 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRAGSys: Item-Cold-Start Recommender as RAG System
May 27, 2024


Large Language Models (LLM) hold immense promise for real-world applications, but their generic knowledge often falls short of domain-specific needs. Fine-tuning, a common approach, can suffer from catastrophic forgetting and hinder generalizability. In-Context Learning (ICL) offers an alternative, which can leverage Retrieval-Augmented Generation (RAG) to provide LLMs with relevant demonstrations for few-shot learning tasks. This paper explores the desired qualities of a demonstration retrieval system for ICL. We argue that ICL retrieval in this context resembles item-cold-start recommender systems, prioritizing discovery and maximizing information gain over strict relevance. We propose a novel evaluation method that measures the LLM's subsequent performance on NLP tasks, eliminating the need for subjective diversity scores. Our findings demonstrate the critical role of diversity and quality bias in retrieved demonstrations for effective ICL, and highlight the potential of recommender system techniques in this domain.
Captions Are Worth a Thousand Words: Enhancing Product Retrieval with Pretrained Image-to-Text Models
Feb 13, 2024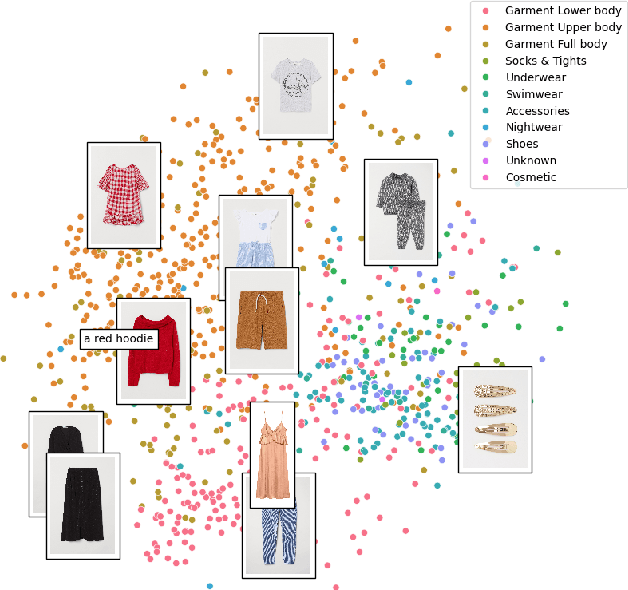

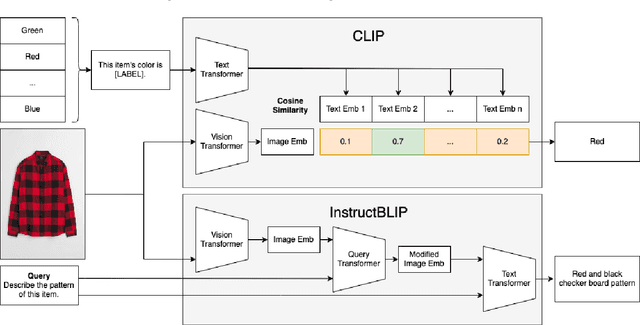

This paper explores the usage of multimodal image-to-text models to enhance text-based item retrieval. We propose utilizing pre-trained image captioning and tagging models, such as instructBLIP and CLIP, to generate text-based product descriptions which are combined with existing text descriptions. Our work is particularly impactful for smaller eCommerce businesses who are unable to maintain the high-quality text descriptions necessary to effectively perform item retrieval for search and recommendation use cases. We evaluate the searchability of ground-truth text, image-generated text, and combinations of both texts on several subsets of Amazon's publicly available ESCI dataset. The results demonstrate the dual capability of our proposed models to enhance the retrieval of existing text and generate highly-searchable standalone descriptions.