 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIberBench: LLM Evaluation on Iberian Languages
Apr 23, 2025Large Language Models (LLMs) remain difficult to evaluate comprehensively, particularly for languages other than English, where high-quality data is often limited. Existing benchmarks and leaderboards are predominantly English-centric, with only a few addressing other languages. These benchmarks fall short in several key areas: they overlook the diversity of language varieties, prioritize fundamental Natural Language Processing (NLP) capabilities over tasks of industrial relevance, and are static. With these aspects in mind, we present IberBench, a comprehensive and extensible benchmark designed to assess LLM performance on both fundamental and industry-relevant NLP tasks, in languages spoken across the Iberian Peninsula and Ibero-America. IberBench integrates 101 datasets from evaluation campaigns and recent benchmarks, covering 22 task categories such as sentiment and emotion analysis, toxicity detection, and summarization. The benchmark addresses key limitations in current evaluation practices, such as the lack of linguistic diversity and static evaluation setups by enabling continual updates and community-driven model and dataset submissions moderated by a committee of experts. We evaluate 23 LLMs ranging from 100 million to 14 billion parameters and provide empirical insights into their strengths and limitations. Our findings indicate that (i) LLMs perform worse on industry-relevant tasks than in fundamental ones, (ii) performance is on average lower for Galician and Basque, (iii) some tasks show results close to random, and (iv) in other tasks LLMs perform above random but below shared task systems. IberBench offers open-source implementations for the entire evaluation pipeline, including dataset normalization and hosting, incremental evaluation of LLMs, and a publicly accessible leaderboard.
TextMachina: Seamless Generation of Machine-Generated Text Datasets
Jan 08, 2024



Recent advancements in Large Language Models (LLMs) have led to high-quality Machine-Generated Text (MGT), giving rise to countless new use cases and applications. However, easy access to LLMs is posing new challenges due to misuse. To address malicious usage, researchers have released datasets to effectively train models on MGT-related tasks. Similar strategies are used to compile these datasets, but no tool currently unifies them. In this scenario, we introduce TextMachina, a modular and extensible Python framework, designed to aid in the creation of high-quality, unbiased datasets to build robust models for MGT-related tasks such as detection, attribution, or boundary detection. It provides a user-friendly pipeline that abstracts away the inherent intricacies of building MGT datasets, such as LLM integrations, prompt templating, and bias mitigation. The quality of the datasets generated by TextMachina has been assessed in previous works, including shared tasks where more than one hundred teams trained robust MGT detectors.
Overview of AuTexTification at IberLEF 2023: Detection and Attribution of Machine-Generated Text in Multiple Domains
Sep 20, 2023This paper presents the overview of the AuTexTification shared task as part of the IberLEF 2023 Workshop in Iberian Languages Evaluation Forum, within the framework of the SEPLN 2023 conference. AuTexTification consists of two subtasks: for Subtask 1, participants had to determine whether a text is human-authored or has been generated by a large language model. For Subtask 2, participants had to attribute a machine-generated text to one of six different text generation models. Our AuTexTification 2023 dataset contains more than 160.000 texts across two languages (English and Spanish) and five domains (tweets, reviews, news, legal, and how-to articles). A total of 114 teams signed up to participate, of which 36 sent 175 runs, and 20 of them sent their working notes. In this overview, we present the AuTexTification dataset and task, the submitted participating systems, and the results.
Programming by Example and Text-to-Code Translation for Conversational Code Generation
Nov 21, 2022Dialogue systems is an increasingly popular task of natural language processing. However, the dialogue paths tend to be deterministic, restricted to the system rails, regardless of the given request or input text. Recent advances in program synthesis have led to systems which can synthesize programs from very general search spaces, e.g. Programming by Example, and to systems with very accessible interfaces for writing programs, e.g. text-to-code translation, but have not achieved both of these qualities in the same system. We propose Modular Programs for Text-guided Hierarchical Synthesis (MPaTHS), a method for integrating Programming by Example and text-to-code systems which offers an accessible natural language interface for synthesizing general programs. We present a program representation that allows our method to be applied to the problem of task-oriented dialogue. Finally, we demo MPaTHS using our program representation.
