 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMissing Old Logits in Asynchronous Agentic RL: Semantic Mismatch and Repair Methods for Off-Policy Correction
May 12, 2026Asynchronous reinforcement learning improves rollout throughput for large language model agents by decoupling sample generation from policy optimization, but it also introduces a critical failure mode for PPO-style off-policy correction. In heterogeneous training systems, the total importance ratio should ideally be decomposed into two semantically distinct factors: a \emph{training--inference discrepancy term} that aligns inference-side and training-side distributions at the same behavior-policy version, and a \emph{policy-staleness term} that constrains the update from the historical policy to the current policy. We show that practical asynchronous pipelines with delayed updates and partial rollouts often lose the required historical training-side logits, or old logits. This missing-old-logit problem entangles discrepancy repair with staleness correction, breaks the intended semantics of decoupled correction, and makes clipping and masking thresholds interact undesirably. To address this issue, we study both exact and approximate correction routes. We propose three exact old-logit acquisition strategies: snapshot-based version tracking, a dedicated old-logit model, and synchronization via partial rollout interruption, and compare their system trade-offs. From the perspective of approximate correction, we focus on preserving the benefits of decoupled correction through a more appropriate approximate policy when exact old logits cannot be recovered at low cost, without incurring extra system overhead. Following this analysis, we adopt a revised PPO-EWMA method, which achieves significant gains in both training speed and optimization performance. Code at https://github.com/millioniron/ROLL.
From Exposure to Internalization: Dual-Stream Calibration for In-context Clinical Reasoning
Apr 07, 2026Contextual clinical reasoning demands robust inference grounded in complex, heterogeneous clinical records. While state-of-the-art fine-tuning, in-context learning (ICL), and retrieval-augmented generation (RAG) enable knowledge exposure, they often fall short of genuine contextual internalization: dynamically adjusting a model's internal representations to the subtle nuances of individual cases at inference time. To address this, we propose Dual-Stream Calibration (DSC), a test-time training framework that transcends superficial knowledge exposure to achieve deep internalization during inference. DSC facilitates input internalization by synergistically aligning two calibration streams. Unlike passive context exposure, the Semantic Calibration Stream enforces a deliberative reflection on core evidence, internalizing semantic anchors by minimizing entropy to stabilize generative trajectories. Simultaneously, the Structural Calibration Stream assimilates latent inferential dependencies through an iterative meta-learning objective. By training on specialized support sets at test-time, this stream enables the model to bridge the gap between external evidence and internal logic, synthesizing fragmented data into a coherent response. Our approach shifts the reasoning paradigm from passive attention-based matching to an active refinement of the latent inferential space. Validated against thirteen clinical datasets, DSC demonstrates superiority across three distinct task paradigms, consistently outstripping state-of-the-art baselines ranging from training-dependent models to test-time learning frameworks.
RL-VLA$^3$: Reinforcement Learning VLA Accelerating via Full Asynchronism
Feb 05, 2026In recent years, Vision-Language-Action (VLA) models have emerged as a crucial pathway towards general embodied intelligence, yet their training efficiency has become a key bottleneck. Although existing reinforcement learning (RL)-based training frameworks like RLinf can enhance model generalization, they still rely on synchronous execution, leading to severe resource underutilization and throughput limitations during environment interaction, policy generation (rollout), and model update phases (actor). To overcome this challenge, this paper, for the first time, proposes and implements a fully-asynchronous policy training framework encompassing the entire pipeline from environment interaction, rollout generation, to actor policy updates. Systematically drawing inspiration from asynchronous optimization ideas in large model RL, our framework designs a multi-level decoupled architecture. This includes asynchronous parallelization of environment interaction and trajectory collection, streaming execution for policy generation, and decoupled scheduling for training updates. We validated the effectiveness of our method across diverse VLA models and environments. On the LIBERO benchmark, the framework achieves throughput improvements of up to 59.25\% compared to existing synchronous strategies. When deeply optimizing separation strategies, throughput can be increased by as much as 126.67\%. We verified the effectiveness of each asynchronous component via ablation studies. Scaling law validation across 8 to 256 GPUs demonstrates our method's excellent scalability under most conditions.
