 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFineMolTex: Towards Fine-grained Molecular Graph-Text Pre-training
Paper and Code
Sep 21, 2024
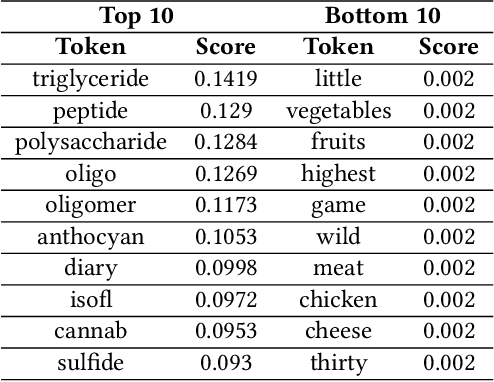
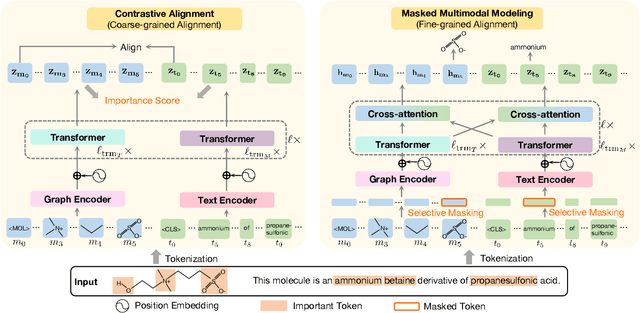

Understanding molecular structure and related knowledge is crucial for scientific research. Recent studies integrate molecular graphs with their textual descriptions to enhance molecular representation learning. However, they focus on the whole molecular graph and neglect frequently occurring subgraphs, known as motifs,which are essential for determining molecular properties. Without such fine-grained knowledge, these models struggle to generalize to unseen molecules and tasks that require motif-level insights. To bridge this gap, we propose FineMolTex, a novel Fine-grained Molecular graph-Text pre-training framework to jointly learn coarse-grained molecule-level knowledge and fine-grained motif-level knowledge. Specifically, FineMolTex consists of two pre-training tasks: a contrastive alignment task for coarse-grained matching and a masked multi-modal modeling task for fine-grained matching. In particular, the latter predicts the labels of masked motifs and words, leveraging insights from each other, thereby enabling FineMolTex to understand the fine-grained matching between motifs and words. Finally, we conduct extensive experiments across three downstream tasks, achieving up to 230% improvement in the text-based molecule editing task. Additionally, our case studies reveal that FineMolTex successfully captures fine-grained knowledge, potentially offering valuable insights for drug discovery and catalyst design.