Zero and Few-shot Learning for Author Profiling
Apr 22, 2022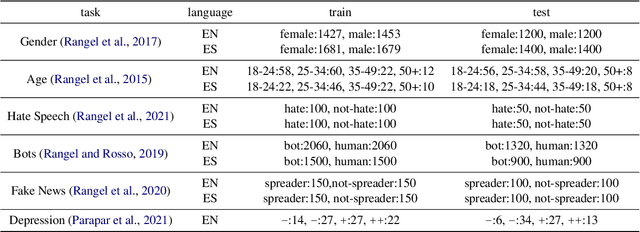
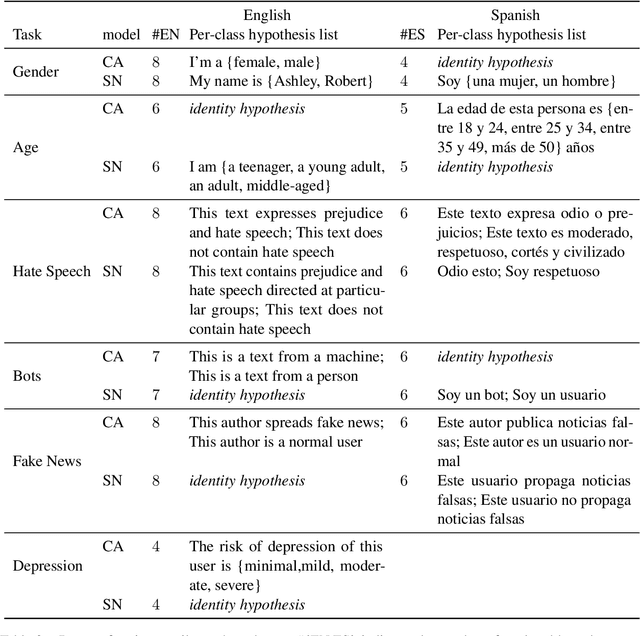
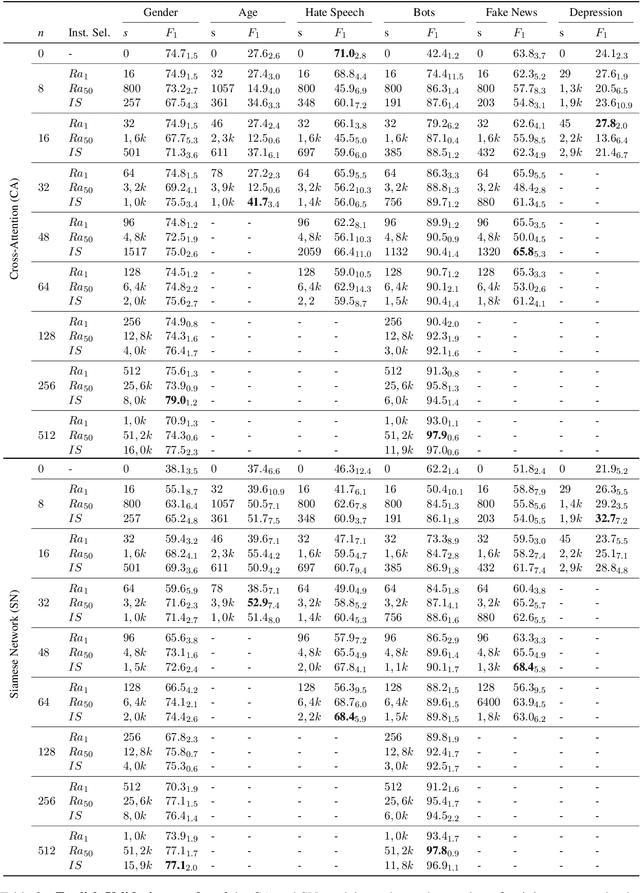
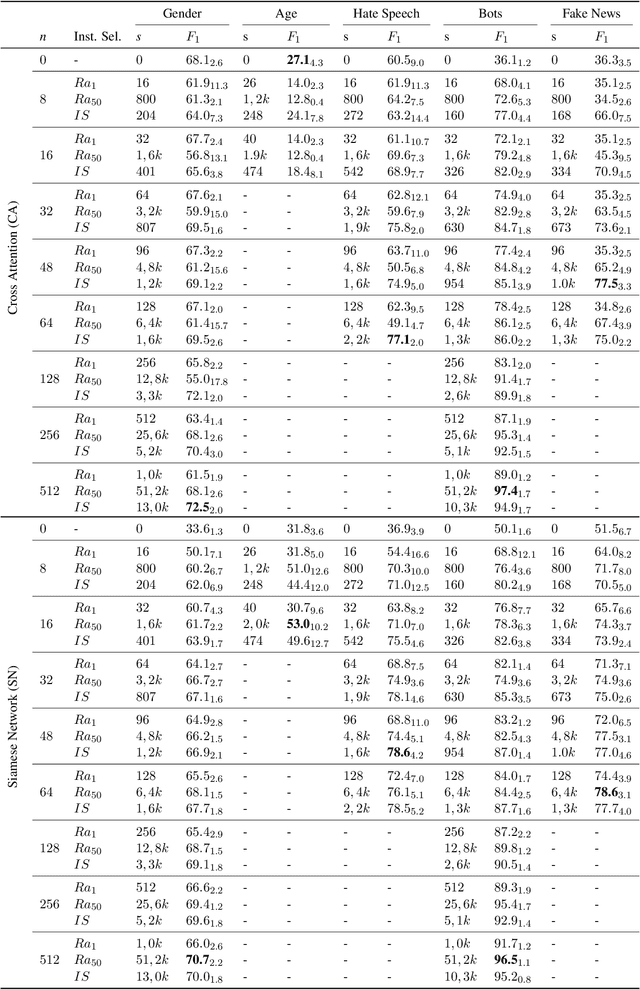
Author profiling classifies author characteristics by analyzing how language is shared among people. In this work, we study that task from a low-resource viewpoint: using little or no training data. We explore different zero and few-shot models based on entailment and evaluate our systems on several profiling tasks in Spanish and English. In addition, we study the effect of both the entailment hypothesis and the size of the few-shot training sample. We find that entailment-based models out-perform supervised text classifiers based on roberta-XLM and that we can reach 80% of the accuracy of previous approaches using less than 50\% of the training data on average.
Unsupervised Ranking and Aggregation of Label Descriptions for Zero-Shot Classifiers
