 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDissecting Judicial Reasoning in U.S. Copyright Damage Awards
Jan 14, 2026Judicial reasoning in copyright damage awards poses a core challenge for computational legal analysis. Although federal courts follow the 1976 Copyright Act, their interpretations and factor weightings vary widely across jurisdictions. This inconsistency creates unpredictability for litigants and obscures the empirical basis of legal decisions. This research introduces a novel discourse-based Large Language Model (LLM) methodology that integrates Rhetorical Structure Theory (RST) with an agentic workflow to extract and quantify previously opaque reasoning patterns from judicial opinions. Our framework addresses a major gap in empirical legal scholarship by parsing opinions into hierarchical discourse structures and using a three-stage pipeline, i.e., Dataset Construction, Discourse Analysis, and Agentic Feature Extraction. This pipeline identifies reasoning components and extract feature labels with corresponding discourse subtrees. In analyzing copyright damage rulings, we show that discourse-augmented LLM analysis outperforms traditional methods while uncovering unquantified variations in factor weighting across circuits. These findings offer both methodological advances in computational legal analysis and practical insights into judicial reasoning, with implications for legal practitioners seeking predictive tools, scholars studying legal principle application, and policymakers confronting inconsistencies in copyright law.
On Exploring the Reasoning Capability of Large Language Models with Knowledge Graphs
Dec 01, 2023
This paper examines the capacity of LLMs to reason with knowledge graphs using their internal knowledge graph, i.e., the knowledge graph they learned during pre-training. Two research questions are formulated to investigate the accuracy of LLMs in recalling information from pre-training knowledge graphs and their ability to infer knowledge graph relations from context. To address these questions, we employ LLMs to perform four distinct knowledge graph reasoning tasks. Furthermore, we identify two types of hallucinations that may occur during knowledge reasoning with LLMs: content and ontology hallucination. Our experimental results demonstrate that LLMs can successfully tackle both simple and complex knowledge graph reasoning tasks from their own memory, as well as infer from input context.
On Predicting Personal Values of Social Media Users using Community-Specific Language Features and Personal Value Correlation
Jul 16, 2020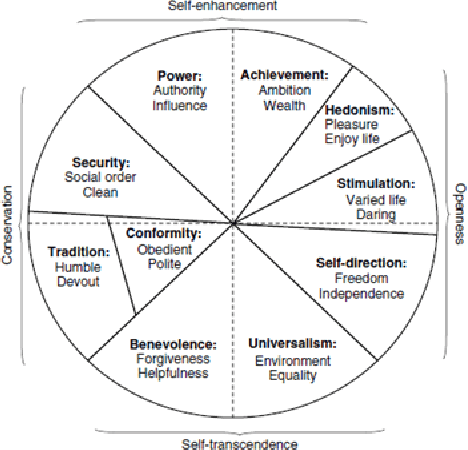
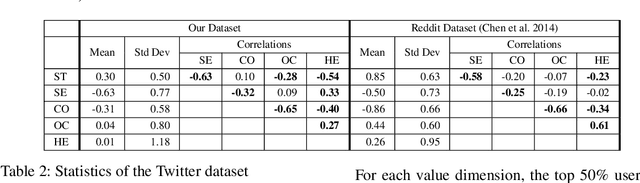
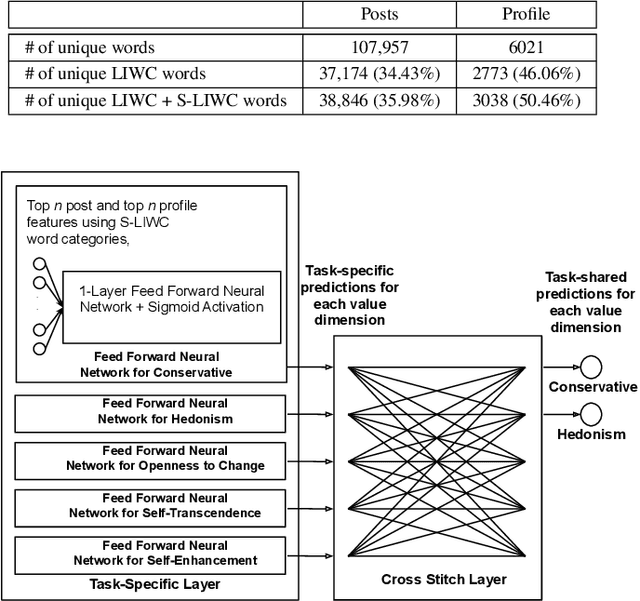
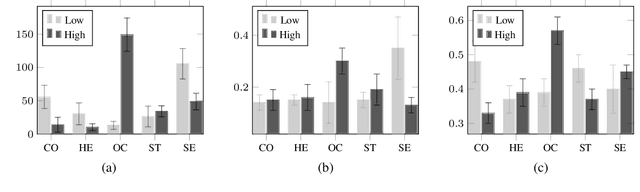
Personal values have significant influence on individuals' behaviors, preferences, and decision making. It is therefore not a surprise that personal values of a person could influence his or her social media content and activities. Instead of getting users to complete personal value questionnaire, researchers have looked into a non-intrusive and highly scalable approach to predict personal values using user-generated social media data. Nevertheless, geographical differences in word usage and profile information are issues to be addressed when designing such prediction models. In this work, we focus on analyzing Singapore users' personal values, and developing effective models to predict their personal values using their Facebook data. These models leverage on word categories in Linguistic Inquiry and Word Count (LIWC) and correlations among personal values. The LIWC word categories are adapted to non-English word use in Singapore. We incorporate the correlations among personal values into our proposed Stack Model consisting of a task-specific layer of base models and a cross-stitch layer model. Through experiments, we show that our proposed model predicts personal values with considerable improvement of accuracy over the previous works. Moreover, we use the stack model to predict the personal values of a large community of Twitter users using their public tweet content and empirically derive several interesting findings about their online behavior consistent with earlier findings in the social science and social media literature.
