 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRefining Dimensions for Improving Clustering-based Cross-lingual Topic Models
Dec 17, 2024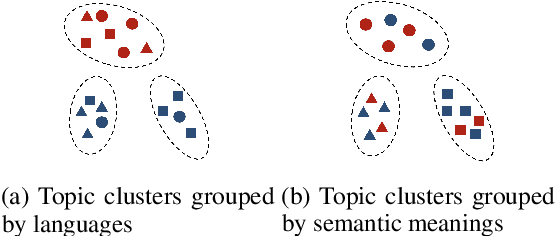
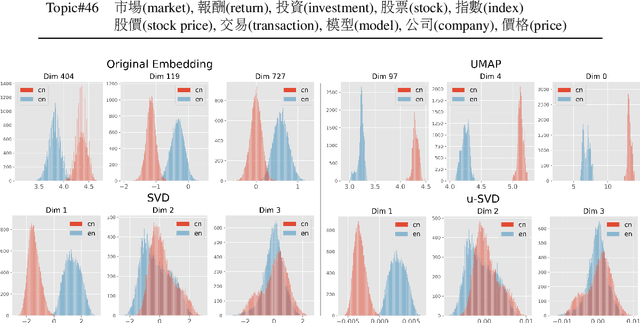

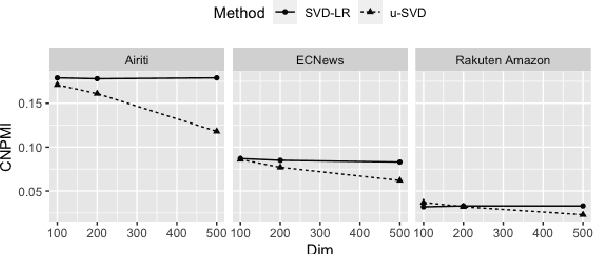
Recent works in clustering-based topic models perform well in monolingual topic identification by introducing a pipeline to cluster the contextualized representations. However, the pipeline is suboptimal in identifying topics across languages due to the presence of language-dependent dimensions (LDDs) generated by multilingual language models. To address this issue, we introduce a novel, SVD-based dimension refinement component into the pipeline of the clustering-based topic model. This component effectively neutralizes the negative impact of LDDs, enabling the model to accurately identify topics across languages. Our experiments on three datasets demonstrate that the updated pipeline with the dimension refinement component generally outperforms other state-of-the-art cross-lingual topic models.
SpaceEditing: Integrating Human Knowledge into Deep Neural Networks via Interactive Latent Space Editing
Dec 08, 2022



We propose an interactive editing method that allows humans to help deep neural networks (DNNs) learn a latent space more consistent with human knowledge, thereby improving classification accuracy on indistinguishable ambiguous data. Firstly, we visualize high-dimensional data features through dimensionality reduction methods and design an interactive system \textit{SpaceEditing} to display the visualized data. \textit{SpaceEditing} provides a 2D workspace based on the idea of spatial layout. In this workspace, the user can move the projection data in it according to the system guidance. Then, \textit{SpaceEditing} will find the corresponding high-dimensional features according to the projection data moved by the user, and feed the high-dimensional features back to the network for retraining, therefore achieving the purpose of interactively modifying the high-dimensional latent space for the user. Secondly, to more rationally incorporate human knowledge into the training process of neural networks, we design a new loss function that enables the network to learn user-modified information. Finally, We demonstrate how \textit{SpaceEditing} meets user needs through three case studies while evaluating our proposed new method, and the results confirm the effectiveness of our method.
SGDraw: Scene Graph Drawing Interface Using Object-Oriented Representation
Nov 30, 2022



Scene understanding is an essential and challenging task in computer vision. To provide the visually fundamental graphical structure of an image, the scene graph has received increased attention due to its powerful semantic representation. However, it is difficult to draw a proper scene graph for image retrieval, image generation, and multi-modal applications. The conventional scene graph annotation interface is not easy to use in image annotations, and the automatic scene graph generation approaches using deep neural networks are prone to generate redundant content while disregarding details. In this work, we propose SGDraw, a scene graph drawing interface using object-oriented scene graph representation to help users draw and edit scene graphs interactively. For the proposed object-oriented representation, we consider the objects, attributes, and relationships of objects as a structural unit. SGDraw provides a web-based scene graph annotation and generation tool for scene understanding applications. To verify the effectiveness of the proposed interface, we conducted a comparison study with the conventional tool and the user experience study. The results show that SGDraw can help generate scene graphs with richer details and describe the images more accurately than traditional bounding box annotations. We believe the proposed SGDraw can be useful in various vision tasks, such as image retrieval and generation.
Efficient Human-in-the-loop System for Guiding DNNs Attention
Jun 14, 2022