Apr 20, 2022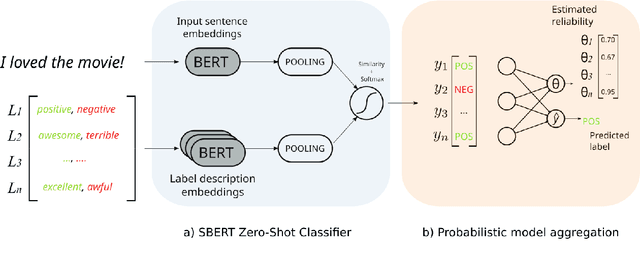
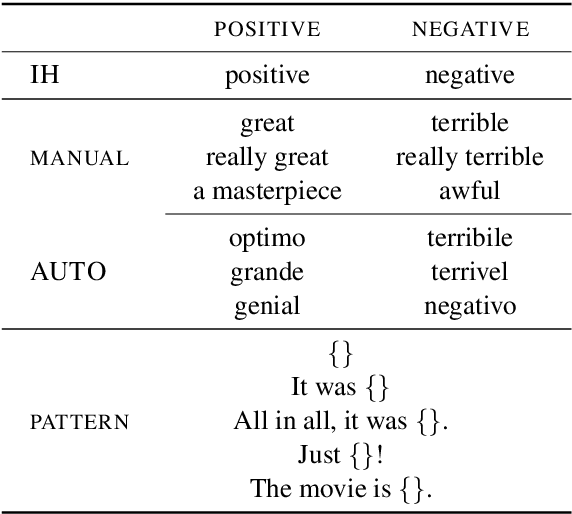
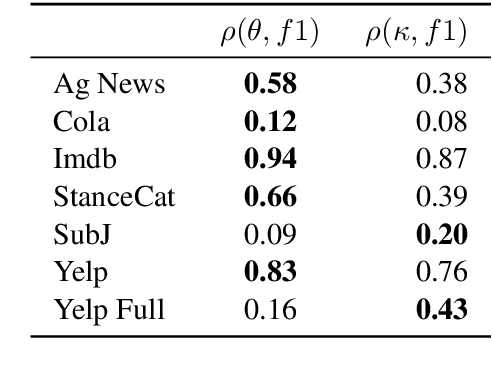

Zero-shot text classifiers based on label descriptions embed an input text and a set of labels into the same space: measures such as cosine similarity can then be used to select the most similar label description to the input text as the predicted label. In a true zero-shot setup, designing good label descriptions is challenging because no development set is available. Inspired by the literature on Learning with Disagreements, we look at how probabilistic models of repeated rating analysis can be used for selecting the best label descriptions in an unsupervised fashion. We evaluate our method on a set of diverse datasets and tasks (sentiment, topic and stance). Furthermore, we show that multiple, noisy label descriptions can be aggregated to boost the performance.
