 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Topological Method for Comparing Document Semantics
Dec 08, 2020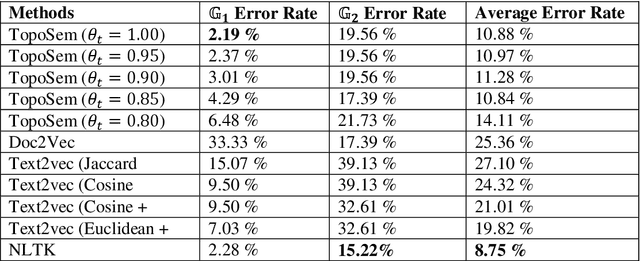
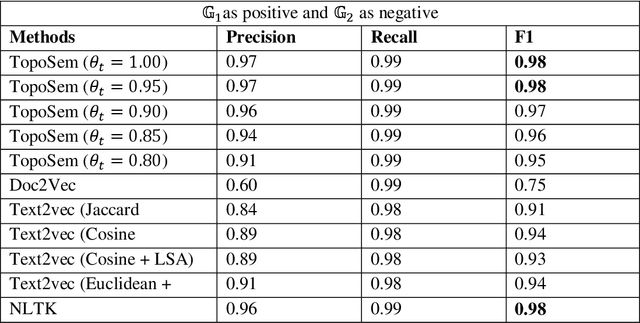
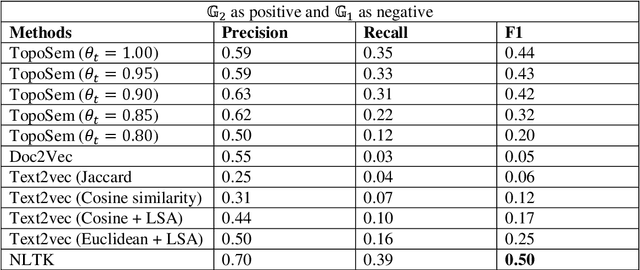
Comparing document semantics is one of the toughest tasks in both Natural Language Processing and Information Retrieval. To date, on one hand, the tools for this task are still rare. On the other hand, most relevant methods are devised from the statistic or the vector space model perspectives but nearly none from a topological perspective. In this paper, we hope to make a different sound. A novel algorithm based on topological persistence for comparing semantics similarity between two documents is proposed. Our experiments are conducted on a document dataset with human judges' results. A collection of state-of-the-art methods are selected for comparison. The experimental results show that our algorithm can produce highly human-consistent results, and also beats most state-of-the-art methods though ties with NLTK.
* 9 pages, 3 tables, 9th International Conference on Natural Language Processing (NLP 2020)
Methods for Individual Treatment Assignment: An Application and Comparison for Playlist Generation
May 09, 2020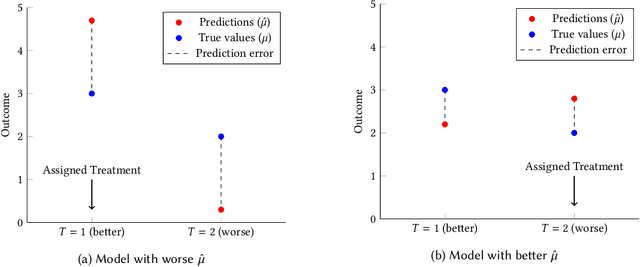

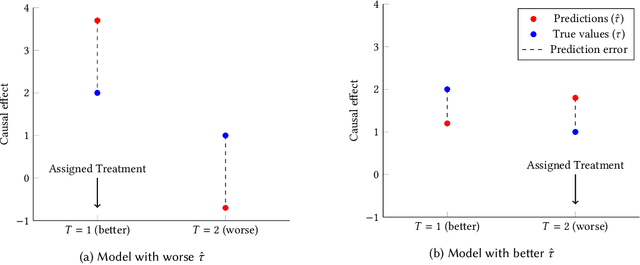

We present a systematic analysis of causal treatment assignment decision making, a general problem that arises in many applications and has received significant attention from economists, computer scientists, and social scientists. We focus on choosing, for each user, the best algorithm for playlist generation in order to optimize engagement. We characterize the various methods proposed in the literature into three general approaches: learning models to predict outcomes, learning models to predict causal effects, and learning models to predict optimal treatment assignments. We show analytically that optimizing for outcome or causal-effect prediction is not the same as optimizing for treatment assignments, and thus we should prefer learning models that optimize for treatment assignments. For our playlist generation application, we compare and contrast the three approaches empirically. This is the first comparison of the different treatment assignment approaches on a real-world application at scale (based on more than half a billion individual treatment assignments). Our results show (i) that applying different algorithms to different users can improve streams substantially compared to deploying the same algorithm for everyone, (ii) that personalized assignments improve substantially with larger data sets, and (iii) that learning models by optimizing treatment assignments rather than outcome or causal-effect predictions can improve treatment assignment performance by more than 28%.
