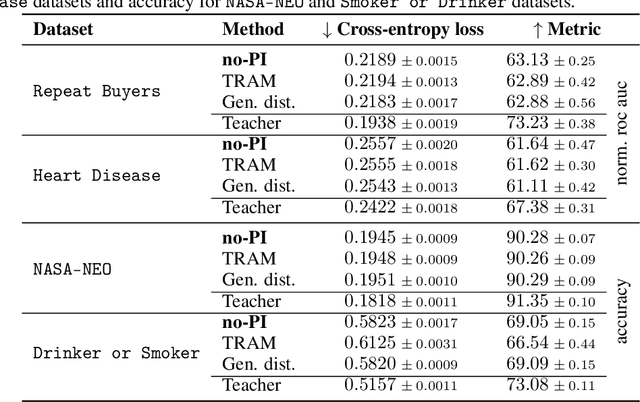
In supervised machine learning, privileged information (PI) is information that is unavailable at inference, but is accessible during training time. Research on learning using privileged information (LUPI) aims to transfer the knowledge captured in PI onto a model that can perform inference without PI. It seems that this extra bit of information ought to make the resulting model better. However, finding conclusive theoretical or empirical evidence that supports the ability to transfer knowledge using PI has been challenging. In this paper, we critically examine the assumptions underlying existing theoretical analyses and argue that there is little theoretical justification for when LUPI should work. We analyze LUPI methods and reveal that apparent improvements in empirical risk of existing research may not directly result from PI. Instead, these improvements often stem from dataset anomalies or modifications in model design misguidedly attributed to PI. Our experiments for a wide variety of application domains further demonstrate that state-of-the-art LUPI approaches fail to effectively transfer knowledge from PI. Thus, we advocate for practitioners to exercise caution when working with PI to avoid unintended inductive biases.
Practical Bandits: An Industry Perspective
Feb 02, 2023The bandit paradigm provides a unified modeling framework for problems that require decision-making under uncertainty. Because many business metrics can be viewed as rewards (a.k.a. utilities) that result from actions, bandit algorithms have seen a large and growing interest from industrial applications, such as search, recommendation and advertising. Indeed, with the bandit lens comes the promise of direct optimisation for the metrics we care about. Nevertheless, the road to successfully applying bandits in production is not an easy one. Even when the action space and rewards are well-defined, practitioners still need to make decisions regarding multi-arm or contextual approaches, on- or off-policy setups, delayed or immediate feedback, myopic or long-term optimisation, etc. To make matters worse, industrial platforms typically give rise to large action spaces in which existing approaches tend to break down. The research literature on these topics is broad and vast, but this can overwhelm practitioners, whose primary aim is to solve practical problems, and therefore need to decide on a specific instantiation or approach for each project. This tutorial will take a step towards filling that gap between the theory and practice of bandits. Our goal is to present a unified overview of the field and its existing terminology, concepts and algorithms -- with a focus on problems relevant to industry. We hope our industrial perspective will help future practitioners who wish to leverage the bandit paradigm for their application.