Active Few-Shot Learning with FASL
Apr 20, 2022
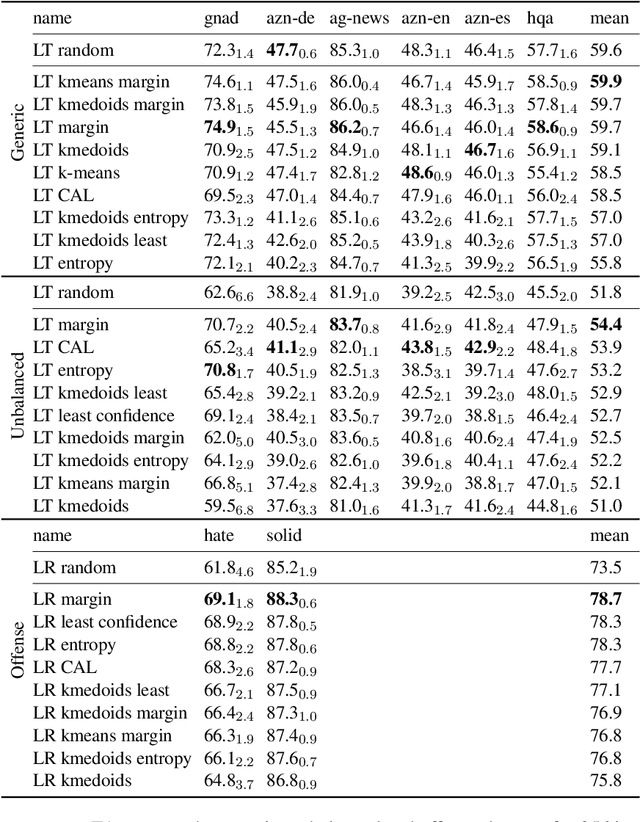
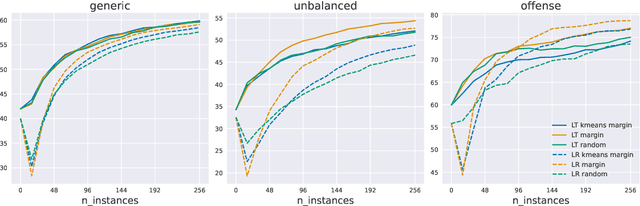
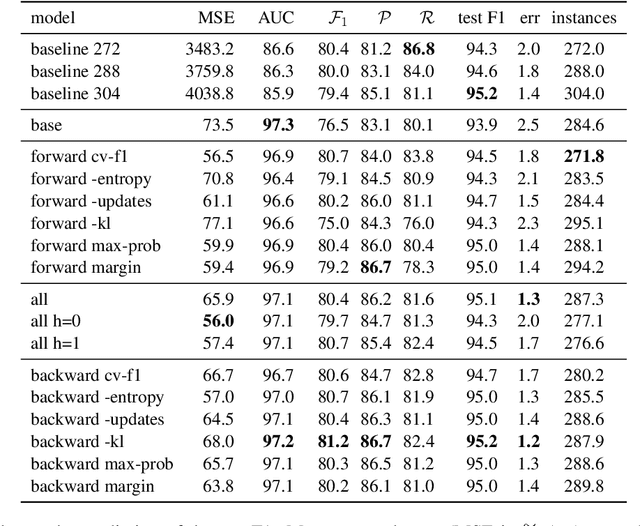
Recent advances in natural language processing (NLP) have led to strong text classification models for many tasks. However, still often thousands of examples are needed to train models with good quality. This makes it challenging to quickly develop and deploy new models for real world problems and business needs. Few-shot learning and active learning are two lines of research, aimed at tackling this problem. In this work, we combine both lines into FASL, a platform that allows training text classification models using an iterative and fast process. We investigate which active learning methods work best in our few-shot setup. Additionally, we develop a model to predict when to stop annotating. This is relevant as in a few-shot setup we do not have access to a large validation set.
