 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom a Social Cognitive Perspective: Context-aware Visual Social Relationship Recognition
Paper and Code
Jun 12, 2024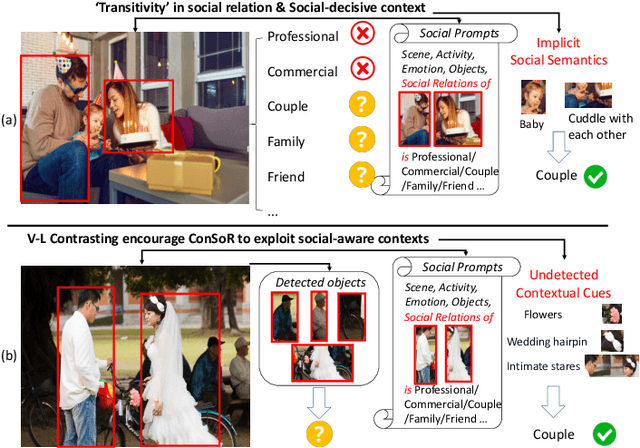



People's social relationships are often manifested through their surroundings, with certain objects or interactions acting as symbols for specific relationships, e.g., wedding rings, roses, hugs, or holding hands. This brings unique challenges to recognizing social relationships, requiring understanding and capturing the essence of these contexts from visual appearances. However, current methods of social relationship understanding rely on the basic classification paradigm of detected persons and objects, which fails to understand the comprehensive context and often overlooks decisive social factors, especially subtle visual cues. To highlight the social-aware context and intricate details, we propose a novel approach that recognizes \textbf{Con}textual \textbf{So}cial \textbf{R}elationships (\textbf{ConSoR}) from a social cognitive perspective. Specifically, to incorporate social-aware semantics, we build a lightweight adapter upon the frozen CLIP to learn social concepts via our novel multi-modal side adapter tuning mechanism. Further, we construct social-aware descriptive language prompts (e.g., scene, activity, objects, emotions) with social relationships for each image, and then compel ConSoR to concentrate more intensively on the decisive visual social factors via visual-linguistic contrasting. Impressively, ConSoR outperforms previous methods with a 12.2\% gain on the People-in-Social-Context (PISC) dataset and a 9.8\% increase on the People-in-Photo-Album (PIPA) benchmark. Furthermore, we observe that ConSoR excels at finding critical visual evidence to reveal social relationships.