 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBenchmarking Automatic Detection of Psycholinguistic Characteristics for Better Human-Computer Interaction
Paper and Code

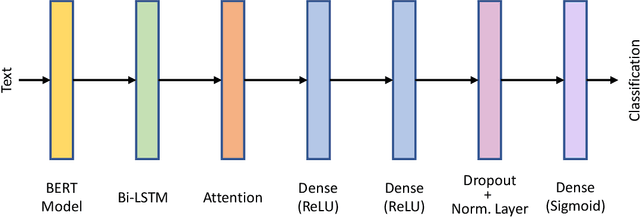

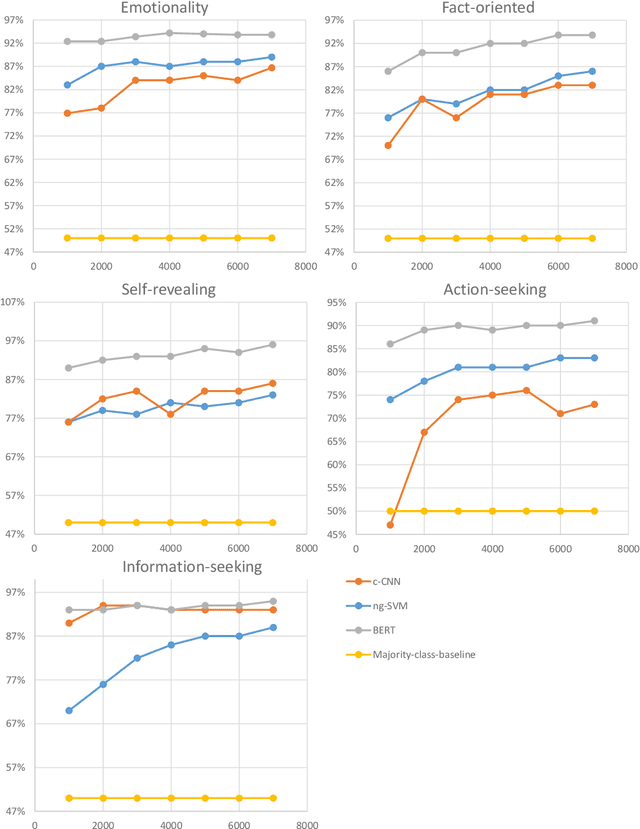
When two people pay attention to each other and are interested in what the other has to say or write, they almost instantly adapt their writing/speaking style to match the other. For a successful interaction with a user, chatbots and dialogue systems should be able to do the same. We propose a framework consisting of five psycholinguistic textual characteristics for better human-computer interaction. We describe the annotation processes used for collecting the data, and benchmark five binary classification tasks, experimenting with different training sizes and model architectures. We perform experiments in English, Spanish, German, Chinese, and Arabic. The best architectures noticeably outperform several baselines and achieve macro-averaged F1-scores between 72% and 96% depending on the language and the task. Similar results are achieved even with a small amount of training data. The proposed framework proved to be fairly easy to model for various languages even with small amount of manually annotated data if right architectures are used. At the same time, it showed potential for improving user satisfaction if applied in existing commercial chatbots.