 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Interpretability using Human Similarity Judgements to Prune Word Embeddings
Oct 16, 2023
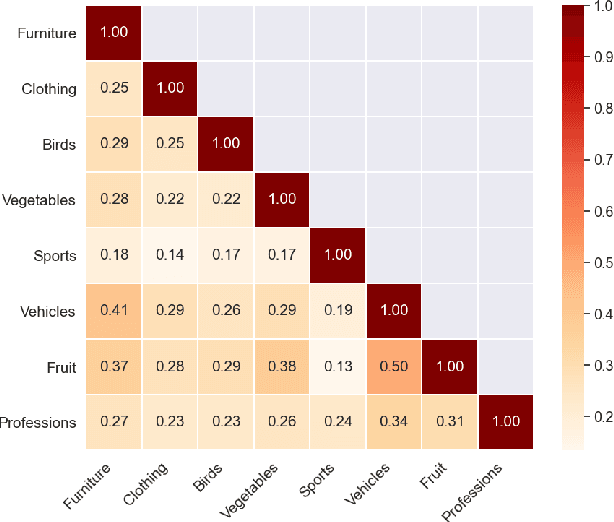


Interpretability methods in NLP aim to provide insights into the semantics underlying specific system architectures. Focusing on word embeddings, we present a supervised-learning method that, for a given domain (e.g., sports, professions), identifies a subset of model features that strongly improve prediction of human similarity judgments. We show this method keeps only 20-40% of the original embeddings, for 8 independent semantic domains, and that it retains different feature sets across domains. We then present two approaches for interpreting the semantics of the retained features. The first obtains the scores of the domain words (co-hyponyms) on the first principal component of the retained embeddings, and extracts terms whose co-occurrence with the co-hyponyms tracks these scores' profile. This analysis reveals that humans differentiate e.g. sports based on how gender-inclusive and international they are. The second approach uses the retained sets as variables in a probing task that predicts values along 65 semantically annotated dimensions for a dataset of 535 words. The features retained for professions are best at predicting cognitive, emotional and social dimensions, whereas features retained for fruits or vegetables best predict the gustation (taste) dimension. We discuss implications for alignment between AI systems and human knowledge.
How to marry a star: probabilistic constraints for meaning in context
Sep 16, 2020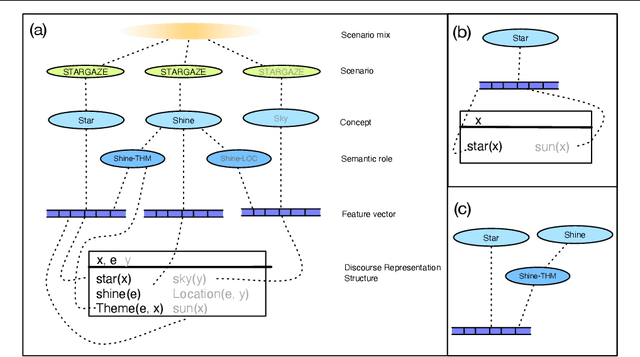

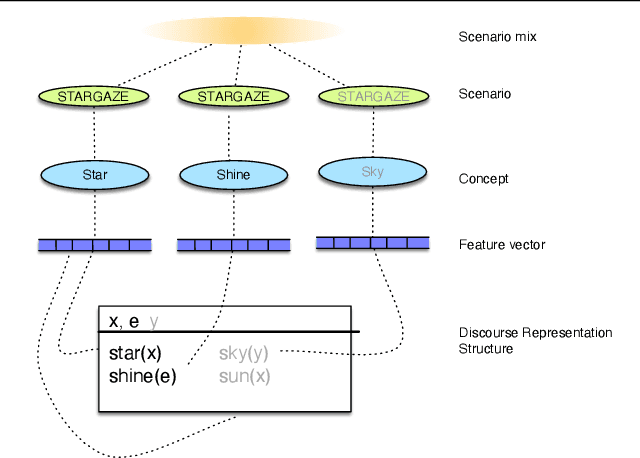
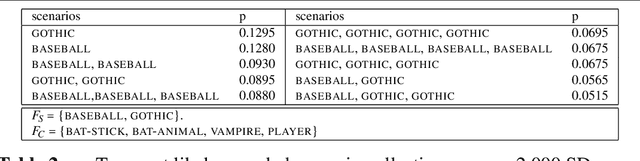
In this paper, we derive a notion of word meaning in context from Fillmore's 'semantics of understanding', in which a listener draws on their knowledge of both language and the world to 'envision' the situation described in an utterance. We characterize utterance understanding as a combination of cognitive semantics and Discourse Representation Theory, formalized as a situation description system:a probabilistic model which takes utterance understanding to be the mental process of describing one or more situations that would account for an observed utterance. Our model captures the interplay of local and global contexts and their joint influence upon the lexical representation of sentence constituents. We implement the system using a directed graphical model, and apply it to examples containing various contextualization phenomena.
High-risk learning: acquiring new word vectors from tiny data
Jul 20, 2017

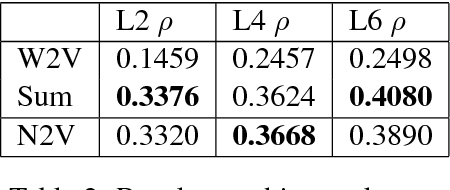
Distributional semantics models are known to struggle with small data. It is generally accepted that in order to learn 'a good vector' for a word, a model must have sufficient examples of its usage. This contradicts the fact that humans can guess the meaning of a word from a few occurrences only. In this paper, we show that a neural language model such as Word2Vec only necessitates minor modifications to its standard architecture to learn new terms from tiny data, using background knowledge from a previously learnt semantic space. We test our model on word definitions and on a nonce task involving 2-6 sentences' worth of context, showing a large increase in performance over state-of-the-art models on the definitional task.
FOIL it! Find One mismatch between Image and Language caption
May 03, 2017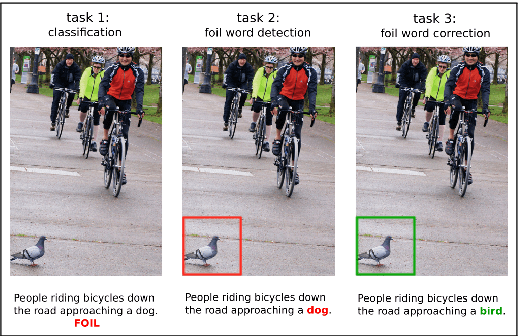



In this paper, we aim to understand whether current language and vision (LaVi) models truly grasp the interaction between the two modalities. To this end, we propose an extension of the MSCOCO dataset, FOIL-COCO, which associates images with both correct and "foil" captions, that is, descriptions of the image that are highly similar to the original ones, but contain one single mistake ("foil word"). We show that current LaVi models fall into the traps of this data and perform badly on three tasks: a) caption classification (correct vs. foil); b) foil word detection; c) foil word correction. Humans, in contrast, have near-perfect performance on those tasks. We demonstrate that merely utilising language cues is not enough to model FOIL-COCO and that it challenges the state-of-the-art by requiring a fine-grained understanding of the relation between text and image.