 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProgramming by Example and Text-to-Code Translation for Conversational Code Generation
Nov 21, 2022Dialogue systems is an increasingly popular task of natural language processing. However, the dialogue paths tend to be deterministic, restricted to the system rails, regardless of the given request or input text. Recent advances in program synthesis have led to systems which can synthesize programs from very general search spaces, e.g. Programming by Example, and to systems with very accessible interfaces for writing programs, e.g. text-to-code translation, but have not achieved both of these qualities in the same system. We propose Modular Programs for Text-guided Hierarchical Synthesis (MPaTHS), a method for integrating Programming by Example and text-to-code systems which offers an accessible natural language interface for synthesizing general programs. We present a program representation that allows our method to be applied to the problem of task-oriented dialogue. Finally, we demo MPaTHS using our program representation.
FOIL it! Find One mismatch between Image and Language caption
May 03, 2017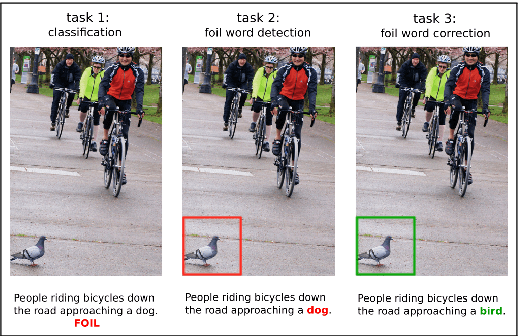



In this paper, we aim to understand whether current language and vision (LaVi) models truly grasp the interaction between the two modalities. To this end, we propose an extension of the MSCOCO dataset, FOIL-COCO, which associates images with both correct and "foil" captions, that is, descriptions of the image that are highly similar to the original ones, but contain one single mistake ("foil word"). We show that current LaVi models fall into the traps of this data and perform badly on three tasks: a) caption classification (correct vs. foil); b) foil word detection; c) foil word correction. Humans, in contrast, have near-perfect performance on those tasks. We demonstrate that merely utilising language cues is not enough to model FOIL-COCO and that it challenges the state-of-the-art by requiring a fine-grained understanding of the relation between text and image.