JPLink: On Linking Jobs to Vocational Interest Types
Feb 06, 2020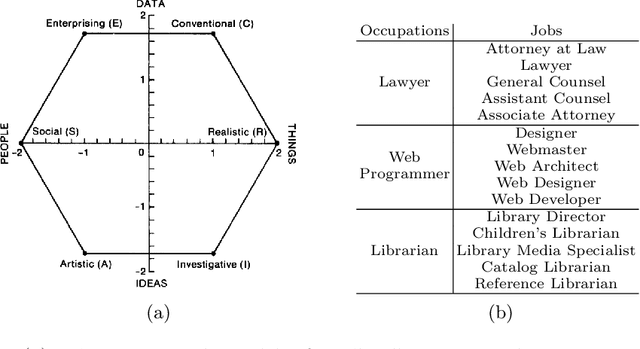
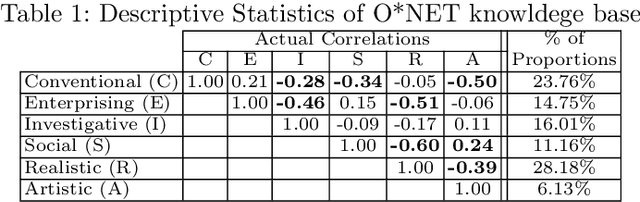
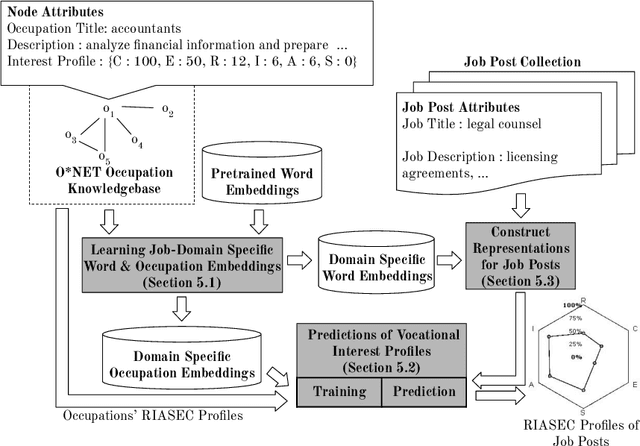
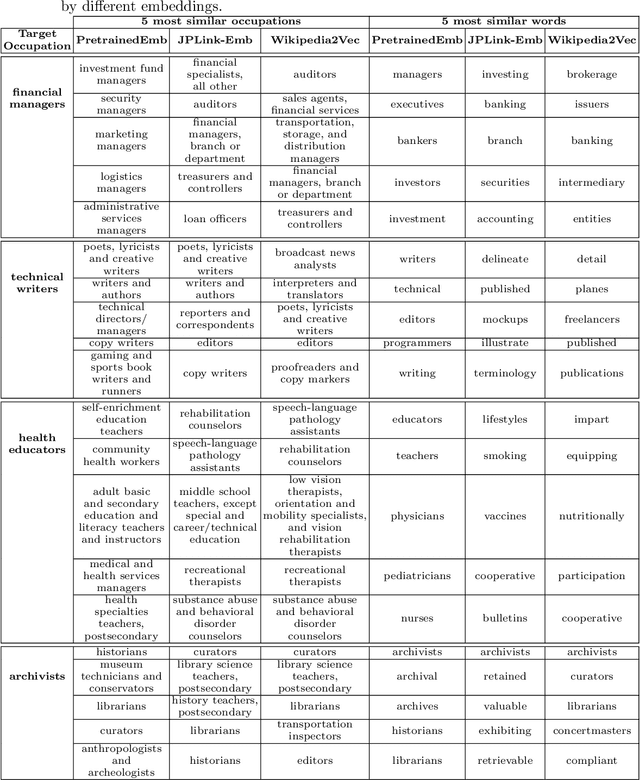
Linking job seekers with relevant jobs requires matching based on not only skills, but also personality types. Although the Holland Code also known as RIASEC has frequently been used to group people by their suitability for six different categories of occupations, the RIASEC category labels of individual jobs are often not found in job posts. This is attributed to significant manual efforts required for assigning job posts with RIASEC labels. To cope with assigning massive number of jobs with RIASEC labels, we propose JPLink, a machine learning approach using the text content in job titles and job descriptions. JPLink exploits domain knowledge available in an occupation-specific knowledge base known as O*NET to improve feature representation of job posts. To incorporate relative ranking of RIASEC labels of each job, JPLink proposes a listwise loss function inspired by learning to rank. Both our quantitative and qualitative evaluations show that JPLink outperforms conventional baselines. We conduct an error analysis on JPLink's predictions to show that it can uncover label errors in existing job posts.