The Engagement-Diversity Connection: Evidence from a Field Experiment on Spotify
Mar 17, 2020
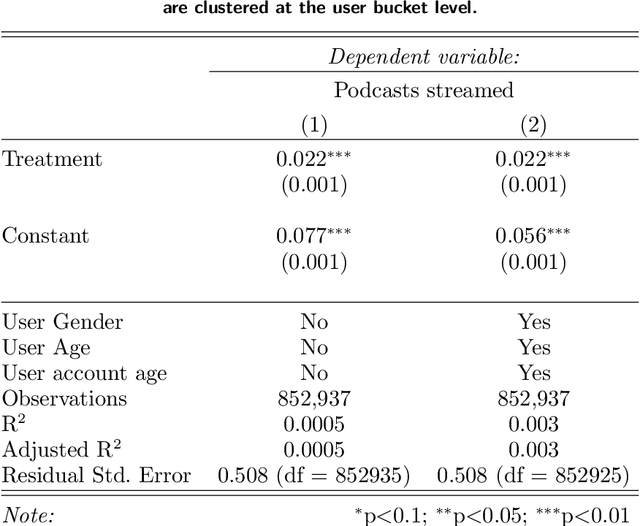
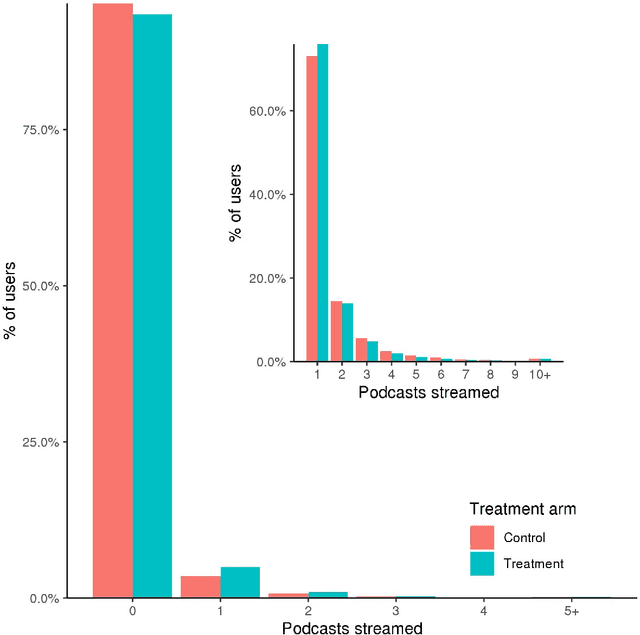
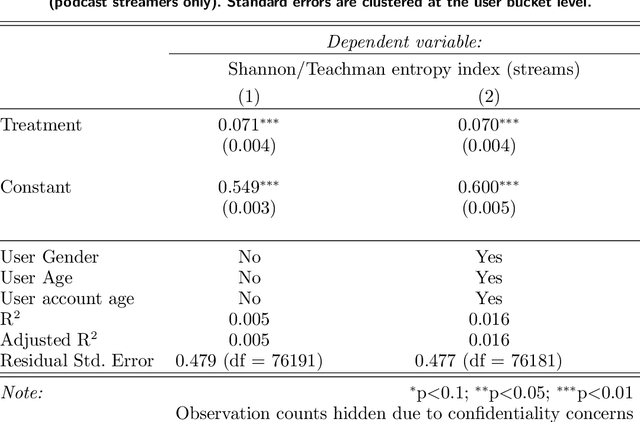
It remains unknown whether personalized recommendations increase or decrease the diversity of content people consume. We present results from a randomized field experiment on Spotify testing the effect of personalized recommendations on consumption diversity. In the experiment, both control and treatment users were given podcast recommendations, with the sole aim of increasing podcast consumption. Treatment users' recommendations were personalized based on their music listening history, whereas control users were recommended popular podcasts among users in their demographic group. We find that, on average, the treatment increased podcast streams by 28.90%. However, the treatment also decreased the average individual-level diversity of podcast streams by 11.51%, and increased the aggregate diversity of podcast streams by 5.96%, indicating that personalized recommendations have the potential to create patterns of consumption that are homogenous within and diverse across users, a pattern reflecting Balkanization. Our results provide evidence of an "engagement-diversity trade-off" when recommendations are optimized solely to drive consumption: while personalized recommendations increase user engagement, they also affect the diversity of consumed content. This shift in consumption diversity can affect user retention and lifetime value, and impact the optimal strategy for content producers. We also observe evidence that our treatment affected streams from sections of Spotify's app not directly affected by the experiment, suggesting that exposure to personalized recommendations can affect the content that users consume organically. We believe these findings highlight the need for academics and practitioners to continue investing in personalization methods that explicitly take into account the diversity of content recommended.