 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMediHive: A Decentralized Agent Collective for Medical Reasoning
Mar 28, 2026Large language models (LLMs) have revolutionized medical reasoning tasks, yet single-agent systems often falter on complex, interdisciplinary problems requiring robust handling of uncertainty and conflicting evidence. Multi-agent systems (MAS) leveraging LLMs enable collaborative intelligence, but prevailing centralized architectures suffer from scalability bottlenecks, single points of failure, and role confusion in resource-constrained environments. Decentralized MAS (D-MAS) promise enhanced autonomy and resilience via peer-to-peer interactions, but their application to high-stakes healthcare domains remains underexplored. We introduce MediHive, a novel decentralized multi-agent framework for medical question answering that integrates a shared memory pool with iterative fusion mechanisms. MediHive deploys LLM-based agents that autonomously self-assign specialized roles, conduct initial analyses, detect divergences through conditional evidence-based debates, and locally fuse peer insights over multiple rounds to achieve consensus. Empirically, MediHive outperforms single-LLM and centralized baselines on MedQA and PubMedQA datasets, attaining accuracies of 84.3% and 78.4%, respectively. Our work advances scalable, fault-tolerant D-MAS for medical AI, addressing key limitations of centralized designs while demonstrating superior performance in reasoning-intensive tasks.
Automated Clinical Problem Detection from SOAP Notes using a Collaborative Multi-Agent LLM Architecture
Aug 29, 2025



Accurate interpretation of clinical narratives is critical for patient care, but the complexity of these notes makes automation challenging. While Large Language Models (LLMs) show promise, single-model approaches can lack the robustness required for high-stakes clinical tasks. We introduce a collaborative multi-agent system (MAS) that models a clinical consultation team to address this gap. The system is tasked with identifying clinical problems by analyzing only the Subjective (S) and Objective (O) sections of SOAP notes, simulating the diagnostic reasoning process of synthesizing raw data into an assessment. A Manager agent orchestrates a dynamically assigned team of specialist agents who engage in a hierarchical, iterative debate to reach a consensus. We evaluated our MAS against a single-agent baseline on a curated dataset of 420 MIMIC-III notes. The dynamic multi-agent configuration demonstrated consistently improved performance in identifying congestive heart failure, acute kidney injury, and sepsis. Qualitative analysis of the agent debates reveals that this structure effectively surfaces and weighs conflicting evidence, though it can occasionally be susceptible to groupthink. By modeling a clinical team's reasoning process, our system offers a promising path toward more accurate, robust, and interpretable clinical decision support tools.
MoE-Health: A Mixture of Experts Framework for Robust Multimodal Healthcare Prediction
Aug 29, 2025Healthcare systems generate diverse multimodal data, including Electronic Health Records (EHR), clinical notes, and medical images. Effectively leveraging this data for clinical prediction is challenging, particularly as real-world samples often present with varied or incomplete modalities. Existing approaches typically require complete modality data or rely on manual selection strategies, limiting their applicability in real-world clinical settings where data availability varies across patients and institutions. To address these limitations, we propose MoE-Health, a novel Mixture of Experts framework designed for robust multimodal fusion in healthcare prediction. MoE-Health architecture is specifically developed to handle samples with differing modalities and improve performance on critical clinical tasks. By leveraging specialized expert networks and a dynamic gating mechanism, our approach dynamically selects and combines relevant experts based on available data modalities, enabling flexible adaptation to varying data availability scenarios. We evaluate MoE-Health on the MIMIC-IV dataset across three critical clinical prediction tasks: in-hospital mortality prediction, long length of stay, and hospital readmission prediction. Experimental results demonstrate that MoE-Health achieves superior performance compared to existing multimodal fusion methods while maintaining robustness across different modality availability patterns. The framework effectively integrates multimodal information, offering improved predictive performance and robustness in handling heterogeneous and incomplete healthcare data, making it particularly suitable for deployment in diverse healthcare environments with heterogeneous data availability.
Collaboration among Multiple Large Language Models for Medical Question Answering
May 22, 2025Empowered by vast internal knowledge reservoir, the new generation of large language models (LLMs) demonstrate untapped potential to tackle medical tasks. However, there is insufficient effort made towards summoning up a synergic effect from multiple LLMs' expertise and background. In this study, we propose a multi-LLM collaboration framework tailored on a medical multiple-choice questions dataset. Through post-hoc analysis on 3 pre-trained LLM participants, our framework is proved to boost all LLMs reasoning ability as well as alleviate their divergence among questions. We also measure an LLM's confidence when it confronts with adversary opinions from other LLMs and observe a concurrence between LLM's confidence and prediction accuracy.