Extending Open Bandit Pipeline to Simulate Industry Challenges
Sep 09, 2022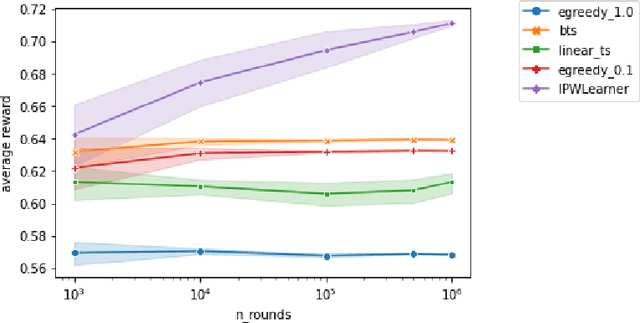
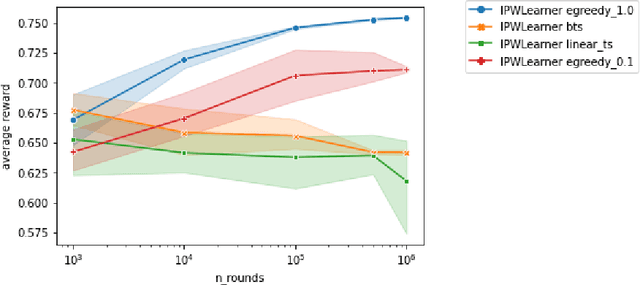
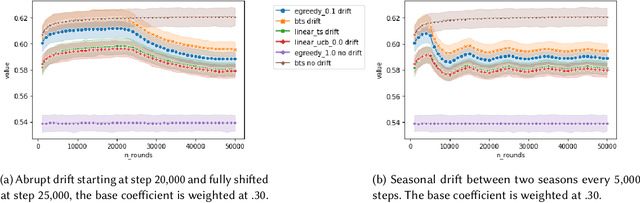
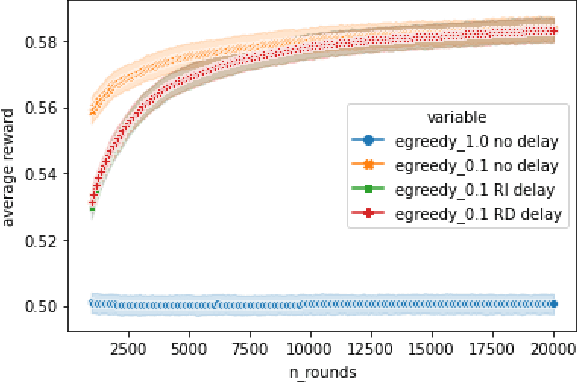
Bandit algorithms are often used in the e-commerce industry to train Machine Learning (ML) systems when pre-labeled data is unavailable. However, the industry setting poses various challenges that make implementing bandit algorithms in practice non-trivial. In this paper, we elaborate on the challenges of off-policy optimisation, delayed reward, concept drift, reward design, and business rules constraints that practitioners at Booking.com encounter when applying bandit algorithms. Our main contributions is an extension to the Open Bandit Pipeline (OBP) framework. We provide simulation components for some of the above-mentioned challenges to provide future practitioners, researchers, and educators with a resource to address challenges encountered in the e-commerce industry.
Machine Learning for Fraud Detection in E-Commerce: A Research Agenda
Jul 05, 2021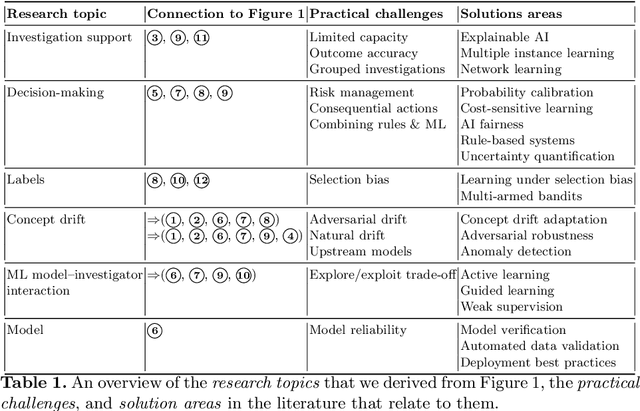
Fraud detection and prevention play an important part in ensuring the sustained operation of any e-commerce business. Machine learning (ML) often plays an important role in these anti-fraud operations, but the organizational context in which these ML models operate cannot be ignored. In this paper, we take an organization-centric view on the topic of fraud detection by formulating an operational model of the anti-fraud departments in e-commerce organizations. We derive 6 research topics and 12 practical challenges for fraud detection from this operational model. We summarize the state of the literature for each research topic, discuss potential solutions to the practical challenges, and identify 22 open research challenges.