 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAU-NN: ANFIS Unit Neural Network
Apr 21, 2022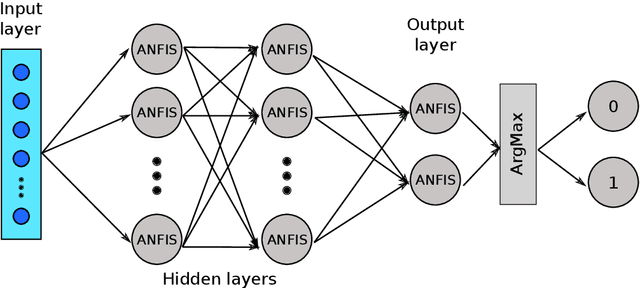
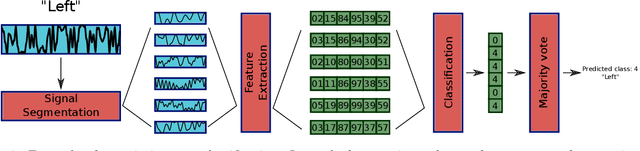
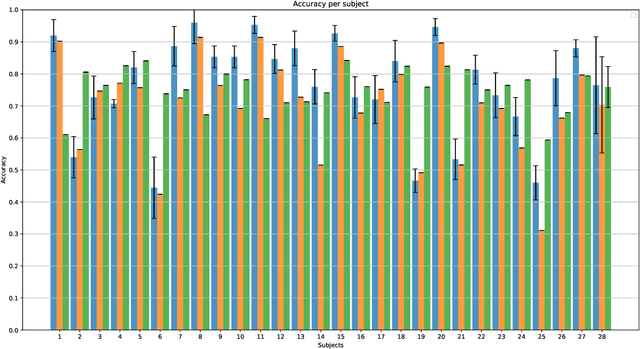
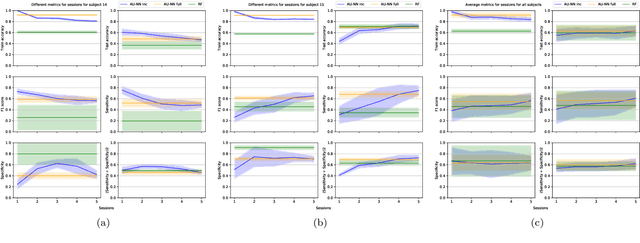
In this paper is described the ANFIS Unit Neural Network, a deep neural network where each neuron is an independent ANFIS. Two use cases of this network are shown to test the capability of the network. (i) Classification of five imagined words. (ii) Incremental learning in the task of detecting Imagined Word Segments vs. Idle State Segments. In both cases, the proposed network outperforms the conventional methods. Additionally, is described a process of classification where instead of taking the whole instance as one example, each instance is decomposed into a set of smaller instances, and the classification is done by a majority vote over all the predictions of the set. The codes to build the AU-NN used in this paper, are available on the github repository https://github.com/tonahdztoro/AU_NN.