Balancing Fairness and Performance in Healthcare AI: A Gradient Reconciliation Approach
Apr 19, 2025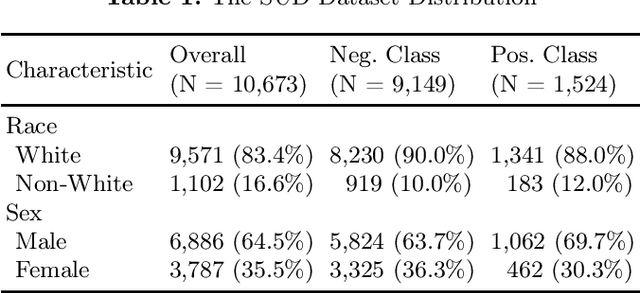
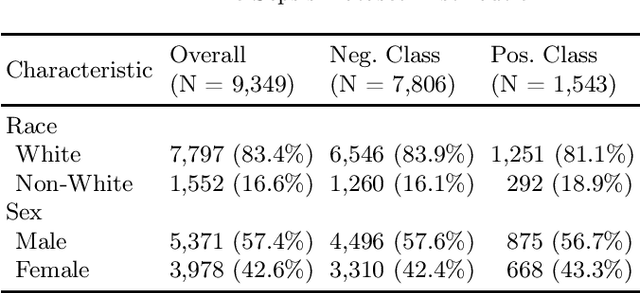
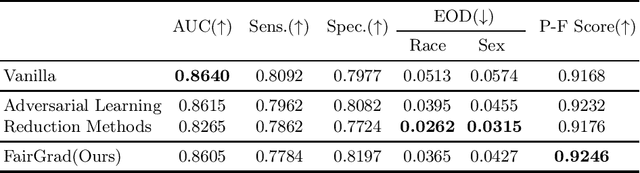
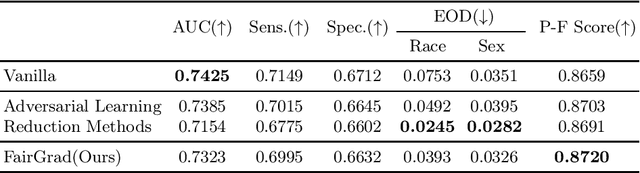
The rapid growth of healthcare data and advances in computational power have accelerated the adoption of artificial intelligence (AI) in medicine. However, AI systems deployed without explicit fairness considerations risk exacerbating existing healthcare disparities, potentially leading to inequitable resource allocation and diagnostic disparities across demographic subgroups. To address this challenge, we propose FairGrad, a novel gradient reconciliation framework that automatically balances predictive performance and multi-attribute fairness optimization in healthcare AI models. Our method resolves conflicting optimization objectives by projecting each gradient vector onto the orthogonal plane of the others, thereby regularizing the optimization trajectory to ensure equitable consideration of all objectives. Evaluated on diverse real-world healthcare datasets and predictive tasks - including Substance Use Disorder (SUD) treatment and sepsis mortality - FairGrad achieved statistically significant improvements in multi-attribute fairness metrics (e.g., equalized odds) while maintaining competitive predictive accuracy. These results demonstrate the viability of harmonizing fairness and utility in mission-critical medical AI applications.
Beyond Self-Consistency: Ensemble Reasoning Boosts Consistency and Accuracy of LLMs in Cancer Staging
Apr 19, 2024Advances in large language models (LLMs) have encouraged their adoption in the healthcare domain where vital clinical information is often contained in unstructured notes. Cancer staging status is available in clinical reports, but it requires natural language processing to extract the status from the unstructured text. With the advance in clinical-oriented LLMs, it is promising to extract such status without extensive efforts in training the algorithms. Prompting approaches of the pre-trained LLMs that elicit a model's reasoning process, such as chain-of-thought, may help to improve the trustworthiness of the generated responses. Using self-consistency further improves model performance, but often results in inconsistent generations across the multiple reasoning paths. In this study, we propose an ensemble reasoning approach with the aim of improving the consistency of the model generations. Using an open access clinical large language model to determine the pathologic cancer stage from real-world pathology reports, we show that the ensemble reasoning approach is able to improve both the consistency and performance of the LLM in determining cancer stage, thereby demonstrating the potential to use these models in clinical or other domains where reliability and trustworthiness are critical.
