 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCrowdsourcing Lexical Diversity
Oct 30, 2024



Lexical-semantic resources (LSRs), such as online lexicons or wordnets, are fundamental for natural language processing applications. In many languages, however, such resources suffer from quality issues: incorrect entries, incompleteness, but also, the rarely addressed issue of bias towards the English language and Anglo-Saxon culture. Such bias manifests itself in the absence of concepts specific to the language or culture at hand, the presence of foreign (Anglo-Saxon) concepts, as well as in the lack of an explicit indication of untranslatability, also known as cross-lingual \emph{lexical gaps}, when a term has no equivalent in another language. This paper proposes a novel crowdsourcing methodology for reducing bias in LSRs. Crowd workers compare lexemes from two languages, focusing on domains rich in lexical diversity, such as kinship or food. Our LingoGap crowdsourcing tool facilitates comparisons through microtasks identifying equivalent terms, language-specific terms, and lexical gaps across languages. We validated our method by applying it to two case studies focused on food-related terminology: (1) English and Arabic, and (2) Standard Indonesian and Banjarese. These experiments identified 2,140 lexical gaps in the first case study and 951 in the second. The success of these experiments confirmed the usability of our method and tool for future large-scale lexicon enrichment tasks.
Building Interoperable Electronic Health Records as Purpose-Driven Knowledge Graphs
May 10, 2023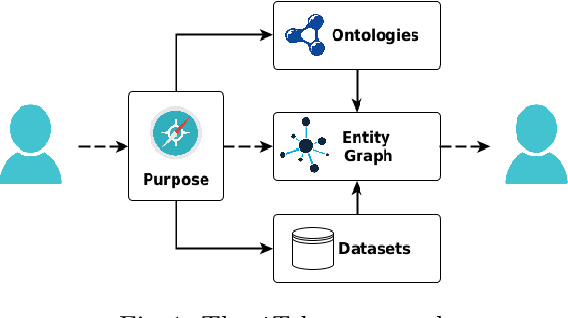

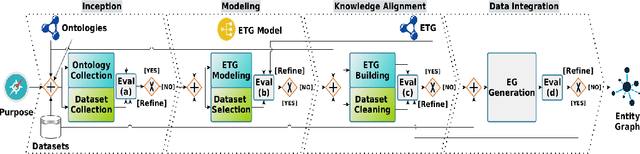

When building a new application we are increasingly confronted with the need of reusing and integrating pre-existing knowledge. Nevertheless, it is a fact that this prior knowledge is virtually impossible to reuse as-is. This is true also in domains, e.g., eHealth, where a lot of effort has been put into developing high-quality standards and reference ontologies, e.g. FHIR1. In this paper, we propose an integrated methodology, called iTelos, which enables data and knowledge reuse towards the construction of Interoperable Electronic Health Records (iEHR). The key intuition is that the data level and the schema level of an application should be developed independently, thus allowing for maximum flexibility in the reuse of the prior knowledge, but under the overall guidance of the needs to be satisfied, formalized as competence queries. This intuition is implemented by codifying all the requirements, including those concerning reuse, as part of a purpose defined a priori, which is then used to drive a middle-out development process where the application schema and data are continuously aligned. The proposed methodology is validated through its application to a large-scale case study.
* DSAI SPRINGER BOOK. arXiv admin note: text overlap with arXiv:2105.09418
Representing Interlingual Meaning in Lexical Databases
Jan 22, 2023In today's multilingual lexical databases, the majority of the world's languages are under-represented. Beyond a mere issue of resource incompleteness, we show that existing lexical databases have structural limitations that result in a reduced expressivity on culturally-specific words and in mapping them across languages. In particular, the lexical meaning space of dominant languages, such as English, is represented more accurately while linguistically or culturally diverse languages are mapped in an approximate manner. Our paper assesses state-of-the-art multilingual lexical databases and evaluates their strengths and limitations with respect to their expressivity on lexical phenomena of linguistic diversity.