 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDemographic Biases and Gaps in the Perception of Sexism in Large Language Models
Aug 25, 2025



The use of Large Language Models (LLMs) has proven to be a tool that could help in the automatic detection of sexism. Previous studies have shown that these models contain biases that do not accurately reflect reality, especially for minority groups. Despite various efforts to improve the detection of sexist content, this task remains a significant challenge due to its subjective nature and the biases present in automated models. We explore the capabilities of different LLMs to detect sexism in social media text using the EXIST 2024 tweet dataset. It includes annotations from six distinct profiles for each tweet, allowing us to evaluate to what extent LLMs can mimic these groups' perceptions in sexism detection. Additionally, we analyze the demographic biases present in the models and conduct a statistical analysis to identify which demographic characteristics (age, gender) contribute most effectively to this task. Our results show that, while LLMs can to some extent detect sexism when considering the overall opinion of populations, they do not accurately replicate the diversity of perceptions among different demographic groups. This highlights the need for better-calibrated models that account for the diversity of perspectives across different populations.
SemEval-2025 Task 3: Mu-SHROOM, the Multilingual Shared Task on Hallucinations and Related Observable Overgeneration Mistakes
Apr 16, 2025We present the Mu-SHROOM shared task which is focused on detecting hallucinations and other overgeneration mistakes in the output of instruction-tuned large language models (LLMs). Mu-SHROOM addresses general-purpose LLMs in 14 languages, and frames the hallucination detection problem as a span-labeling task. We received 2,618 submissions from 43 participating teams employing diverse methodologies. The large number of submissions underscores the interest of the community in hallucination detection. We present the results of the participating systems and conduct an empirical analysis to identify key factors contributing to strong performance in this task. We also emphasize relevant current challenges, notably the varying degree of hallucinations across languages and the high annotator disagreement when labeling hallucination spans.
DAIC-WOZ: On the Validity of Using the Therapist's prompts in Automatic Depression Detection from Clinical Interviews
Apr 22, 2024



Automatic depression detection from conversational data has gained significant interest in recent years. The DAIC-WOZ dataset, interviews conducted by a human-controlled virtual agent, has been widely used for this task. Recent studies have reported enhanced performance when incorporating interviewer's prompts into the model. In this work, we hypothesize that this improvement might be mainly due to a bias present in these prompts, rather than the proposed architectures and methods. Through ablation experiments and qualitative analysis, we discover that models using interviewer's prompts learn to focus on a specific region of the interviews, where questions about past experiences with mental health issues are asked, and use them as discriminative shortcuts to detect depressed participants. In contrast, models using participant responses gather evidence from across the entire interview. Finally, to highlight the magnitude of this bias, we achieve a 0.90 F1 score by intentionally exploiting it, the highest result reported to date on this dataset using only textual information. Our findings underline the need for caution when incorporating interviewers' prompts into models, as they may inadvertently learn to exploit targeted prompts, rather than learning to characterize the language and behavior that are genuinely indicative of the patient's mental health condition.
Adaptive Cross-lingual Text Classification through In-Context One-Shot Demonstrations
Apr 03, 2024Zero-Shot Cross-lingual Transfer (ZS-XLT) utilizes a model trained in a source language to make predictions in another language, often with a performance loss. To alleviate this, additional improvements can be achieved through subsequent adaptation using examples in the target language. In this paper, we exploit In-Context Tuning (ICT) for One-Shot Cross-lingual transfer in the classification task by introducing In-Context Cross-lingual Transfer (IC-XLT). The novel concept involves training a model to learn from context examples and subsequently adapting it during inference to a target language by prepending a One-Shot context demonstration in that language. Our results show that IC-XLT successfully leverages target-language examples to improve the cross-lingual capabilities of the evaluated mT5 model, outperforming prompt-based models in the Zero and Few-shot scenarios adapted through fine-tuning. Moreover, we show that when source-language data is limited, the fine-tuning framework employed for IC-XLT performs comparably to prompt-based fine-tuning with significantly more training data in the source language.
A visual approach for age and gender identification on Twitter
May 28, 2018
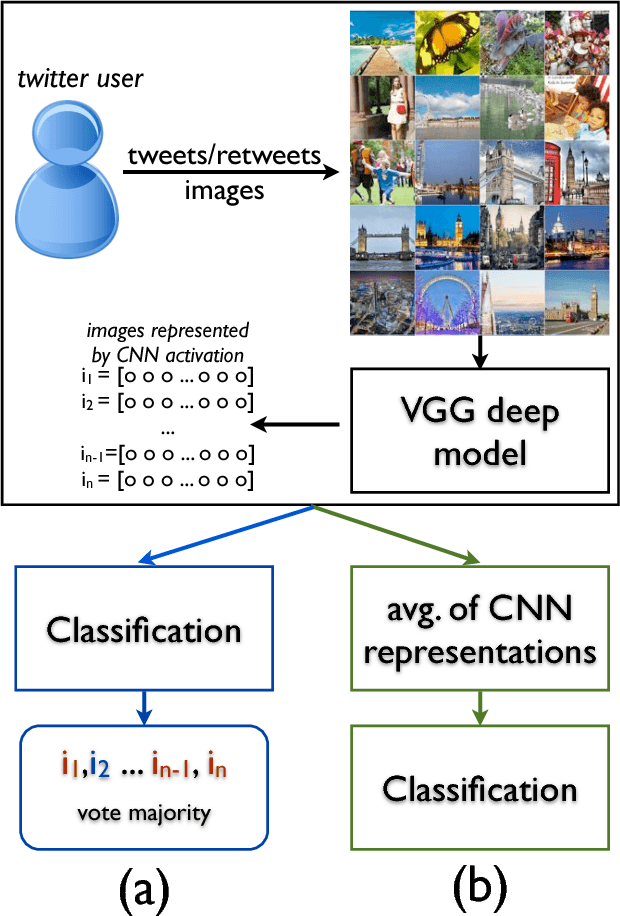
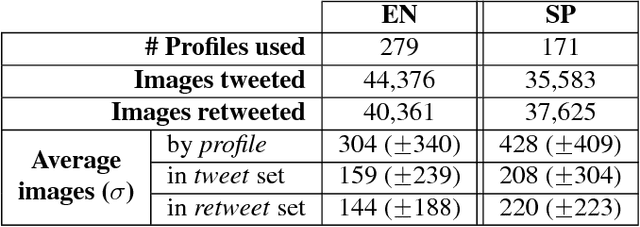

The goal of Author Profiling (AP) is to identify demographic aspects (e.g., age, gender) from a given set of authors by analyzing their written texts. Recently, the AP task has gained interest in many problems related to computer forensics, psychology, marketing, but specially in those related with social media exploitation. As known, social media data is shared through a wide range of modalities (e.g., text, images and audio), representing valuable information to be exploited for extracting valuable insights from users. Nevertheless, most of the current work in AP using social media data has been devoted to analyze textual information only, and there are very few works that have started exploring the gender identification using visual information. Contrastingly, this paper focuses in exploiting the visual modality to perform both age and gender identification in social media, specifically in Twitter. Our goal is to evaluate the pertinence of using visual information in solving the AP task. Accordingly, we have extended the Twitter corpus from PAN 2014, incorporating posted images from all the users, making a distinction between tweeted and retweeted images. Performed experiments provide interesting evidence on the usefulness of visual information in comparison with traditional textual representations for the AP task.