 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCaptions Are Worth a Thousand Words: Enhancing Product Retrieval with Pretrained Image-to-Text Models
Paper and Code
Feb 13, 2024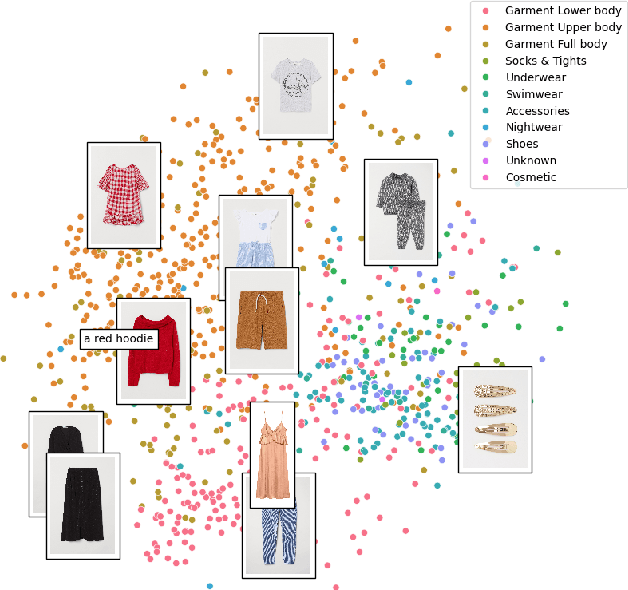

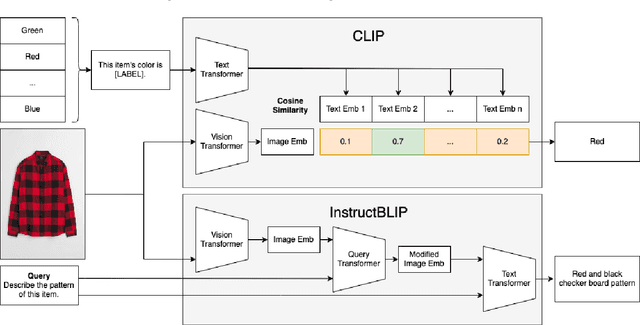

This paper explores the usage of multimodal image-to-text models to enhance text-based item retrieval. We propose utilizing pre-trained image captioning and tagging models, such as instructBLIP and CLIP, to generate text-based product descriptions which are combined with existing text descriptions. Our work is particularly impactful for smaller eCommerce businesses who are unable to maintain the high-quality text descriptions necessary to effectively perform item retrieval for search and recommendation use cases. We evaluate the searchability of ground-truth text, image-generated text, and combinations of both texts on several subsets of Amazon's publicly available ESCI dataset. The results demonstrate the dual capability of our proposed models to enhance the retrieval of existing text and generate highly-searchable standalone descriptions.