 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStratified Graph Spectra
Jan 10, 2022



In classic graph signal processing, given a real-valued graph signal, its graph Fourier transform is typically defined as the series of inner products between the signal and each eigenvector of the graph Laplacian. Unfortunately, this definition is not mathematically valid in the cases of vector-valued graph signals which however are typical operands in the state-of-the-art graph learning modeling and analyses. Seeking a generalized transformation decoding the magnitudes of eigencomponents from vector-valued signals is thus the main objective of this paper. Several attempts are explored, and also it is found that performing the transformation at hierarchical levels of adjacency help profile the spectral characteristics of signals more insightfully. The proposed methods are introduced as a new tool assisting on diagnosing and profiling behaviors of graph learning models.
A Topological Approach to Compare Document Semantics Based on a New Variant of Syntactic N-grams
Mar 08, 2021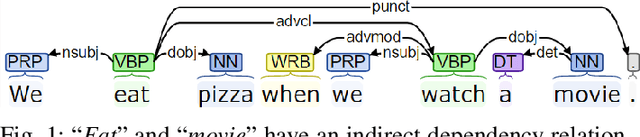
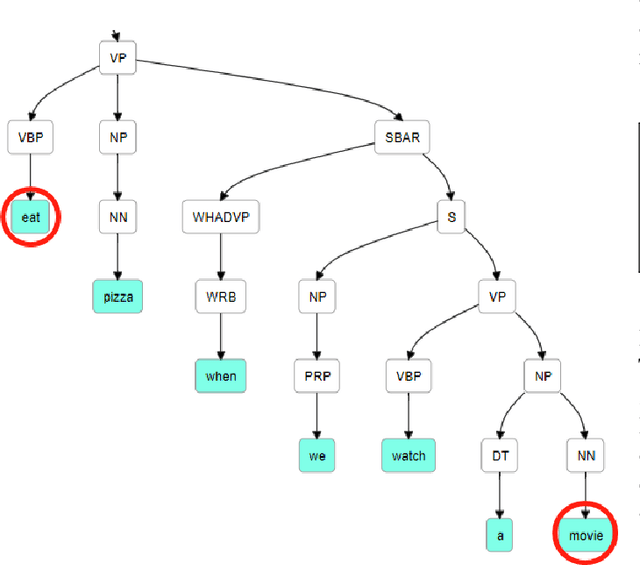

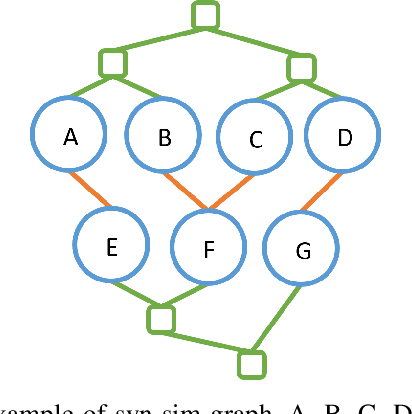
This paper delivers a new perspective of thinking and utilizing syntactic n-grams (sn-grams). Sn-grams are a type of non-linear n-grams which have been playing a critical role in many NLP tasks. Introducing sn-grams to comparing document semantics thus is an appealing application, and few studies have reported progress at this. However, when proceeding on this application, we found three major issues of sn-grams: lack of significance, being sensitive to word orders and failing on capture indirect syntactic relations. To address these issues, we propose a new variant of sn-grams named generalized phrases (GPs). Then based on GPs we propose a topological approach, named DSCoH, to compute document semantic similarities. DSCoH has been extensively tested on the document semantics comparison and the document clustering tasks. The experimental results show that DSCoH can outperform state-of-the-art embedding-based methods.
A Topological Method for Comparing Document Semantics
Dec 08, 2020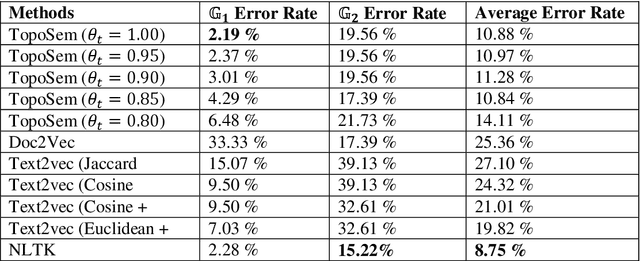
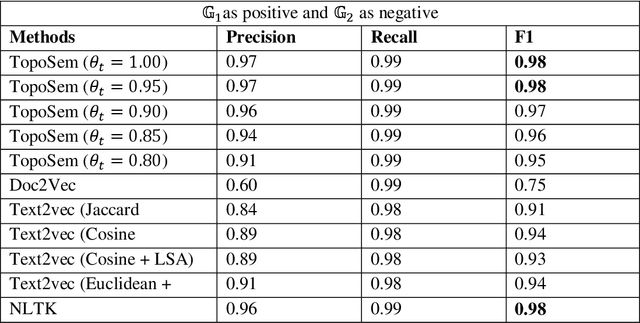
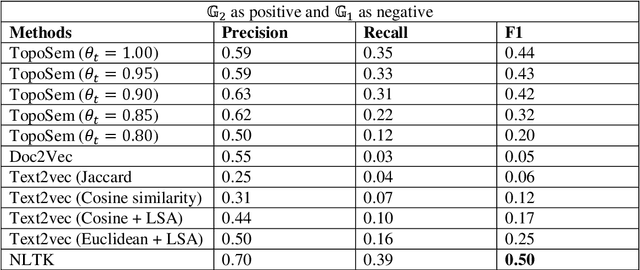
Comparing document semantics is one of the toughest tasks in both Natural Language Processing and Information Retrieval. To date, on one hand, the tools for this task are still rare. On the other hand, most relevant methods are devised from the statistic or the vector space model perspectives but nearly none from a topological perspective. In this paper, we hope to make a different sound. A novel algorithm based on topological persistence for comparing semantics similarity between two documents is proposed. Our experiments are conducted on a document dataset with human judges' results. A collection of state-of-the-art methods are selected for comparison. The experimental results show that our algorithm can produce highly human-consistent results, and also beats most state-of-the-art methods though ties with NLTK.
* 9 pages, 3 tables, 9th International Conference on Natural Language Processing (NLP 2020)