 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Domain-agnostic Fake News Detection using Multi-modal Weak Signals
May 18, 2023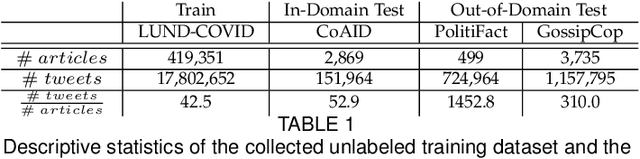

The emergence of social media as one of the main platforms for people to access news has enabled the wide dissemination of fake news. This has motivated numerous studies on automating fake news detection. Although there have been limited attempts at unsupervised fake news detection, their performance suffers due to not exploiting the knowledge from various modalities related to news records and due to the presence of various latent biases in the existing news datasets. To address these limitations, this work proposes an effective framework for unsupervised fake news detection, which first embeds the knowledge available in four modalities in news records and then proposes a novel noise-robust self-supervised learning technique to identify the veracity of news records from the multi-modal embeddings. Also, we propose a novel technique to construct news datasets minimizing the latent biases in existing news datasets. Following the proposed approach for dataset construction, we produce a Large-scale Unlabelled News Dataset consisting 419,351 news articles related to COVID-19, acronymed as LUND-COVID. We trained the proposed unsupervised framework using LUND-COVID to exploit the potential of large datasets, and evaluate it using a set of existing labelled datasets. Our results show that the proposed unsupervised framework largely outperforms existing unsupervised baselines for different tasks such as multi-modal fake news detection, fake news early detection and few-shot fake news detection, while yielding notable improvements for unseen domains during training.
Embracing Domain Differences in Fake News: Cross-domain Fake News Detection using Multi-modal Data
Feb 24, 2021


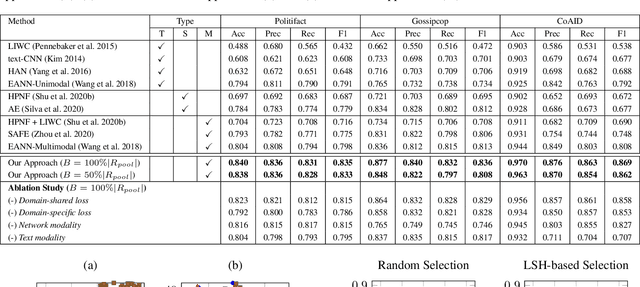
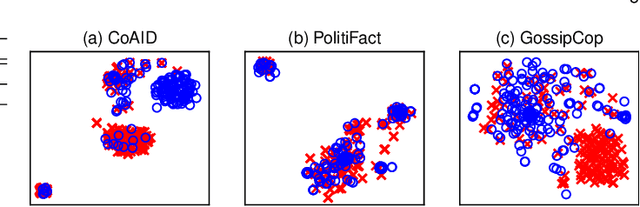
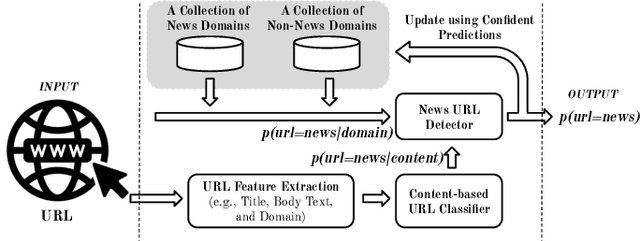
With the rapid evolution of social media, fake news has become a significant social problem, which cannot be addressed in a timely manner using manual investigation. This has motivated numerous studies on automating fake news detection. Most studies explore supervised training models with different modalities (e.g., text, images, and propagation networks) of news records to identify fake news. However, the performance of such techniques generally drops if news records are coming from different domains (e.g., politics, entertainment), especially for domains that are unseen or rarely-seen during training. As motivation, we empirically show that news records from different domains have significantly different word usage and propagation patterns. Furthermore, due to the sheer volume of unlabelled news records, it is challenging to select news records for manual labelling so that the domain-coverage of the labelled dataset is maximized. Hence, this work: (1) proposes a novel framework that jointly preserves domain-specific and cross-domain knowledge in news records to detect fake news from different domains; and (2) introduces an unsupervised technique to select a set of unlabelled informative news records for manual labelling, which can be ultimately used to train a fake news detection model that performs well for many domains while minimizing the labelling cost. Our experiments show that the integration of the proposed fake news model and the selective annotation approach achieves state-of-the-art performance for cross-domain news datasets, while yielding notable improvements for rarely-appearing domains in news datasets.
