 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMETEOR: Learning Memory and Time Efficient Representations from Multi-modal Data Streams
Paper and Code
Jul 23, 2020
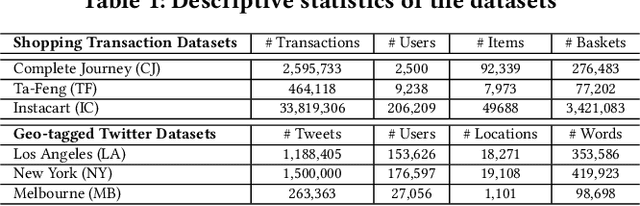
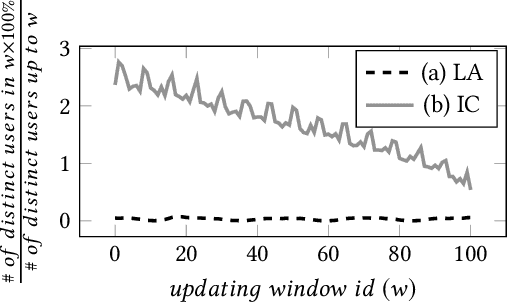
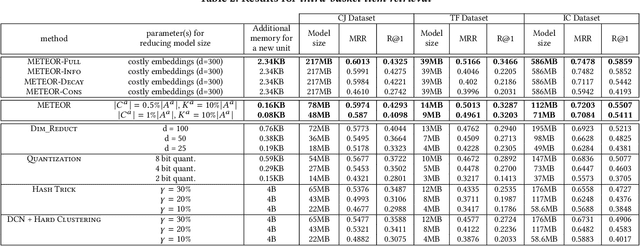
Many learning tasks involve multi-modal data streams, where continuous data from different modes convey a comprehensive description about objects. A major challenge in this context is how to efficiently interpret multi-modal information in complex environments. This has motivated numerous studies on learning unsupervised representations from multi-modal data streams. These studies aim to understand higher-level contextual information (e.g., a Twitter message) by jointly learning embeddings for the lower-level semantic units in different modalities (e.g., text, user, and location of a Twitter message). However, these methods directly associate each low-level semantic unit with a continuous embedding vector, which results in high memory requirements. Hence, deploying and continuously learning such models in low-memory devices (e.g., mobile devices) becomes a problem. To address this problem, we present METEOR, a novel MEmory and Time Efficient Online Representation learning technique, which: (1) learns compact representations for multi-modal data by sharing parameters within semantically meaningful groups and preserves the domain-agnostic semantics; (2) can be accelerated using parallel processes to accommodate different stream rates while capturing the temporal changes of the units; and (3) can be easily extended to capture implicit/explicit external knowledge related to multi-modal data streams. We evaluate METEOR using two types of multi-modal data streams (i.e., social media streams and shopping transaction streams) to demonstrate its ability to adapt to different domains. Our results show that METEOR preserves the quality of the representations while reducing memory usage by around 80% compared to the conventional memory-intensive embeddings.