Explainable AI for Fair Sepsis Mortality Predictive Model
Apr 19, 2024Artificial intelligence supports healthcare professionals with predictive modeling, greatly transforming clinical decision-making. This study addresses the crucial need for fairness and explainability in AI applications within healthcare to ensure equitable outcomes across diverse patient demographics. By focusing on the predictive modeling of sepsis-related mortality, we propose a method that learns a performance-optimized predictive model and then employs the transfer learning process to produce a model with better fairness. Our method also introduces a novel permutation-based feature importance algorithm aiming at elucidating the contribution of each feature in enhancing fairness on predictions. Unlike existing explainability methods concentrating on explaining feature contribution to predictive performance, our proposed method uniquely bridges the gap in understanding how each feature contributes to fairness. This advancement is pivotal, given sepsis's significant mortality rate and its role in one-third of hospital deaths. Our method not only aids in identifying and mitigating biases within the predictive model but also fosters trust among healthcare stakeholders by improving the transparency and fairness of model predictions, thereby contributing to more equitable and trustworthy healthcare delivery.
An ExplainableFair Framework for Prediction of Substance Use Disorder Treatment Completion
Apr 04, 2024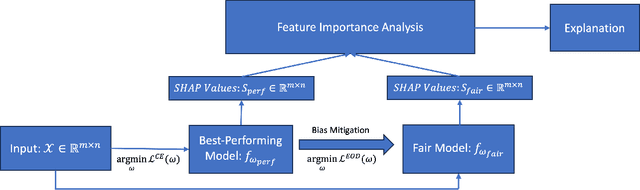
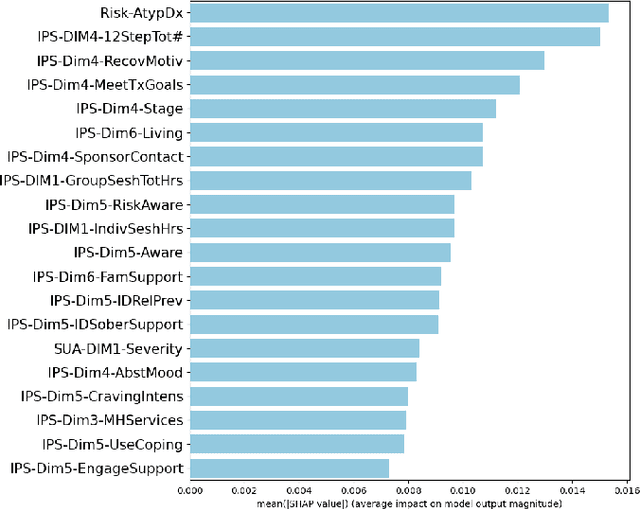
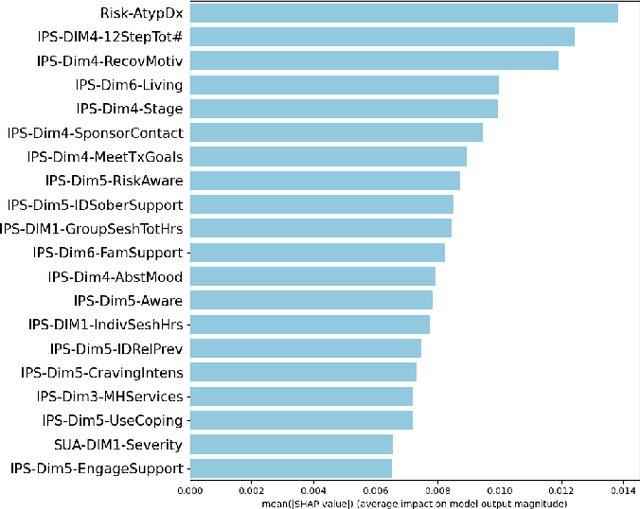
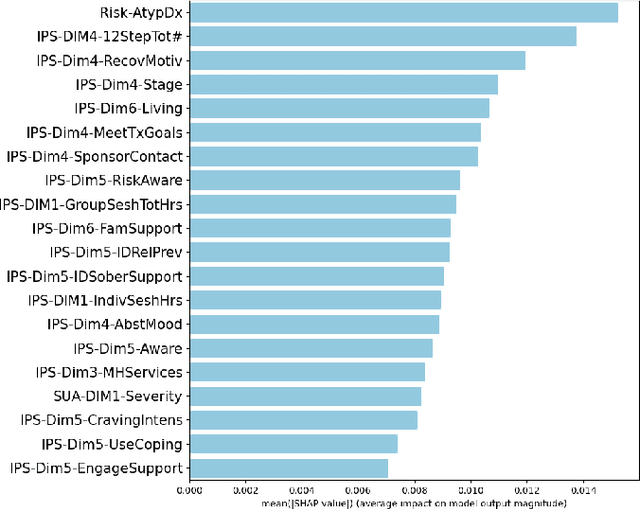
Fairness of machine learning models in healthcare has drawn increasing attention from clinicians, researchers, and even at the highest level of government. On the other hand, the importance of developing and deploying interpretable or explainable models has been demonstrated, and is essential to increasing the trustworthiness and likelihood of adoption of these models. The objective of this study was to develop and implement a framework for addressing both these issues - fairness and explainability. We propose an explainable fairness framework, first developing a model with optimized performance, and then using an in-processing approach to mitigate model biases relative to the sensitive attributes of race and sex. We then explore and visualize explanations of the model changes that lead to the fairness enhancement process through exploring the changes in importance of features. Our resulting-fairness enhanced models retain high sensitivity with improved fairness and explanations of the fairness-enhancement that may provide helpful insights for healthcare providers to guide clinical decision-making and resource allocation.
