 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLITA: An Efficient LLM-assisted Iterative Topic Augmentation Framework
Paper and Code
Dec 17, 2024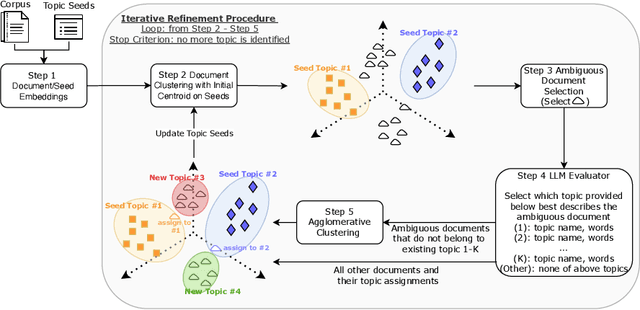



Topic modeling is widely used for uncovering thematic structures within text corpora, yet traditional models often struggle with specificity and coherence in domain-focused applications. Guided approaches, such as SeededLDA and CorEx, incorporate user-provided seed words to improve relevance but remain labor-intensive and static. Large language models (LLMs) offer potential for dynamic topic refinement and discovery, yet their application often incurs high API costs. To address these challenges, we propose the LLM-assisted Iterative Topic Augmentation framework (LITA), an LLM-assisted approach that integrates user-provided seeds with embedding-based clustering and iterative refinement. LITA identifies a small number of ambiguous documents and employs an LLM to reassign them to existing or new topics, minimizing API costs while enhancing topic quality. Experiments on two datasets across topic quality and clustering performance metrics demonstrate that LITA outperforms five baseline models, including LDA, SeededLDA, CorEx, BERTopic, and PromptTopic. Our work offers an efficient and adaptable framework for advancing topic modeling and text clustering.