 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMedViz: An Agent-based, Visual-guided Research Assistant for Navigating Biomedical Literature
Jan 28, 2026Biomedical researchers face increasing challenges in navigating millions of publications in diverse domains. Traditional search engines typically return articles as ranked text lists, offering little support for global exploration or in-depth analysis. Although recent advances in generative AI and large language models have shown promise in tasks such as summarization, extraction, and question answering, their dialog-based implementations are poorly integrated with literature search workflows. To address this gap, we introduce MedViz, a visual analytics system that integrates multiple AI agents with interactive visualization to support the exploration of the large-scale biomedical literature. MedViz combines a semantic map of millions of articles with agent-driven functions for querying, summarizing, and hypothesis generation, allowing researchers to iteratively refine questions, identify trends, and uncover hidden connections. By bridging intelligent agents with interactive visualization, MedViz transforms biomedical literature search into a dynamic, exploratory process that accelerates knowledge discovery.
ctELM: Decoding and Manipulating Embeddings of Clinical Trials with Embedding Language Models
Jan 26, 2026Text embeddings have become an essential part of a variety of language applications. However, methods for interpreting, exploring and reversing embedding spaces are limited, reducing transparency and precluding potentially valuable generative use cases. In this work, we align Large Language Models to embeddings of clinical trials using the recently reported Embedding Language Model (ELM) method. We develop an open-source, domain-agnostic ELM architecture and training framework, design training tasks for clinical trials, and introduce an expert-validated synthetic dataset. We then train a series of ELMs exploring the impact of tasks and training regimes. Our final model, ctELM, can accurately describe and compare unseen clinical trials from embeddings alone and produce plausible clinical trials from novel vectors. We further show that generated trial abstracts are responsive to moving embeddings along concept vectors for age and sex of study subjects. Our public ELM implementation and experimental results will aid the alignment of Large Language Models to embedding spaces in the biomedical domain and beyond.
Collaboration among Multiple Large Language Models for Medical Question Answering
May 22, 2025Empowered by vast internal knowledge reservoir, the new generation of large language models (LLMs) demonstrate untapped potential to tackle medical tasks. However, there is insufficient effort made towards summoning up a synergic effect from multiple LLMs' expertise and background. In this study, we propose a multi-LLM collaboration framework tailored on a medical multiple-choice questions dataset. Through post-hoc analysis on 3 pre-trained LLM participants, our framework is proved to boost all LLMs reasoning ability as well as alleviate their divergence among questions. We also measure an LLM's confidence when it confronts with adversary opinions from other LLMs and observe a concurrence between LLM's confidence and prediction accuracy.
LITA: An Efficient LLM-assisted Iterative Topic Augmentation Framework
Dec 17, 2024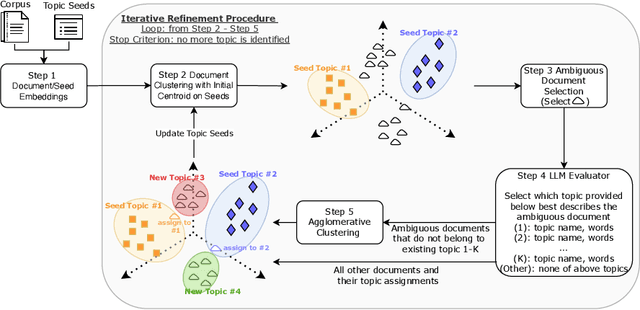



Topic modeling is widely used for uncovering thematic structures within text corpora, yet traditional models often struggle with specificity and coherence in domain-focused applications. Guided approaches, such as SeededLDA and CorEx, incorporate user-provided seed words to improve relevance but remain labor-intensive and static. Large language models (LLMs) offer potential for dynamic topic refinement and discovery, yet their application often incurs high API costs. To address these challenges, we propose the LLM-assisted Iterative Topic Augmentation framework (LITA), an LLM-assisted approach that integrates user-provided seeds with embedding-based clustering and iterative refinement. LITA identifies a small number of ambiguous documents and employs an LLM to reassign them to existing or new topics, minimizing API costs while enhancing topic quality. Experiments on two datasets across topic quality and clustering performance metrics demonstrate that LITA outperforms five baseline models, including LDA, SeededLDA, CorEx, BERTopic, and PromptTopic. Our work offers an efficient and adaptable framework for advancing topic modeling and text clustering.