Few-Shot Learning with Siamese Networks and Label Tuning
Mar 28, 2022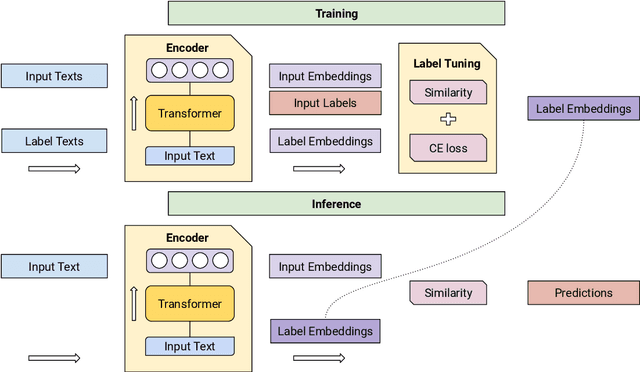
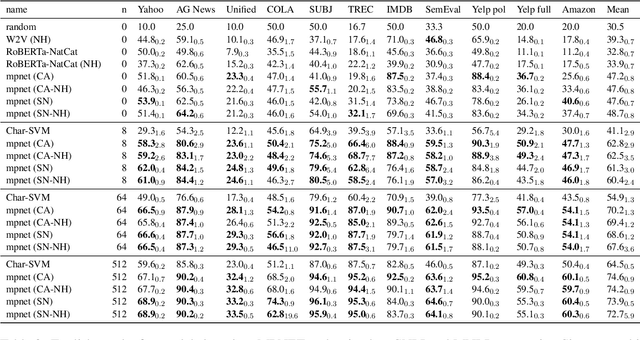

We study the problem of building text classifiers with little or no training data, commonly known as zero and few-shot text classification. In recent years, an approach based on neural textual entailment models has been found to give strong results on a diverse range of tasks. In this work, we show that with proper pre-training, Siamese Networks that embed texts and labels offer a competitive alternative. These models allow for a large reduction in inference cost: constant in the number of labels rather than linear. Furthermore, we introduce label tuning, a simple and computationally efficient approach that allows to adapt the models in a few-shot setup by only changing the label embeddings. While giving lower performance than model fine-tuning, this approach has the architectural advantage that a single encoder can be shared by many different tasks.