Grounded by Experience: Generative Healthcare Prediction Augmented with Hierarchical Agentic Retrieval
Nov 17, 2025Accurate healthcare prediction is critical for improving patient outcomes and reducing operational costs. Bolstered by growing reasoning capabilities, large language models (LLMs) offer a promising path to enhance healthcare predictions by drawing on their rich parametric knowledge. However, LLMs are prone to factual inaccuracies due to limitations in the reliability and coverage of their embedded knowledge. While retrieval-augmented generation (RAG) frameworks, such as GraphRAG and its variants, have been proposed to mitigate these issues by incorporating external knowledge, they face two key challenges in the healthcare scenario: (1) identifying the clinical necessity to activate the retrieval mechanism, and (2) achieving synergy between the retriever and the generator to craft contextually appropriate retrievals. To address these challenges, we propose GHAR, a \underline{g}enerative \underline{h}ierarchical \underline{a}gentic \underline{R}AG framework that simultaneously resolves when to retrieve and how to optimize the collaboration between submodules in healthcare. Specifically, for the first challenge, we design a dual-agent architecture comprising Agent-Top and Agent-Low. Agent-Top acts as the primary physician, iteratively deciding whether to rely on parametric knowledge or to initiate retrieval, while Agent-Low acts as the consulting service, summarising all task-relevant knowledge once retrieval was triggered. To tackle the second challenge, we innovatively unify the optimization of both agents within a formal Markov Decision Process, designing diverse rewards to align their shared goal of accurate prediction while preserving their distinct roles. Extensive experiments on three benchmark datasets across three popular tasks demonstrate our superiority over state-of-the-art baselines, highlighting the potential of hierarchical agentic RAG in advancing healthcare systems.
Diffmv: A Unified Diffusion Framework for Healthcare Predictions with Random Missing Views and View Laziness
May 17, 2025Advanced healthcare predictions offer significant improvements in patient outcomes by leveraging predictive analytics. Existing works primarily utilize various views of Electronic Health Record (EHR) data, such as diagnoses, lab tests, or clinical notes, for model training. These methods typically assume the availability of complete EHR views and that the designed model could fully leverage the potential of each view. However, in practice, random missing views and view laziness present two significant challenges that hinder further improvements in multi-view utilization. To address these challenges, we introduce Diffmv, an innovative diffusion-based generative framework designed to advance the exploitation of multiple views of EHR data. Specifically, to address random missing views, we integrate various views of EHR data into a unified diffusion-denoising framework, enriched with diverse contextual conditions to facilitate progressive alignment and view transformation. To mitigate view laziness, we propose a novel reweighting strategy that assesses the relative advantages of each view, promoting a balanced utilization of various data views within the model. Our proposed strategy achieves superior performance across multiple health prediction tasks derived from three popular datasets, including multi-view and multi-modality scenarios.
Attention Mechanisms Perspective: Exploring LLM Processing of Graph-Structured Data
May 04, 2025Attention mechanisms are critical to the success of large language models (LLMs), driving significant advancements in multiple fields. However, for graph-structured data, which requires emphasis on topological connections, they fall short compared to message-passing mechanisms on fixed links, such as those employed by Graph Neural Networks (GNNs). This raises a question: ``Does attention fail for graphs in natural language settings?'' Motivated by these observations, we embarked on an empirical study from the perspective of attention mechanisms to explore how LLMs process graph-structured data. The goal is to gain deeper insights into the attention behavior of LLMs over graph structures. We uncovered unique phenomena regarding how LLMs apply attention to graph-structured data and analyzed these findings to improve the modeling of such data by LLMs. The primary findings of our research are: 1) While LLMs can recognize graph data and capture text-node interactions, they struggle to model inter-node relationships within graph structures due to inherent architectural constraints. 2) The attention distribution of LLMs across graph nodes does not align with ideal structural patterns, indicating a failure to adapt to graph topology nuances. 3) Neither fully connected attention nor fixed connectivity is optimal; each has specific limitations in its application scenarios. Instead, intermediate-state attention windows improve LLM training performance and seamlessly transition to fully connected windows during inference. Source code: \href{https://github.com/millioniron/LLM_exploration}{LLM4Exploration}
