 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMethods for Individual Treatment Assignment: An Application and Comparison for Playlist Generation
Paper and Code
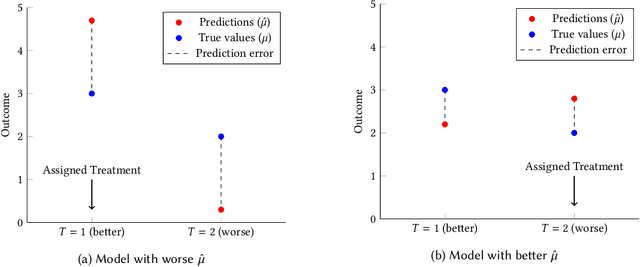

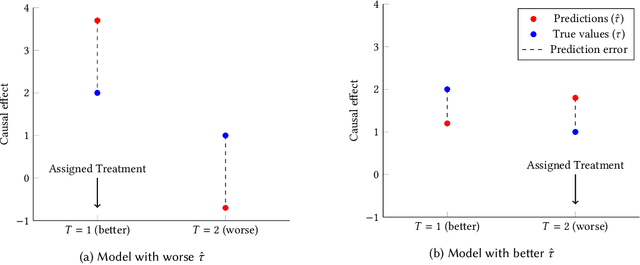

We present a systematic analysis of causal treatment assignment decision making, a general problem that arises in many applications and has received significant attention from economists, computer scientists, and social scientists. We focus on choosing, for each user, the best algorithm for playlist generation in order to optimize engagement. We characterize the various methods proposed in the literature into three general approaches: learning models to predict outcomes, learning models to predict causal effects, and learning models to predict optimal treatment assignments. We show analytically that optimizing for outcome or causal-effect prediction is not the same as optimizing for treatment assignments, and thus we should prefer learning models that optimize for treatment assignments. For our playlist generation application, we compare and contrast the three approaches empirically. This is the first comparison of the different treatment assignment approaches on a real-world application at scale (based on more than half a billion individual treatment assignments). Our results show (i) that applying different algorithms to different users can improve streams substantially compared to deploying the same algorithm for everyone, (ii) that personalized assignments improve substantially with larger data sets, and (iii) that learning models by optimizing treatment assignments rather than outcome or causal-effect predictions can improve treatment assignment performance by more than 28%.