METEOR: Learning Memory and Time Efficient Representations from Multi-modal Data Streams
Jul 23, 2020
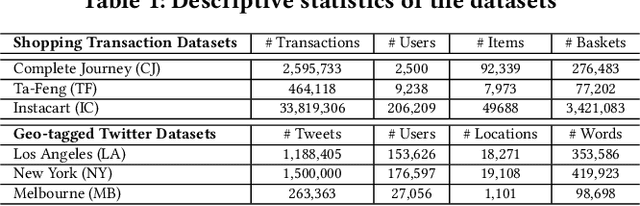
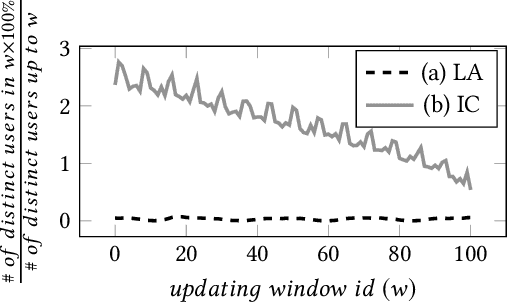
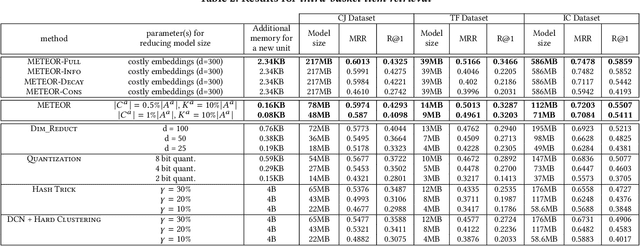
Many learning tasks involve multi-modal data streams, where continuous data from different modes convey a comprehensive description about objects. A major challenge in this context is how to efficiently interpret multi-modal information in complex environments. This has motivated numerous studies on learning unsupervised representations from multi-modal data streams. These studies aim to understand higher-level contextual information (e.g., a Twitter message) by jointly learning embeddings for the lower-level semantic units in different modalities (e.g., text, user, and location of a Twitter message). However, these methods directly associate each low-level semantic unit with a continuous embedding vector, which results in high memory requirements. Hence, deploying and continuously learning such models in low-memory devices (e.g., mobile devices) becomes a problem. To address this problem, we present METEOR, a novel MEmory and Time Efficient Online Representation learning technique, which: (1) learns compact representations for multi-modal data by sharing parameters within semantically meaningful groups and preserves the domain-agnostic semantics; (2) can be accelerated using parallel processes to accommodate different stream rates while capturing the temporal changes of the units; and (3) can be easily extended to capture implicit/explicit external knowledge related to multi-modal data streams. We evaluate METEOR using two types of multi-modal data streams (i.e., social media streams and shopping transaction streams) to demonstrate its ability to adapt to different domains. Our results show that METEOR preserves the quality of the representations while reducing memory usage by around 80% compared to the conventional memory-intensive embeddings.
On Predicting Personal Values of Social Media Users using Community-Specific Language Features and Personal Value Correlation
Jul 16, 2020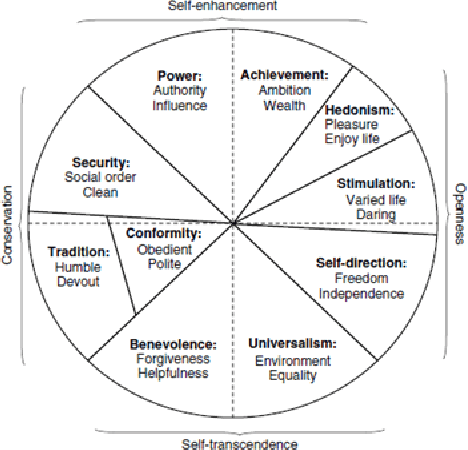
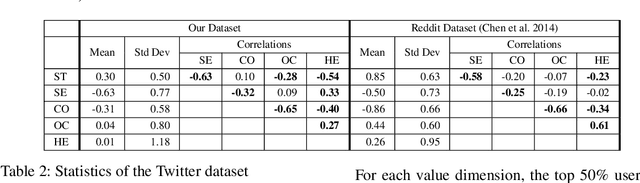
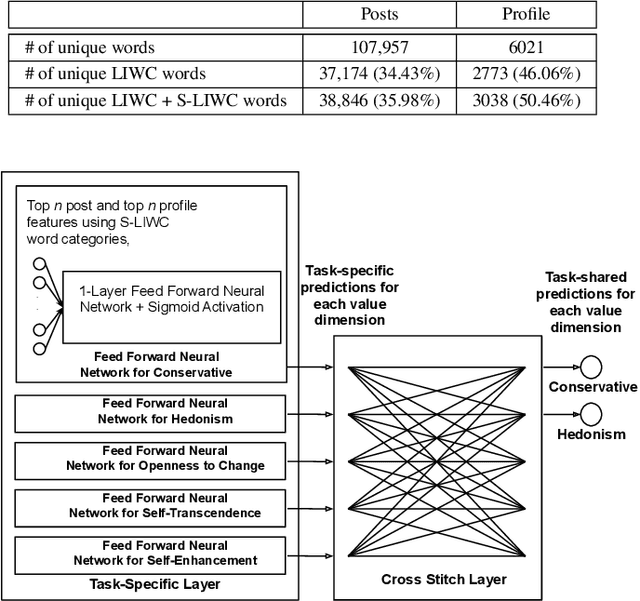
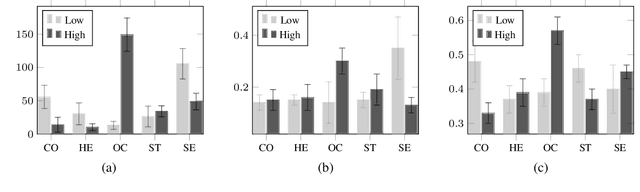