Toward asynchronous EEG-based BCI: Detecting imagined words segments in continuous EEG signals
Apr 13, 2021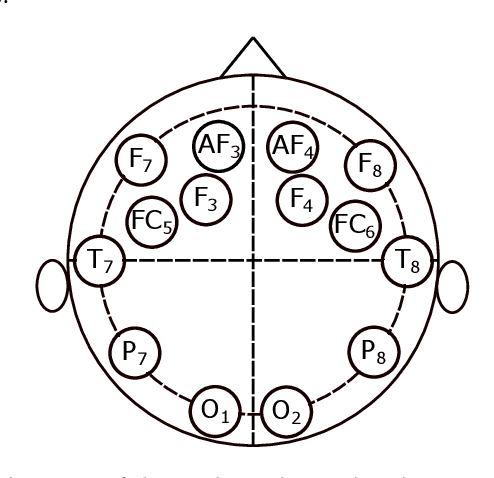

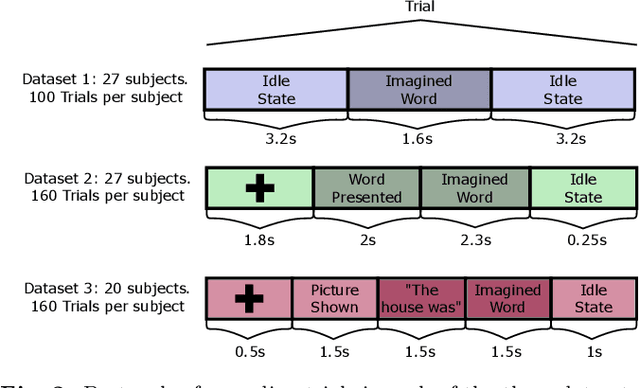

An asynchronous Brain--Computer Interface (BCI) based on imagined speech is a tool that allows to control an external device or to emit a message at the moment the user desires to by decoding EEG signals of imagined speech. In order to correctly implement these types of BCI, we must be able to detect from a continuous signal, when the subject starts to imagine words. In this work, five methods of feature extraction based on wavelet decomposition, empirical mode decomposition, frequency energies, fractal dimension and chaos theory features are presented to solve the task of detecting imagined words segments from continuous EEG signals as a preliminary study for a latter implementation of an asynchronous BCI based on imagined speech. These methods are tested in three datasets using four different classifiers and the higher F1 scores obtained are 0.73, 0.79, and 0.68 for each dataset, respectively. This results are promising to build a system that automatizes the segmentation of imagined words segments for latter classification.
* 10 pages, 14 figures
Semantically-informed distance and similarity measures for paraphrase plagiarism identification
May 29, 2018

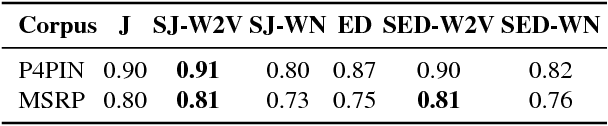
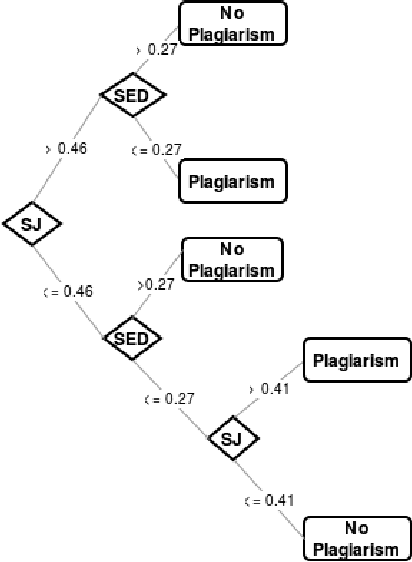
Paraphrase plagiarism identification represents a very complex task given that plagiarized texts are intentionally modified through several rewording techniques. Accordingly, this paper introduces two new measures for evaluating the relatedness of two given texts: a semantically-informed similarity measure and a semantically-informed edit distance. Both measures are able to extract semantic information from either an external resource or a distributed representation of words, resulting in informative features for training a supervised classifier for detecting paraphrase plagiarism. Obtained results indicate that the proposed metrics are consistently good in detecting different types of paraphrase plagiarism. In addition, results are very competitive against state-of-the art methods having the advantage of representing a much more simple but equally effective solution.
