Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHigh-risk learning: acquiring new word vectors from tiny data
Paper and Code


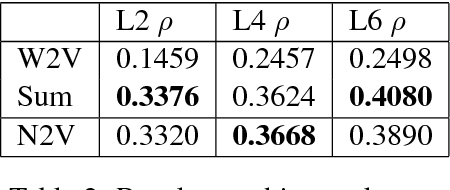
Distributional semantics models are known to struggle with small data. It is generally accepted that in order to learn 'a good vector' for a word, a model must have sufficient examples of its usage. This contradicts the fact that humans can guess the meaning of a word from a few occurrences only. In this paper, we show that a neural language model such as Word2Vec only necessitates minor modifications to its standard architecture to learn new terms from tiny data, using background knowledge from a previously learnt semantic space. We test our model on word definitions and on a nonce task involving 2-6 sentences' worth of context, showing a large increase in performance over state-of-the-art models on the definitional task.
* Accepted as short paper at EMNLP 2017
View paper on