Refining Dimensions for Improving Clustering-based Cross-lingual Topic Models
Dec 17, 2024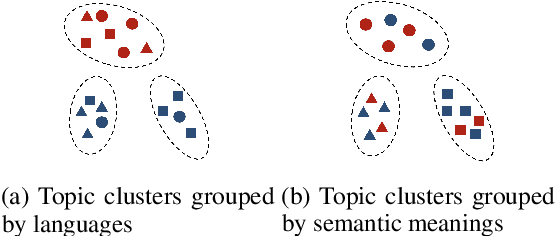
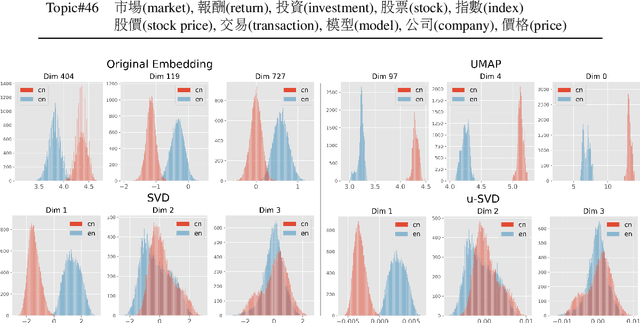

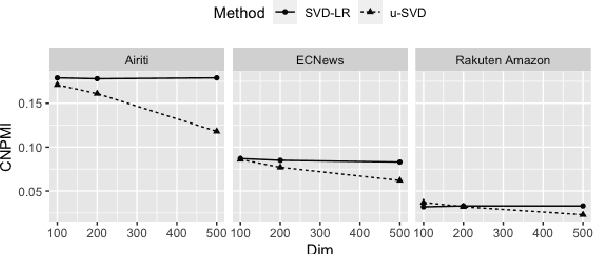
Recent works in clustering-based topic models perform well in monolingual topic identification by introducing a pipeline to cluster the contextualized representations. However, the pipeline is suboptimal in identifying topics across languages due to the presence of language-dependent dimensions (LDDs) generated by multilingual language models. To address this issue, we introduce a novel, SVD-based dimension refinement component into the pipeline of the clustering-based topic model. This component effectively neutralizes the negative impact of LDDs, enabling the model to accurately identify topics across languages. Our experiments on three datasets demonstrate that the updated pipeline with the dimension refinement component generally outperforms other state-of-the-art cross-lingual topic models.
Explainable AI for Fair Sepsis Mortality Predictive Model
Apr 19, 2024Artificial intelligence supports healthcare professionals with predictive modeling, greatly transforming clinical decision-making. This study addresses the crucial need for fairness and explainability in AI applications within healthcare to ensure equitable outcomes across diverse patient demographics. By focusing on the predictive modeling of sepsis-related mortality, we propose a method that learns a performance-optimized predictive model and then employs the transfer learning process to produce a model with better fairness. Our method also introduces a novel permutation-based feature importance algorithm aiming at elucidating the contribution of each feature in enhancing fairness on predictions. Unlike existing explainability methods concentrating on explaining feature contribution to predictive performance, our proposed method uniquely bridges the gap in understanding how each feature contributes to fairness. This advancement is pivotal, given sepsis's significant mortality rate and its role in one-third of hospital deaths. Our method not only aids in identifying and mitigating biases within the predictive model but also fosters trust among healthcare stakeholders by improving the transparency and fairness of model predictions, thereby contributing to more equitable and trustworthy healthcare delivery.