A visual approach for age and gender identification on Twitter
May 28, 2018
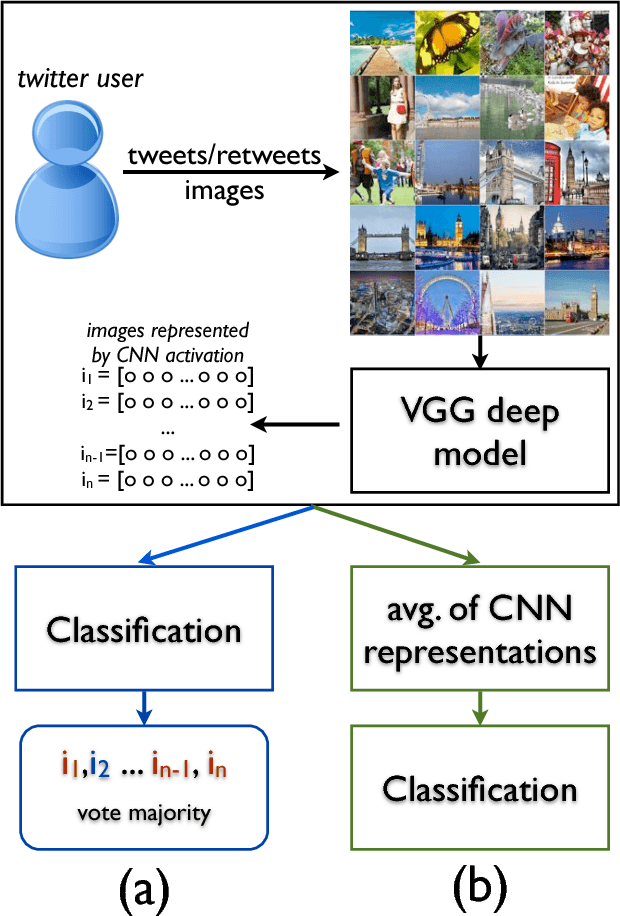
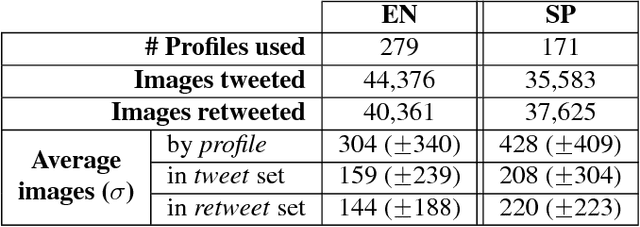

The goal of Author Profiling (AP) is to identify demographic aspects (e.g., age, gender) from a given set of authors by analyzing their written texts. Recently, the AP task has gained interest in many problems related to computer forensics, psychology, marketing, but specially in those related with social media exploitation. As known, social media data is shared through a wide range of modalities (e.g., text, images and audio), representing valuable information to be exploited for extracting valuable insights from users. Nevertheless, most of the current work in AP using social media data has been devoted to analyze textual information only, and there are very few works that have started exploring the gender identification using visual information. Contrastingly, this paper focuses in exploiting the visual modality to perform both age and gender identification in social media, specifically in Twitter. Our goal is to evaluate the pertinence of using visual information in solving the AP task. Accordingly, we have extended the Twitter corpus from PAN 2014, incorporating posted images from all the users, making a distinction between tweeted and retweeted images. Performed experiments provide interesting evidence on the usefulness of visual information in comparison with traditional textual representations for the AP task.
Early text classification: a Naive solution
Sep 20, 2015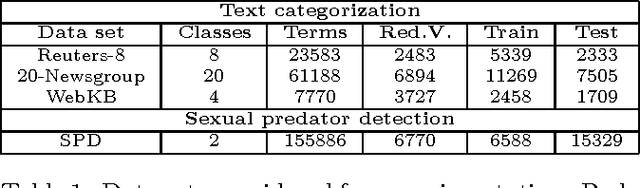
