 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQini curve estimation under clustered network interference
Feb 27, 2025



Qini curves are a widely used tool for assessing treatment policies under allocation constraints as they visualize the incremental gain of a new treatment policy versus the cost of its implementation. Standard Qini curve estimation assumes no interference between units: that is, that treating one unit does not influence the outcome of any other unit. In many real-life applications such as public policy or marketing, however, the presence of interference is common. Ignoring interference in these scenarios can lead to systematically biased Qini curves that over- or under-estimate a treatment policy's cost-effectiveness. In this paper, we address the problem of Qini curve estimation under clustered network interference, where interfering units form independent clusters. We propose a formal description of the problem setting with an experimental study design under which we can account for clustered network interference. Within this framework, we introduce three different estimation strategies suited for different conditions. Moreover, we introduce a marketplace simulator that emulates clustered network interference in a typical e-commerce setting. From both theoretical and empirical insights, we provide recommendations in choosing the best estimation strategy by identifying an inherent bias-variance trade-off among the estimation strategies.
Discovering outstanding subgroup lists for numeric targets using MDL
Jun 16, 2020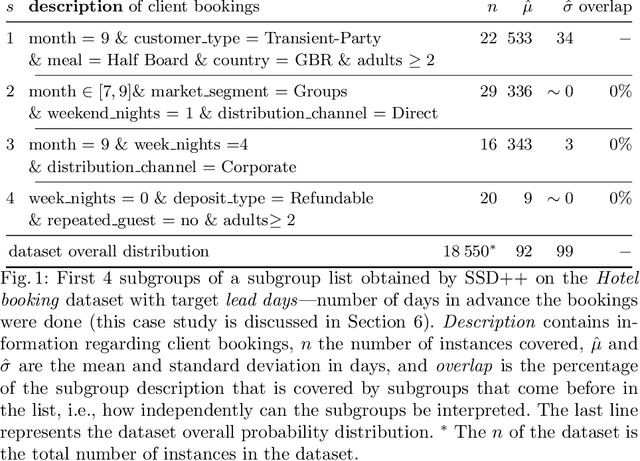
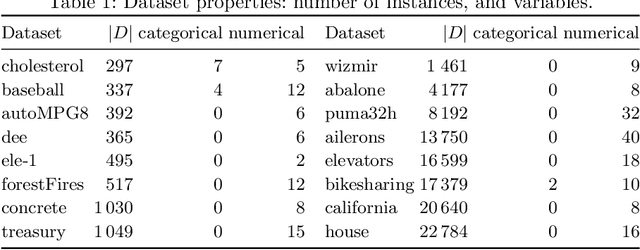
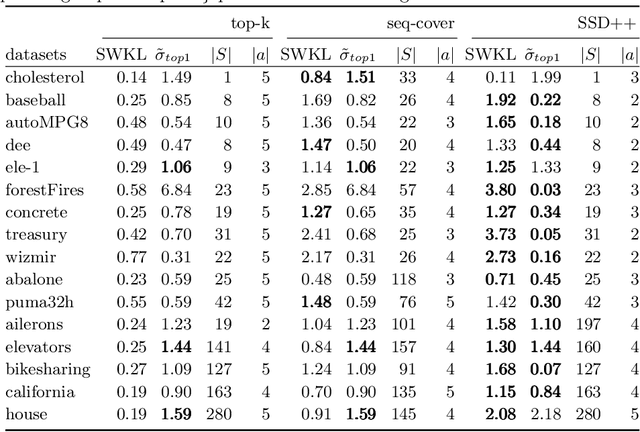
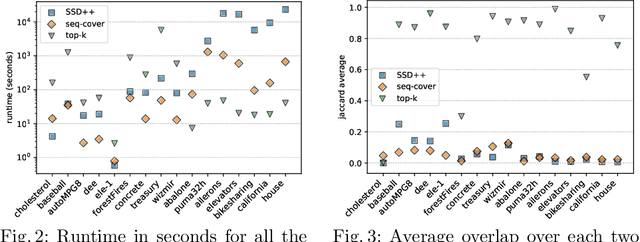
The task of subgroup discovery (SD) is to find interpretable descriptions of subsets of a dataset that stand out with respect to a target attribute. To address the problem of mining large numbers of redundant subgroups, subgroup set discovery (SSD) has been proposed. State-of-the-art SSD methods have their limitations though, as they typically heavily rely on heuristics and/or user-chosen hyperparameters. We propose a dispersion-aware problem formulation for subgroup set discovery that is based on the minimum description length (MDL) principle and subgroup lists. We argue that the best subgroup list is the one that best summarizes the data given the overall distribution of the target. We restrict our focus to a single numeric target variable and show that our formalization coincides with an existing quality measure when finding a single subgroup, but that-in addition-it allows to trade off subgroup quality with the complexity of the subgroup. We next propose SSD++, a heuristic algorithm for which we empirically demonstrate that it returns outstanding subgroup lists: non-redundant sets of compact subgroups that stand out by having strongly deviating means and small spread.
Interpretable multiclass classification by MDL-based rule lists
May 01, 2019



Interpretable classifiers have recently witnessed an increase in attention from the data mining community because they are inherently easier to understand and explain than their more complex counterparts. Examples of interpretable classification models include decision trees, rule sets, and rule lists. Learning such models often involves optimizing hyperparameters, which typically requires substantial amounts of data and may result in relatively large models. In this paper, we consider the problem of learning compact yet accurate probabilistic rule lists for multiclass classification. Specifically, we propose a novel formalization based on probabilistic rule lists and the minimum description length (MDL) principle. This results in virtually parameter-free model selection that naturally allows to trade-off model complexity with goodness of fit, by which overfitting and the need for hyperparameter tuning are effectively avoided. Finally, we introduce the Classy algorithm, which greedily finds rule lists according to the proposed criterion. We empirically demonstrate that Classy selects small probabilistic rule lists that outperform state-of-the-art classifiers when it comes to the combination of predictive performance and interpretability. We show that Classy is insensitive to its only parameter, i.e., the candidate set, and that compression on the training set correlates with classification performance, validating our MDL-based selection criterion.