Beyond Self-Consistency: Ensemble Reasoning Boosts Consistency and Accuracy of LLMs in Cancer Staging
Apr 19, 2024Advances in large language models (LLMs) have encouraged their adoption in the healthcare domain where vital clinical information is often contained in unstructured notes. Cancer staging status is available in clinical reports, but it requires natural language processing to extract the status from the unstructured text. With the advance in clinical-oriented LLMs, it is promising to extract such status without extensive efforts in training the algorithms. Prompting approaches of the pre-trained LLMs that elicit a model's reasoning process, such as chain-of-thought, may help to improve the trustworthiness of the generated responses. Using self-consistency further improves model performance, but often results in inconsistent generations across the multiple reasoning paths. In this study, we propose an ensemble reasoning approach with the aim of improving the consistency of the model generations. Using an open access clinical large language model to determine the pathologic cancer stage from real-world pathology reports, we show that the ensemble reasoning approach is able to improve both the consistency and performance of the LLM in determining cancer stage, thereby demonstrating the potential to use these models in clinical or other domains where reliability and trustworthiness are critical.
An ExplainableFair Framework for Prediction of Substance Use Disorder Treatment Completion
Apr 04, 2024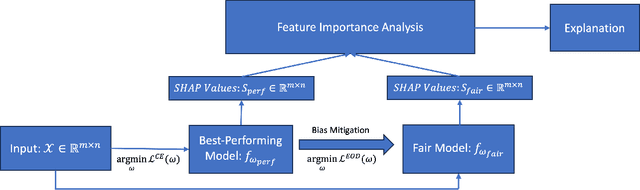
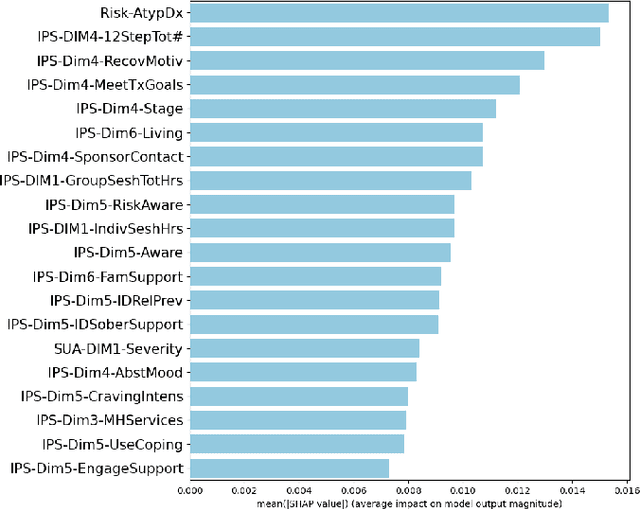
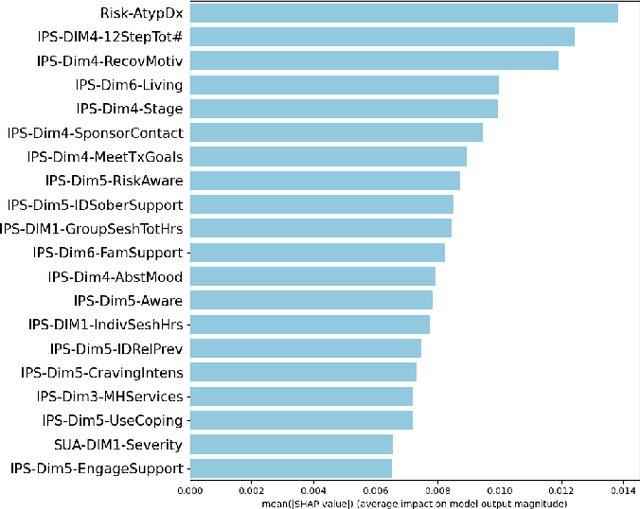
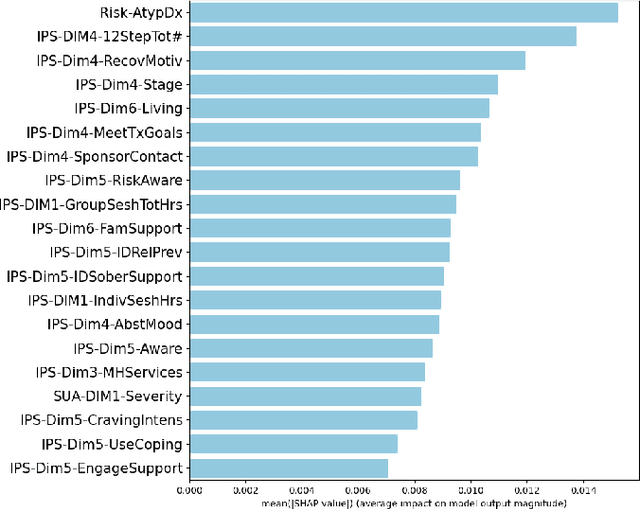
Fairness of machine learning models in healthcare has drawn increasing attention from clinicians, researchers, and even at the highest level of government. On the other hand, the importance of developing and deploying interpretable or explainable models has been demonstrated, and is essential to increasing the trustworthiness and likelihood of adoption of these models. The objective of this study was to develop and implement a framework for addressing both these issues - fairness and explainability. We propose an explainable fairness framework, first developing a model with optimized performance, and then using an in-processing approach to mitigate model biases relative to the sensitive attributes of race and sex. We then explore and visualize explanations of the model changes that lead to the fairness enhancement process through exploring the changes in importance of features. Our resulting-fairness enhanced models retain high sensitivity with improved fairness and explanations of the fairness-enhancement that may provide helpful insights for healthcare providers to guide clinical decision-making and resource allocation.
