 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQini curve estimation under clustered network interference
Feb 27, 2025



Qini curves are a widely used tool for assessing treatment policies under allocation constraints as they visualize the incremental gain of a new treatment policy versus the cost of its implementation. Standard Qini curve estimation assumes no interference between units: that is, that treating one unit does not influence the outcome of any other unit. In many real-life applications such as public policy or marketing, however, the presence of interference is common. Ignoring interference in these scenarios can lead to systematically biased Qini curves that over- or under-estimate a treatment policy's cost-effectiveness. In this paper, we address the problem of Qini curve estimation under clustered network interference, where interfering units form independent clusters. We propose a formal description of the problem setting with an experimental study design under which we can account for clustered network interference. Within this framework, we introduce three different estimation strategies suited for different conditions. Moreover, we introduce a marketplace simulator that emulates clustered network interference in a typical e-commerce setting. From both theoretical and empirical insights, we provide recommendations in choosing the best estimation strategy by identifying an inherent bias-variance trade-off among the estimation strategies.
Falsification of Unconfoundedness by Testing Independence of Causal Mechanisms
Feb 10, 2025A major challenge in estimating treatment effects in observational studies is the reliance on untestable conditions such as the assumption of no unmeasured confounding. In this work, we propose an algorithm that can falsify the assumption of no unmeasured confounding in a setting with observational data from multiple heterogeneous sources, which we refer to as environments. Our proposed falsification strategy leverages a key observation that unmeasured confounding can cause observed causal mechanisms to appear dependent. Building on this observation, we develop a novel two-stage procedure that detects these dependencies with high statistical power while controlling false positives. The algorithm does not require access to randomized data and, in contrast to other falsification approaches, functions even under transportability violations when the environment has a direct effect on the outcome of interest. To showcase the practical relevance of our approach, we show that our method is able to efficiently detect confounding on both simulated and real-world data.
Combining observational datasets from multiple environments to detect hidden confounding
May 27, 2022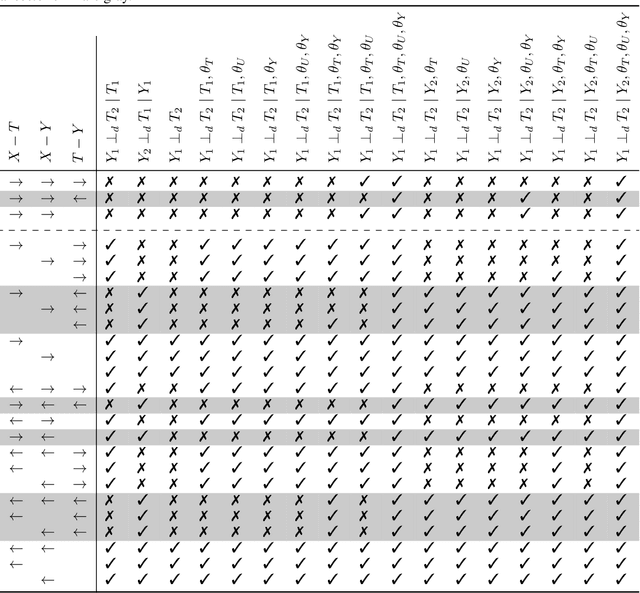
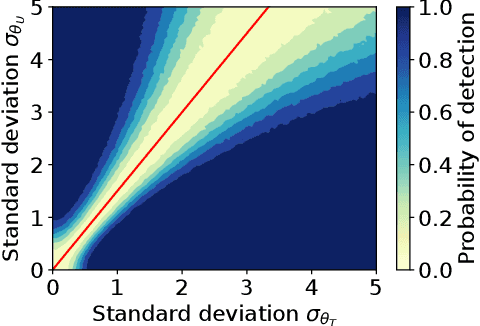
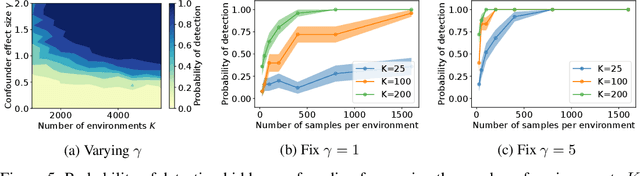
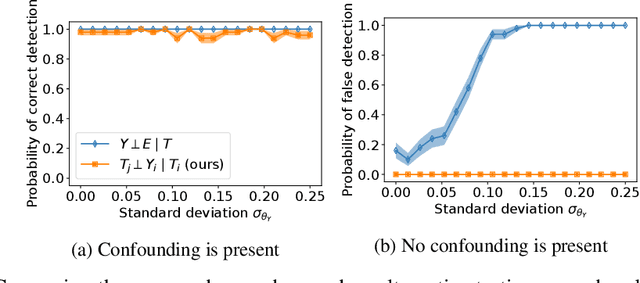
A common assumption in causal inference from observational data is the assumption of no hidden confounding. Yet it is, in general, impossible to verify the presence of hidden confounding factors from a single dataset. However, under the assumption of independent causal mechanisms underlying the data generative process, we demonstrate a way to detect unobserved confounders when having multiple observational datasets coming from different environments. We present a theory for testable conditional independencies that are only violated during hidden confounding and examine cases where we break its assumptions: degenerate & dependent mechanisms, and faithfulness violations. Additionally, we propose a procedure to test these independencies and study its empirical finite-sample behavior using simulation studies.