Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZero and Few-shot Learning for Author Profiling
Paper and Code
Apr 22, 2022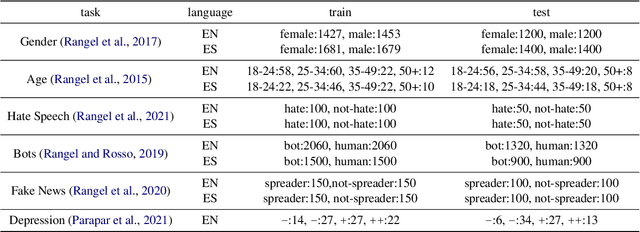
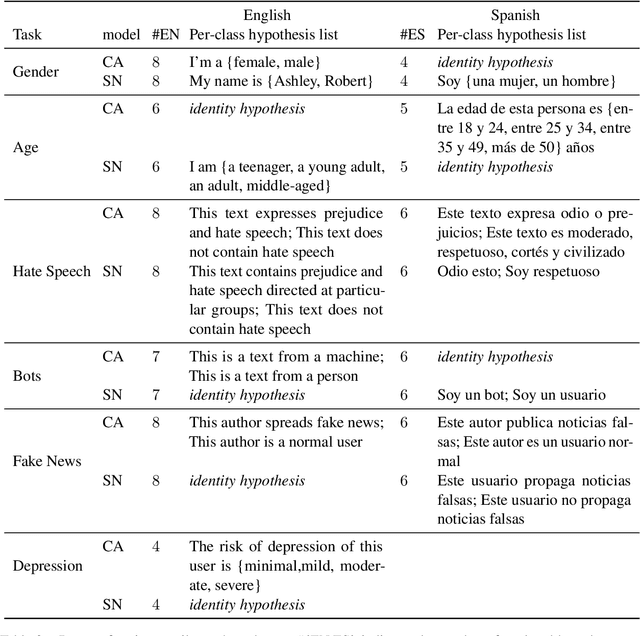
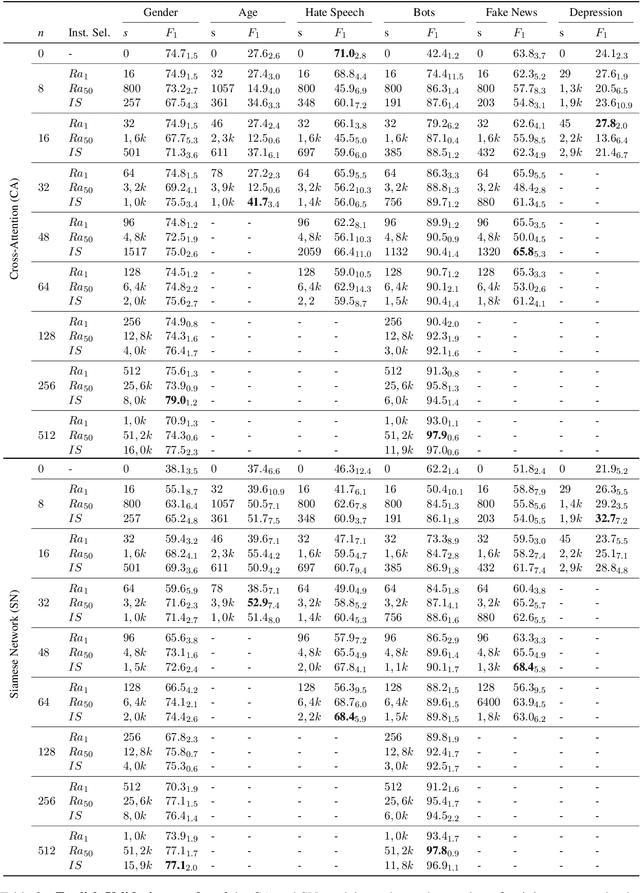
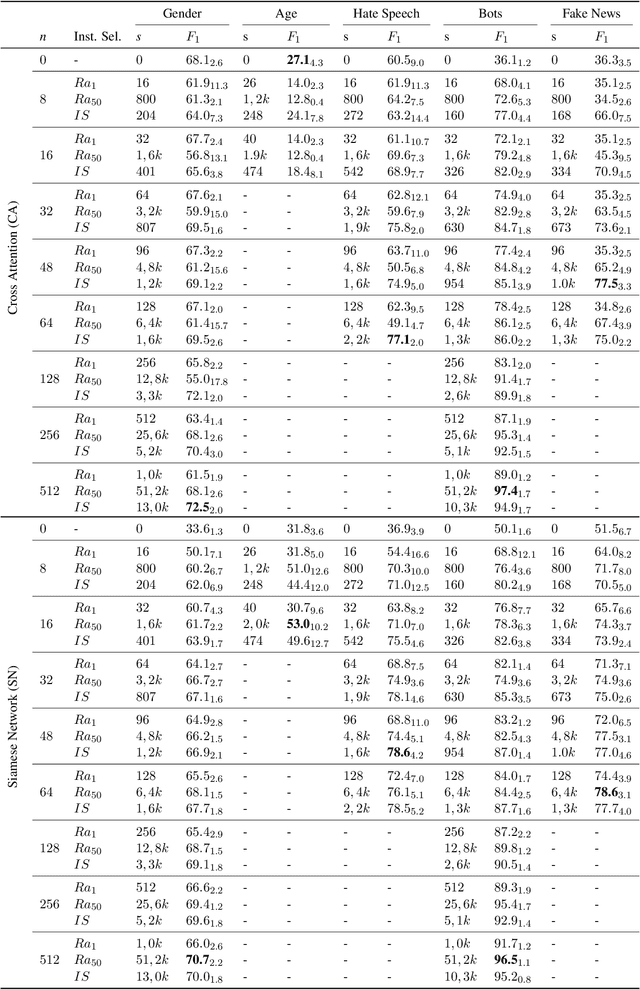
Author profiling classifies author characteristics by analyzing how language is shared among people. In this work, we study that task from a low-resource viewpoint: using little or no training data. We explore different zero and few-shot models based on entailment and evaluate our systems on several profiling tasks in Spanish and English. In addition, we study the effect of both the entailment hypothesis and the size of the few-shot training sample. We find that entailment-based models out-perform supervised text classifiers based on roberta-XLM and that we can reach 80% of the accuracy of previous approaches using less than 50\% of the training data on average.
View paper on