Personal values have significant influence on individuals' behaviors, preferences, and decision making. It is therefore not a surprise that personal values of a person could influence his or her social media content and activities. Instead of getting users to complete personal value questionnaire, researchers have looked into a non-intrusive and highly scalable approach to predict personal values using user-generated social media data. Nevertheless, geographical differences in word usage and profile information are issues to be addressed when designing such prediction models. In this work, we focus on analyzing Singapore users' personal values, and developing effective models to predict their personal values using their Facebook data. These models leverage on word categories in Linguistic Inquiry and Word Count (LIWC) and correlations among personal values. The LIWC word categories are adapted to non-English word use in Singapore. We incorporate the correlations among personal values into our proposed Stack Model consisting of a task-specific layer of base models and a cross-stitch layer model. Through experiments, we show that our proposed model predicts personal values with considerable improvement of accuracy over the previous works. Moreover, we use the stack model to predict the personal values of a large community of Twitter users using their public tweet content and empirically derive several interesting findings about their online behavior consistent with earlier findings in the social science and social media literature.
OMBA: User-Guided Product Representations for Online Market Basket Analysis
Jun 18, 2020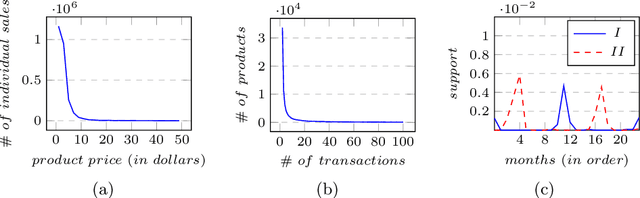


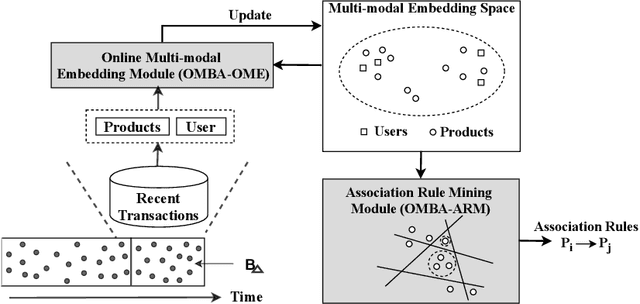
Market Basket Analysis (MBA) is a popular technique to identify associations between products, which is crucial for business decision making. Previous studies typically adopt conventional frequent itemset mining algorithms to perform MBA. However, they generally fail to uncover rarely occurring associations among the products at their most granular level. Also, they have limited ability to capture temporal dynamics in associations between products. Hence, we propose OMBA, a novel representation learning technique for Online Market Basket Analysis. OMBA jointly learns representations for products and users such that they preserve the temporal dynamics of product-to-product and user-to-product associations. Subsequently, OMBA proposes a scalable yet effective online method to generate products' associations using their representations. Our extensive experiments on three real-world datasets show that OMBA outperforms state-of-the-art methods by as much as 21%, while emphasizing rarely occurring strong associations and effectively capturing temporal changes in associations.