Collaborative Knowledge Fusion: A Novel Approach for Multi-task Recommender Systems via LLMs
Oct 28, 2024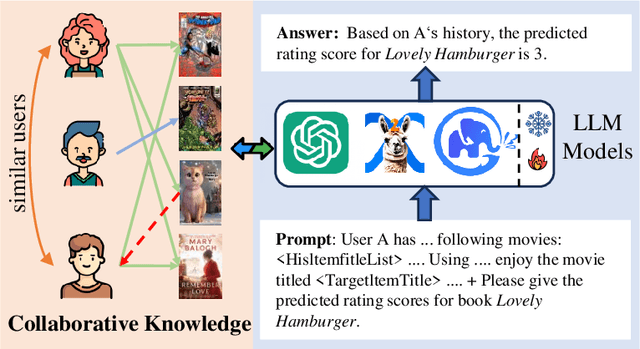
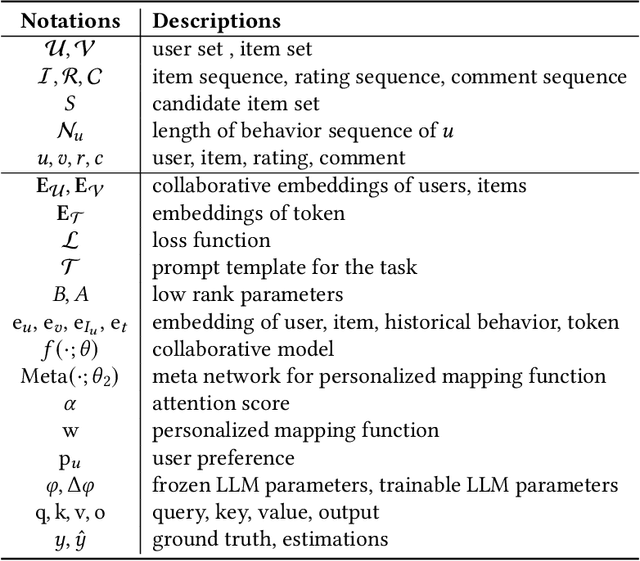
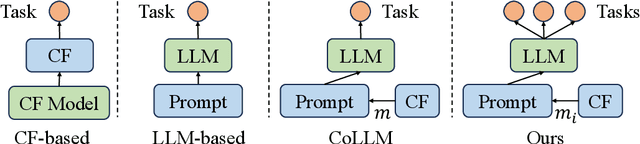

Owing to the impressive general intelligence of large language models (LLMs), there has been a growing trend to integrate them into recommender systems to gain a more profound insight into human interests and intentions. Existing LLMs-based recommender systems primarily leverage item attributes and user interaction histories in textual format, improving the single task like rating prediction or explainable recommendation. Nevertheless, these approaches overlook the crucial contribution of traditional collaborative signals in discerning users' profound intentions and disregard the interrelatedness among tasks. To address these limitations, we introduce a novel framework known as CKF, specifically developed to boost multi-task recommendations via personalized collaborative knowledge fusion into LLMs. Specifically, our method synergizes traditional collaborative filtering models to produce collaborative embeddings, subsequently employing the meta-network to construct personalized mapping bridges tailored for each user. Upon mapped, the embeddings are incorporated into meticulously designed prompt templates and then fed into an advanced LLM to represent user interests. To investigate the intrinsic relationship among diverse recommendation tasks, we develop Multi-Lora, a new parameter-efficient approach for multi-task optimization, adept at distinctly segregating task-shared and task-specific information. This method forges a connection between LLMs and recommendation scenarios, while simultaneously enriching the supervisory signal through mutual knowledge transfer among various tasks. Extensive experiments and in-depth robustness analyses across four common recommendation tasks on four large public data sets substantiate the effectiveness and superiority of our framework.
GANPrompt: Enhancing Robustness in LLM-Based Recommendations with GAN-Enhanced Diversity Prompts
Aug 19, 2024


In recent years, LLM has demonstrated remarkable proficiency in comprehending and generating natural language, with a growing prevalence in the domain of recommender systems. However, LLM continues to face a significant challenge in that it is highly susceptible to the influence of prompt words. This inconsistency in response to minor alterations in prompt input may compromise the accuracy and resilience of recommendation models. To address this issue, this paper proposes GANPrompt, a multi-dimensional large language model prompt diversity framework based on Generative Adversarial Networks (GANs). The framework enhances the model's adaptability and stability to diverse prompts by integrating GAN generation techniques with the deep semantic understanding capabilities of LLMs. GANPrompt first trains a generator capable of producing diverse prompts by analysing multidimensional user behavioural data. These diverse prompts are then used to train the LLM to improve its performance in the face of unseen prompts. Furthermore, to ensure a high degree of diversity and relevance of the prompts, this study introduces a mathematical theory-based diversity constraint mechanism that optimises the generated prompts to ensure that they are not only superficially distinct, but also semantically cover a wide range of user intentions. Through extensive experiments on multiple datasets, we demonstrate the effectiveness of the proposed framework, especially in improving the adaptability and robustness of recommender systems in complex and dynamic environments. The experimental results demonstrate that GANPrompt yields substantial enhancements in accuracy and robustness relative to existing state-of-the-art methodologies.
