 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRefining Dimensions for Improving Clustering-based Cross-lingual Topic Models
Dec 17, 2024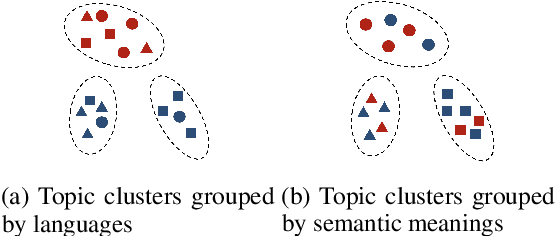
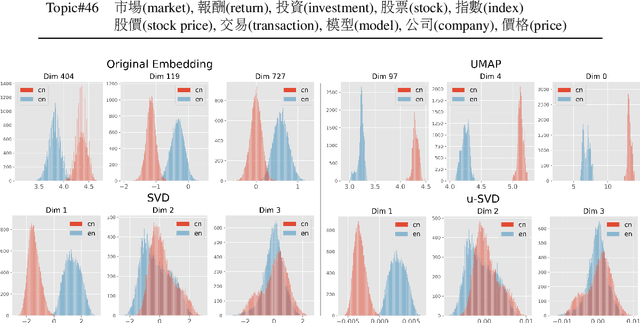

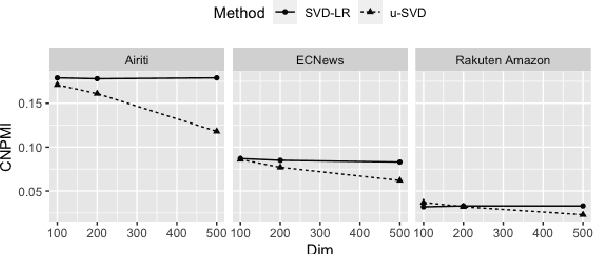
Recent works in clustering-based topic models perform well in monolingual topic identification by introducing a pipeline to cluster the contextualized representations. However, the pipeline is suboptimal in identifying topics across languages due to the presence of language-dependent dimensions (LDDs) generated by multilingual language models. To address this issue, we introduce a novel, SVD-based dimension refinement component into the pipeline of the clustering-based topic model. This component effectively neutralizes the negative impact of LDDs, enabling the model to accurately identify topics across languages. Our experiments on three datasets demonstrate that the updated pipeline with the dimension refinement component generally outperforms other state-of-the-art cross-lingual topic models.
LITA: An Efficient LLM-assisted Iterative Topic Augmentation Framework
Dec 17, 2024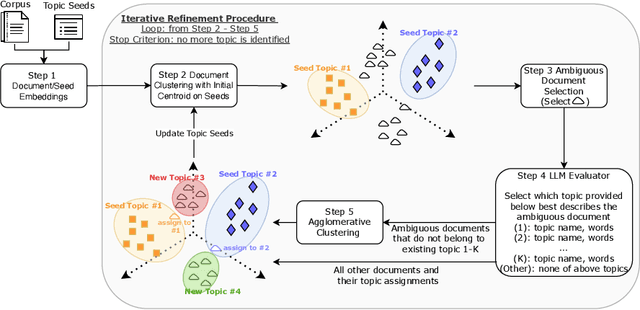



Topic modeling is widely used for uncovering thematic structures within text corpora, yet traditional models often struggle with specificity and coherence in domain-focused applications. Guided approaches, such as SeededLDA and CorEx, incorporate user-provided seed words to improve relevance but remain labor-intensive and static. Large language models (LLMs) offer potential for dynamic topic refinement and discovery, yet their application often incurs high API costs. To address these challenges, we propose the LLM-assisted Iterative Topic Augmentation framework (LITA), an LLM-assisted approach that integrates user-provided seeds with embedding-based clustering and iterative refinement. LITA identifies a small number of ambiguous documents and employs an LLM to reassign them to existing or new topics, minimizing API costs while enhancing topic quality. Experiments on two datasets across topic quality and clustering performance metrics demonstrate that LITA outperforms five baseline models, including LDA, SeededLDA, CorEx, BERTopic, and PromptTopic. Our work offers an efficient and adaptable framework for advancing topic modeling and text clustering.
On Exploring the Reasoning Capability of Large Language Models with Knowledge Graphs
Dec 01, 2023
This paper examines the capacity of LLMs to reason with knowledge graphs using their internal knowledge graph, i.e., the knowledge graph they learned during pre-training. Two research questions are formulated to investigate the accuracy of LLMs in recalling information from pre-training knowledge graphs and their ability to infer knowledge graph relations from context. To address these questions, we employ LLMs to perform four distinct knowledge graph reasoning tasks. Furthermore, we identify two types of hallucinations that may occur during knowledge reasoning with LLMs: content and ontology hallucination. Our experimental results demonstrate that LLMs can successfully tackle both simple and complex knowledge graph reasoning tasks from their own memory, as well as infer from input context.