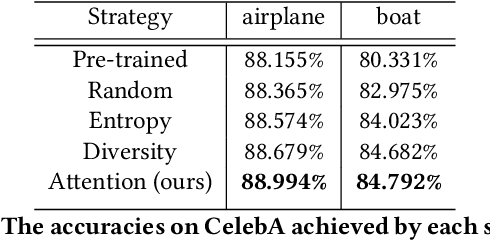
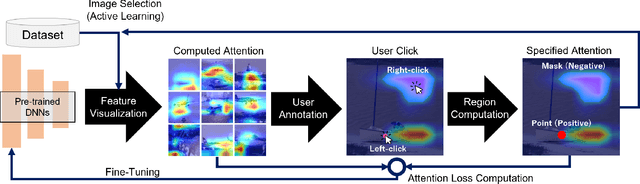
Attention guidance is an approach to addressing dataset bias in deep learning, where the model relies on incorrect features to make decisions. Focusing on image classification tasks, we propose an efficient human-in-the-loop system to interactively direct the attention of classifiers to the regions specified by users, thereby reducing the influence of co-occurrence bias and improving the transferability and interpretability of a DNN. Previous approaches for attention guidance require the preparation of pixel-level annotations and are not designed as interactive systems. We present a new interactive method to allow users to annotate images with simple clicks, and study a novel active learning strategy to significantly reduce the number of annotations. We conducted both a numerical evaluation and a user study to evaluate the proposed system on multiple datasets. Compared to the existing non-active-learning approach which usually relies on huge amounts of polygon-based segmentation masks to fine-tune or train the DNNs, our system can save lots of labor and money and obtain a fine-tuned network that works better even when the dataset is biased. The experiment results indicate that the proposed system is efficient, reasonable, and reliable.
DAMix: Density-Aware Data Augmentation for Unsupervised Domain Adaptation on Single Image Dehazing
Sep 26, 2021
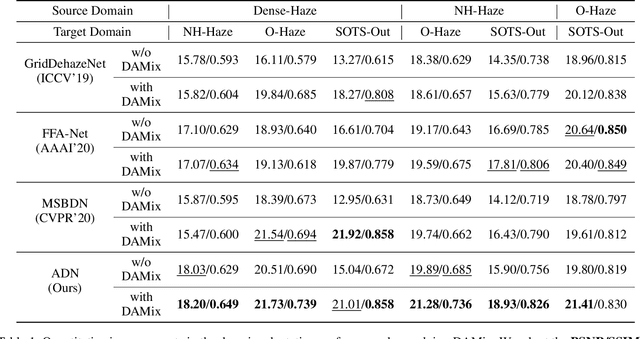
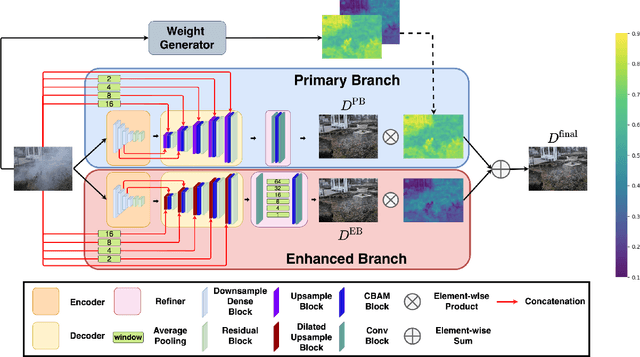
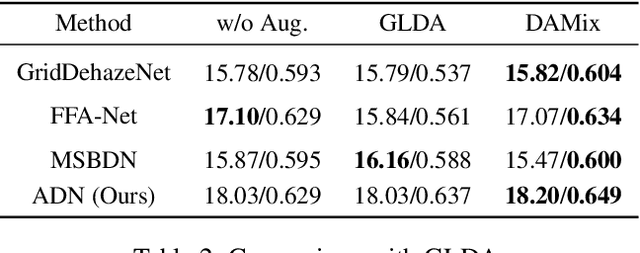
Learning-based methods have achieved great success on single image dehazing in recent years. However, these methods are often subject to performance degradation when domain shifts are confronted. Specifically, haze density gaps exist among the existing datasets, often resulting in poor performance when these methods are tested across datasets. To address this issue, we propose a density-aware data augmentation method (DAMix) that generates synthetic hazy samples according to the haze density level of the target domain. These samples are generated by combining a hazy image with its corresponding ground truth by a combination ratio sampled from a density-aware distribution. They not only comply with the atmospheric scattering model but also bridge the haze density gap between the source and target domains. DAMix ensures that the model learns from examples featuring diverse haze densities. To better utilize the various hazy samples generated by DAMix, we develop a dual-branch dehazing network involving two branches that can adaptively remove haze according to the haze density of the region. In addition, the dual-branch design enlarges the learning capacity of the entire network; hence, our network can fully utilize the DAMix-ed samples. We evaluate the effectiveness of DAMix by applying it to the existing open-source dehazing methods. The experimental results demonstrate that all methods show significant improvements after DAMix is applied. Furthermore, by combining DAMix with our model, we can achieve state-of-the-art (SOTA) performance in terms of domain adaptation.