JPLink: On Linking Jobs to Vocational Interest Types
Feb 06, 2020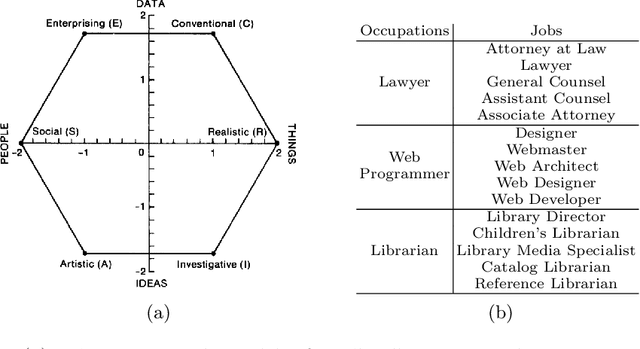
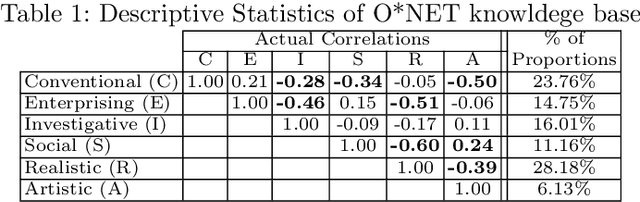
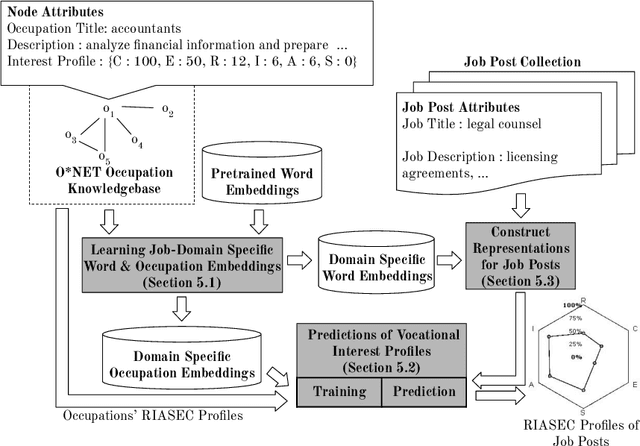
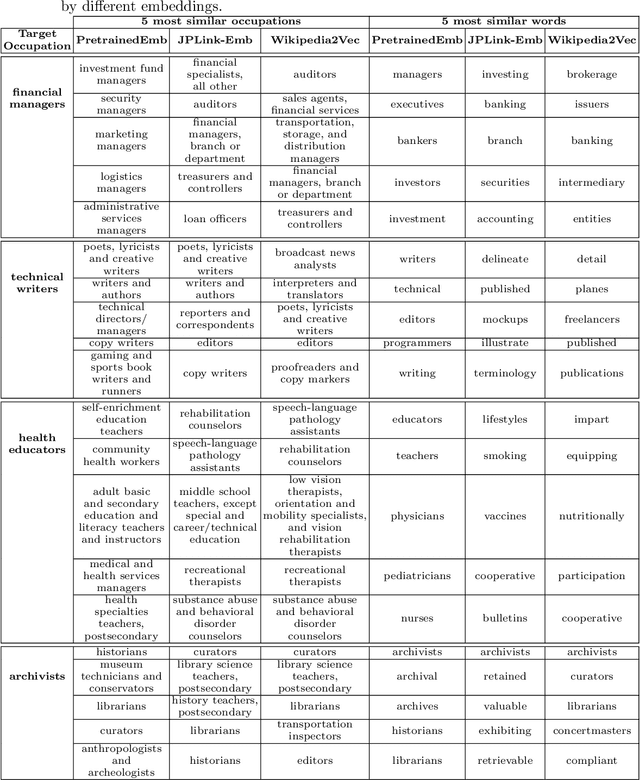
Linking job seekers with relevant jobs requires matching based on not only skills, but also personality types. Although the Holland Code also known as RIASEC has frequently been used to group people by their suitability for six different categories of occupations, the RIASEC category labels of individual jobs are often not found in job posts. This is attributed to significant manual efforts required for assigning job posts with RIASEC labels. To cope with assigning massive number of jobs with RIASEC labels, we propose JPLink, a machine learning approach using the text content in job titles and job descriptions. JPLink exploits domain knowledge available in an occupation-specific knowledge base known as O*NET to improve feature representation of job posts. To incorporate relative ranking of RIASEC labels of each job, JPLink proposes a listwise loss function inspired by learning to rank. Both our quantitative and qualitative evaluations show that JPLink outperforms conventional baselines. We conduct an error analysis on JPLink's predictions to show that it can uncover label errors in existing job posts.