Classifying Cancer Stage with Open-Source Clinical Large Language Models
Apr 02, 2024Cancer stage classification is important for making treatment and care management plans for oncology patients. Information on staging is often included in unstructured form in clinical, pathology, radiology and other free-text reports in the electronic health record system, requiring extensive work to parse and obtain. To facilitate the extraction of this information, previous NLP approaches rely on labeled training datasets, which are labor-intensive to prepare. In this study, we demonstrate that without any labeled training data, open-source clinical large language models (LLMs) can extract pathologic tumor-node-metastasis (pTNM) staging information from real-world pathology reports. Our experiments compare LLMs and a BERT-based model fine-tuned using the labeled data. Our findings suggest that while LLMs still exhibit subpar performance in Tumor (T) classification, with the appropriate adoption of prompting strategies, they can achieve comparable performance on Metastasis (M) classification and improved performance on Node (N) classification.
Constructing Cross-lingual Consumer Health Vocabulary with Word-Embedding from Comparable User Generated Content
Jun 23, 2022

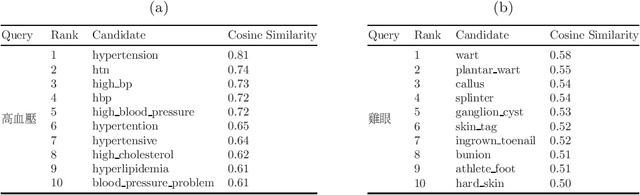
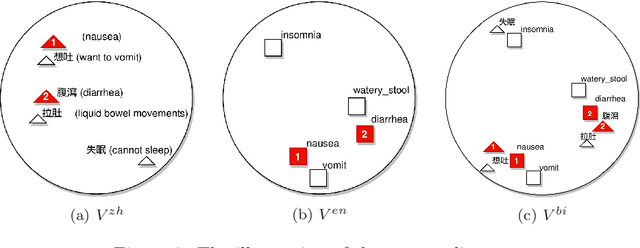
The online health community (OHC) is the primary channel for laypeople to share health information. To analyze the health consumer-generated content (HCGC) from the OHCs, identifying the colloquial medical expressions used by laypeople is a critical challenge. The open-access and collaborative consumer health vocabulary (OAC CHV) is the controlled vocabulary for addressing such a challenge. Nevertheless, OAC CHV is only available in English, limiting the applicability to other languages. This research aims to propose a cross-lingual automatic term recognition framework for extending the English OAC CHV into a cross-lingual one. Our framework requires an English HCGC corpus and a non-English (i.e., Chinese in this study) HCGC corpus as inputs. Two monolingual word vector spaces are determined using skip-gram algorithm so that each space encodes common word associations from laypeople within a language. Based on isometry assumption, the framework align two monolingual spaces into a bilingual word vector space, where we employ cosine similarity as a metric for identifying semantically similar words across languages. In the experiments, our framework demonstrates that it can effectively retrieve similar medical terms, including colloquial expressions, across languages and further facilitate compilation of cross-lingual CHV.