LANE: Logic Alignment of Non-tuning Large Language Models and Online Recommendation Systems for Explainable Reason Generation
Jul 03, 2024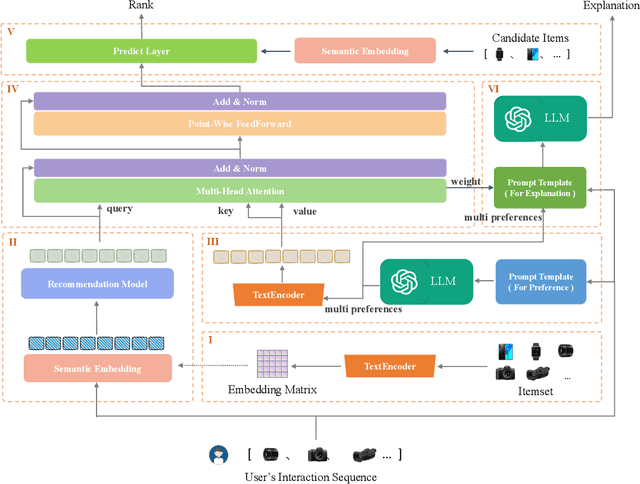
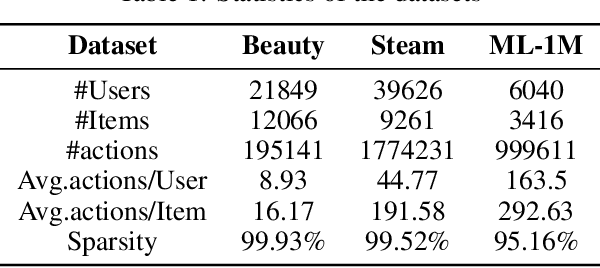

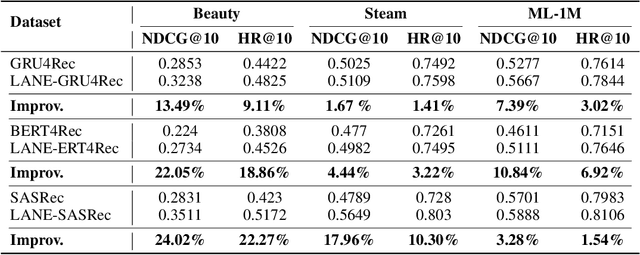
The explainability of recommendation systems is crucial for enhancing user trust and satisfaction. Leveraging large language models (LLMs) offers new opportunities for comprehensive recommendation logic generation. However, in existing related studies, fine-tuning LLM models for recommendation tasks incurs high computational costs and alignment issues with existing systems, limiting the application potential of proven proprietary/closed-source LLM models, such as GPT-4. In this work, our proposed effective strategy LANE aligns LLMs with online recommendation systems without additional LLMs tuning, reducing costs and improving explainability. This innovative approach addresses key challenges in integrating language models with recommendation systems while fully utilizing the capabilities of powerful proprietary models. Specifically, our strategy operates through several key components: semantic embedding, user multi-preference extraction using zero-shot prompting, semantic alignment, and explainable recommendation generation using Chain of Thought (CoT) prompting. By embedding item titles instead of IDs and utilizing multi-head attention mechanisms, our approach aligns the semantic features of user preferences with those of candidate items, ensuring coherent and user-aligned recommendations. Sufficient experimental results including performance comparison, questionnaire voting, and visualization cases prove that our method can not only ensure recommendation performance, but also provide easy-to-understand and reasonable recommendation logic.
Performative Debias with Fair-exposure Optimization Driven by Strategic Agents in Recommender Systems
Jun 25, 2024Data bias, e.g., popularity impairs the dynamics of two-sided markets within recommender systems. This overshadows the less visible but potentially intriguing long-tail items that could capture user interest. Despite the abundance of research surrounding this issue, it still poses challenges and remains a hot topic in academic circles. Along this line, in this paper, we developed a re-ranking approach in dynamic settings with fair-exposure optimization driven by strategic agents. Designed for the producer side, the execution of agents assumes content creators can modify item features based on strategic incentives to maximize their exposure. This iterative process entails an end-to-end optimization, employing differentiable ranking operators that simultaneously target accuracy and fairness. Joint objectives ensure the performance of recommendations while enhancing the visibility of tail items. We also leveraged the performativity nature of predictions to illustrate how strategic learning influences content creators to shift towards fairness efficiently, thereby incentivizing features of tail items. Through comprehensive experiments on both public and industrial datasets, we have substantiated the effectiveness and dominance of the proposed method especially on unveiling the potential of tail items.