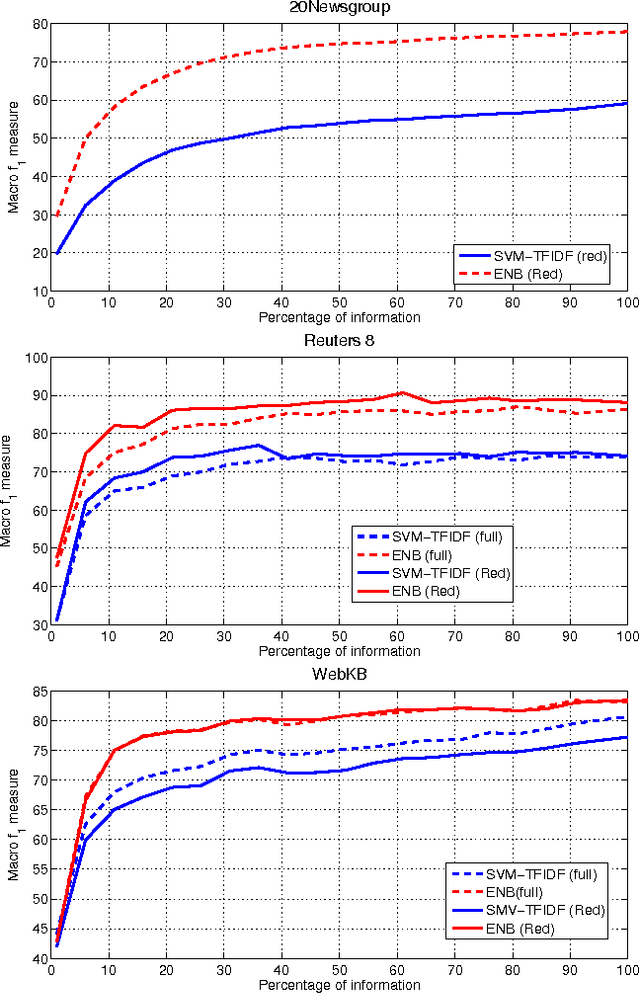
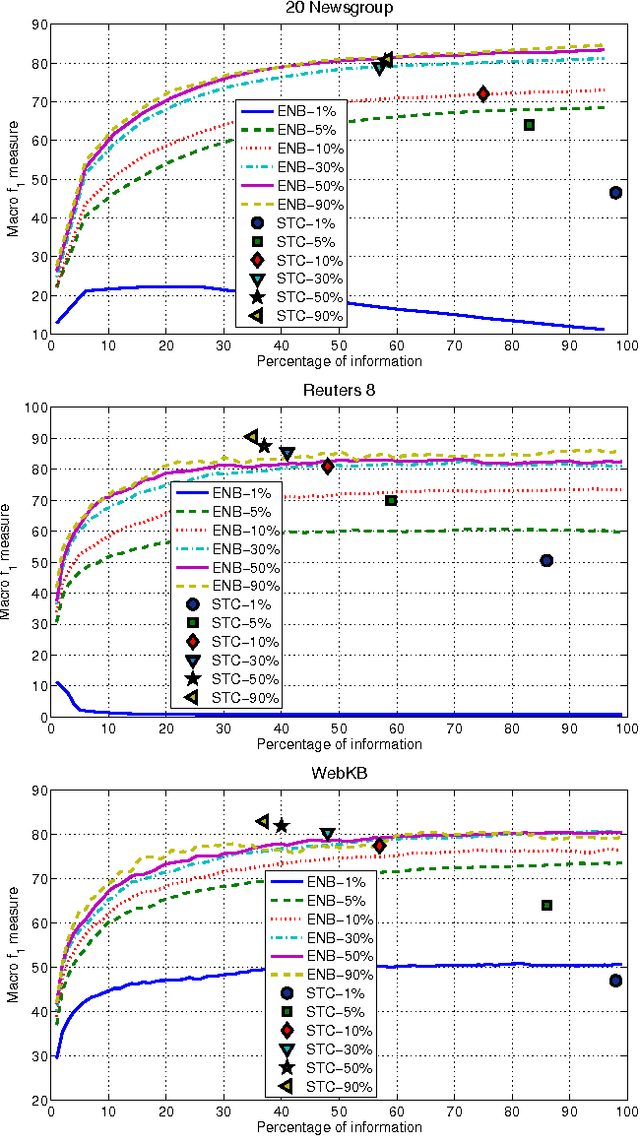

Text classification is a widely studied problem, and it can be considered solved for some domains and under certain circumstances. There are scenarios, however, that have received little or no attention at all, despite its relevance and applicability. One of such scenarios is early text classification, where one needs to know the category of a document by using partial information only. A document is processed as a sequence of terms, and the goal is to devise a method that can make predictions as fast as possible. The importance of this variant of the text classification problem is evident in domains like sexual predator detection, where one wants to identify an offender as early as possible. This paper analyzes the suitability of the standard naive Bayes classifier for approaching this problem. Specifically, we assess its performance when classifying documents after seeing an increasingly number of terms. A simple modification to the standard naive Bayes implementation allows us to make predictions with partial information. To the best of our knowledge naive Bayes has not been used for this purpose before. Throughout an extensive experimental evaluation we show the effectiveness of the classifier for early text classification. What is more, we show that this simple solution is very competitive when compared with state of the art methodologies that are more elaborated. We foresee our work will pave the way for the development of more effective early text classification techniques based in the naive Bayes formulation.