Classifying Cancer Stage with Open-Source Clinical Large Language Models
Apr 02, 2024Cancer stage classification is important for making treatment and care management plans for oncology patients. Information on staging is often included in unstructured form in clinical, pathology, radiology and other free-text reports in the electronic health record system, requiring extensive work to parse and obtain. To facilitate the extraction of this information, previous NLP approaches rely on labeled training datasets, which are labor-intensive to prepare. In this study, we demonstrate that without any labeled training data, open-source clinical large language models (LLMs) can extract pathologic tumor-node-metastasis (pTNM) staging information from real-world pathology reports. Our experiments compare LLMs and a BERT-based model fine-tuned using the labeled data. Our findings suggest that while LLMs still exhibit subpar performance in Tumor (T) classification, with the appropriate adoption of prompting strategies, they can achieve comparable performance on Metastasis (M) classification and improved performance on Node (N) classification.
Constructing Cross-lingual Consumer Health Vocabulary with Word-Embedding from Comparable User Generated Content
Jun 23, 2022

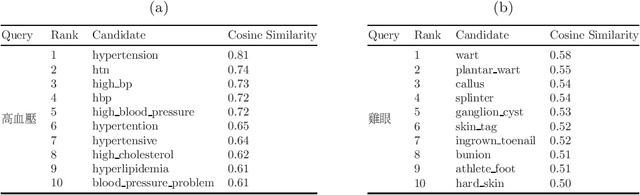
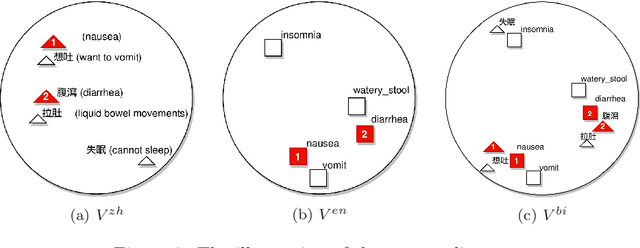
The online health community (OHC) is the primary channel for laypeople to share health information. To analyze the health consumer-generated content (HCGC) from the OHCs, identifying the colloquial medical expressions used by laypeople is a critical challenge. The open-access and collaborative consumer health vocabulary (OAC CHV) is the controlled vocabulary for addressing such a challenge. Nevertheless, OAC CHV is only available in English, limiting the applicability to other languages. This research aims to propose a cross-lingual automatic term recognition framework for extending the English OAC CHV into a cross-lingual one. Our framework requires an English HCGC corpus and a non-English (i.e., Chinese in this study) HCGC corpus as inputs. Two monolingual word vector spaces are determined using skip-gram algorithm so that each space encodes common word associations from laypeople within a language. Based on isometry assumption, the framework align two monolingual spaces into a bilingual word vector space, where we employ cosine similarity as a metric for identifying semantically similar words across languages. In the experiments, our framework demonstrates that it can effectively retrieve similar medical terms, including colloquial expressions, across languages and further facilitate compilation of cross-lingual CHV.