 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLM-based MOFs Synthesis Condition Extraction using Few-Shot Demonstrations
Aug 06, 2024



The extraction of Metal-Organic Frameworks (MOFs) synthesis conditions from literature text has been challenging but crucial for the logical design of new MOFs with desirable functionality. The recent advent of large language models (LLMs) provides disruptively new solution to this long-standing problem and latest researches have reported over 90% F1 in extracting correct conditions from MOFs literature. We argue in this paper that most existing synthesis extraction practices with LLMs stay with the primitive zero-shot learning, which could lead to downgraded extraction and application performance due to the lack of specialized knowledge. This work pioneers and optimizes the few-shot in-context learning paradigm for LLM extraction of material synthesis conditions. First, we propose a human-AI joint data curation process to secure high-quality ground-truth demonstrations for few-shot learning. Second, we apply a BM25 algorithm based on the retrieval-augmented generation (RAG) technique to adaptively select few-shot demonstrations for each MOF's extraction. Over a dataset randomly sampled from 84,898 well-defined MOFs, the proposed few-shot method achieves much higher average F1 performance (0.93 vs. 0.81, +14.8%) than the native zero-shot LLM using the same GPT-4 model, under fully automatic evaluation that are more objective than the previous human evaluation. The proposed method is further validated through real-world material experiments: compared with the baseline zero-shot LLM, the proposed few-shot approach increases the MOFs structural inference performance (R^2) by 29.4% in average.
Dr.E Bridges Graphs with Large Language Models through Words
Jun 19, 2024



Significant efforts have been directed toward integrating powerful Large Language Models (LLMs) with diverse modalities, particularly focusing on the fusion of vision, language, and audio data. However, the graph-structured data, inherently rich in structural and domain-specific knowledge, have not yet been gracefully adapted to LLMs. Existing methods either describe the graph with raw text, suffering the loss of graph structural information, or feed Graph Neural Network (GNN) embeddings directly into LLM at the cost of losing semantic representation. To bridge this gap, we introduce an innovative, end-to-end modality-aligning framework, equipped with a pretrained Dual-Residual Vector Quantized-Variational AutoEncoder (Dr.E). This framework is specifically designed to facilitate token-level alignment with LLMs, enabling an effective translation of the intrinsic `language' of graphs into comprehensible natural language. Our experimental evaluations on standard GNN node classification tasks demonstrate competitive performance against other state-of-the-art approaches. Additionally, our framework ensures interpretability, efficiency, and robustness, with its effectiveness further validated under both fine-tuning and few-shot settings. This study marks the first successful endeavor to achieve token-level alignment between GNNs and LLMs.
Visualizing Graph Neural Networks with CorGIE: Corresponding a Graph to Its Embedding
Jun 24, 2021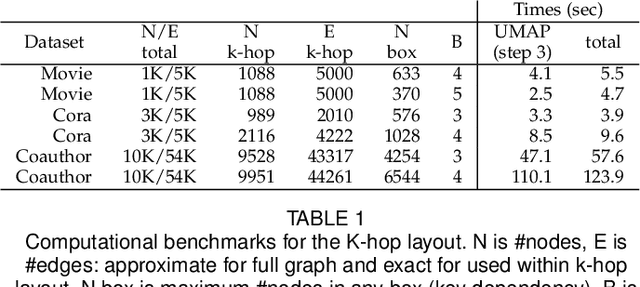

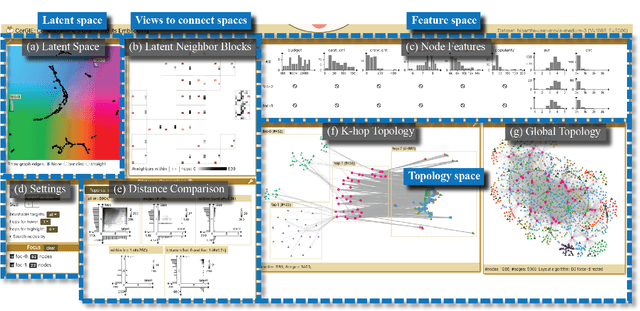

Graph neural networks (GNNs) are a class of powerful machine learning tools that model node relations for making predictions of nodes or links. GNN developers rely on quantitative metrics of the predictions to evaluate a GNN, but similar to many other neural networks, it is difficult for them to understand if the GNN truly learns characteristics of a graph as expected. We propose an approach to corresponding an input graph to its node embedding (aka latent space), a common component of GNNs that is later used for prediction. We abstract the data and tasks, and develop an interactive multi-view interface called CorGIE to instantiate the abstraction. As the key function in CorGIE, we propose the K-hop graph layout to show topological neighbors in hops and their clustering structure. To evaluate the functionality and usability of CorGIE, we present how to use CorGIE in two usage scenarios, and conduct a case study with two GNN experts.