Benchmarking Automatic Detection of Psycholinguistic Characteristics for Better Human-Computer Interaction
Jan 13, 2021

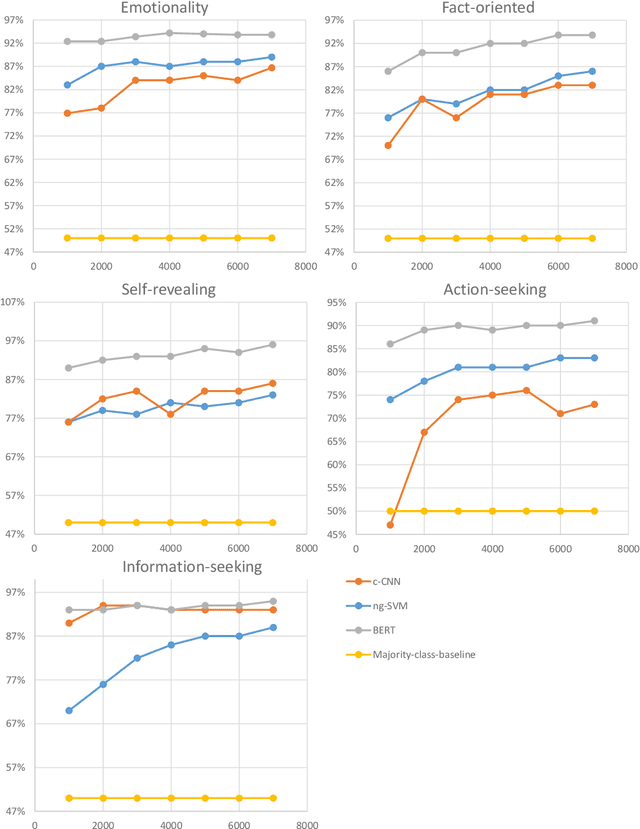
When two people pay attention to each other and are interested in what the other has to say or write, they almost instantly adapt their writing/speaking style to match the other. For a successful interaction with a user, chatbots and dialogue systems should be able to do the same. We propose a framework consisting of five psycholinguistic textual characteristics for better human-computer interaction. We describe the annotation processes used for collecting the data, and benchmark five binary classification tasks, experimenting with different training sizes and model architectures. We perform experiments in English, Spanish, German, Chinese, and Arabic. The best architectures noticeably outperform several baselines and achieve macro-averaged F1-scores between 72% and 96% depending on the language and the task. Similar results are achieved even with a small amount of training data. The proposed framework proved to be fairly easy to model for various languages even with small amount of manually annotated data if right architectures are used. At the same time, it showed potential for improving user satisfaction if applied in existing commercial chatbots.
UH-PRHLT at SemEval-2016 Task 3: Combining Lexical and Semantic-based Features for Community Question Answering
Jul 30, 2018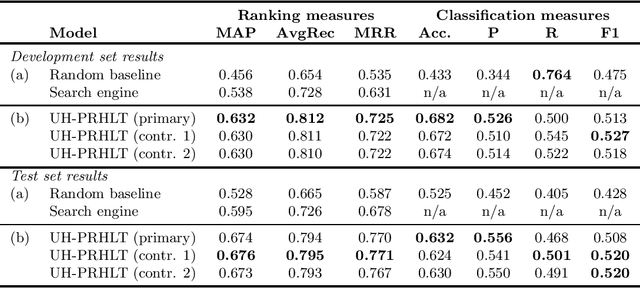
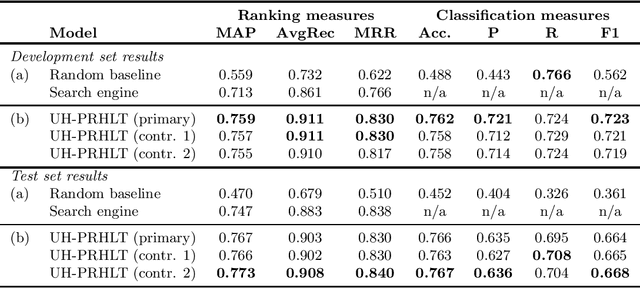
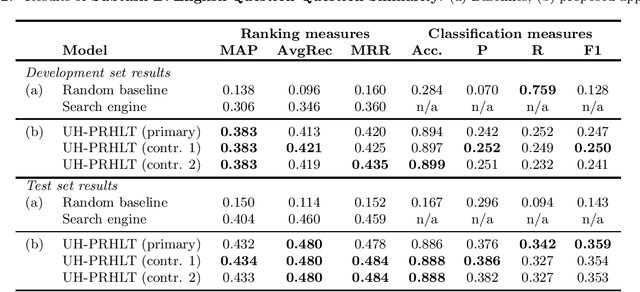
In this work we describe the system built for the three English subtasks of the SemEval 2016 Task 3 by the Department of Computer Science of the University of Houston (UH) and the Pattern Recognition and Human Language Technology (PRHLT) research center - Universitat Polit`ecnica de Val`encia: UH-PRHLT. Our system represents instances by using both lexical and semantic-based similarity measures between text pairs. Our semantic features include the use of distributed representations of words, knowledge graphs generated with the BabelNet multilingual semantic network, and the FrameNet lexical database. Experimental results outperform the random and Google search engine baselines in the three English subtasks. Our approach obtained the highest results of subtask B compared to the other task participants.