USTAR: Online Multimodal Embedding for Modeling User-Guided Spatiotemporal Activity
Oct 23, 2019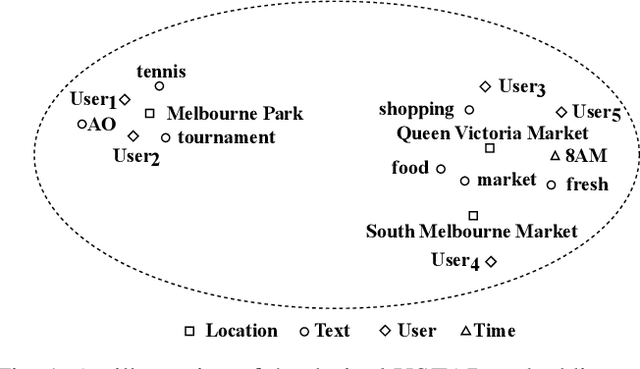
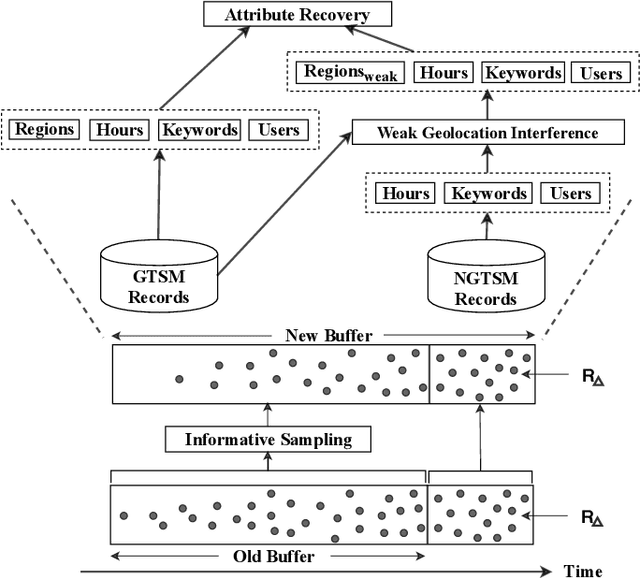
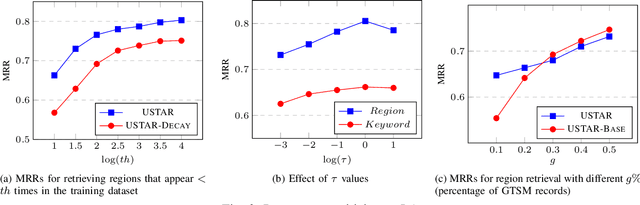
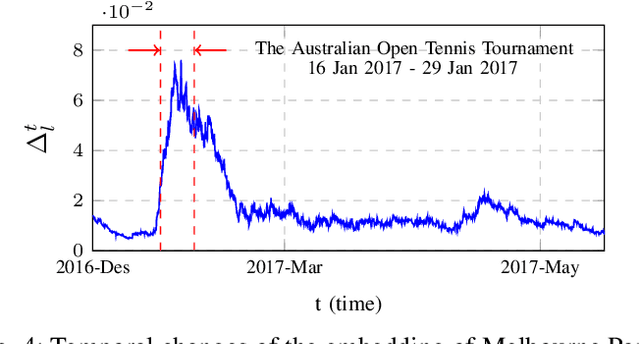
Building spatiotemporal activity models for people's activities in urban spaces is important for understanding the ever-increasing complexity of urban dynamics. With the emergence of Geo-Tagged Social Media (GTSM) records, previous studies demonstrate the potential of GTSM records for spatiotemporal activity modeling. State-of-the-art methods for this task embed different modalities (location, time, and text) of GTSM records into a single embedding space. However, they ignore Non-GeoTagged Social Media (NGTSM) records, which generally account for the majority of posts (e.g., more than 95\% in Twitter), and could represent a great source of information to alleviate the sparsity of GTSM records. Furthermore, in the current spatiotemporal embedding techniques, less focus has been given to the users, who exhibit spatially motivated behaviors. To bridge this research gap, this work proposes USTAR, a novel online learning method for User-guided SpatioTemporal Activity Representation, which (1) embeds locations, time, and text along with users into the same embedding space to capture their correlations; (2) uses a novel collaborative filtering approach based on two different empirically studied user behaviors to incorporate both NGTSM and GTSM records in learning; and (3) introduces a novel sampling technique to learn spatiotemporal representations in an online fashion to accommodate recent information into the embedding space, while avoiding overfitting to recent records and frequently appearing units in social media streams. Our results show that USTAR substantially improves the state-of-the-art for region retrieval and keyword retrieval and its potential to be applied to other downstream applications such as local event detection.