 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVideoSAM: Open-World Video Segmentation
Oct 11, 2024



Video segmentation is essential for advancing robotics and autonomous driving, particularly in open-world settings where continuous perception and object association across video frames are critical. While the Segment Anything Model (SAM) has excelled in static image segmentation, extending its capabilities to video segmentation poses significant challenges. We tackle two major hurdles: a) SAM's embedding limitations in associating objects across frames, and b) granularity inconsistencies in object segmentation. To this end, we introduce VideoSAM, an end-to-end framework designed to address these challenges by improving object tracking and segmentation consistency in dynamic environments. VideoSAM integrates an agglomerated backbone, RADIO, enabling object association through similarity metrics and introduces Cycle-ack-Pairs Propagation with a memory mechanism for stable object tracking. Additionally, we incorporate an autoregressive object-token mechanism within the SAM decoder to maintain consistent granularity across frames. Our method is extensively evaluated on the UVO and BURST benchmarks, and robotic videos from RoboTAP, demonstrating its effectiveness and robustness in real-world scenarios. All codes will be available.
Rethinking The Training And Evaluation of Rich-Context Layout-to-Image Generation
Sep 07, 2024Recent advancements in generative models have significantly enhanced their capacity for image generation, enabling a wide range of applications such as image editing, completion and video editing. A specialized area within generative modeling is layout-to-image (L2I) generation, where predefined layouts of objects guide the generative process. In this study, we introduce a novel regional cross-attention module tailored to enrich layout-to-image generation. This module notably improves the representation of layout regions, particularly in scenarios where existing methods struggle with highly complex and detailed textual descriptions. Moreover, while current open-vocabulary L2I methods are trained in an open-set setting, their evaluations often occur in closed-set environments. To bridge this gap, we propose two metrics to assess L2I performance in open-vocabulary scenarios. Additionally, we conduct a comprehensive user study to validate the consistency of these metrics with human preferences.
PeFoMed: Parameter Efficient Fine-tuning on Multimodal Large Language Models for Medical Visual Question Answering
Jan 05, 2024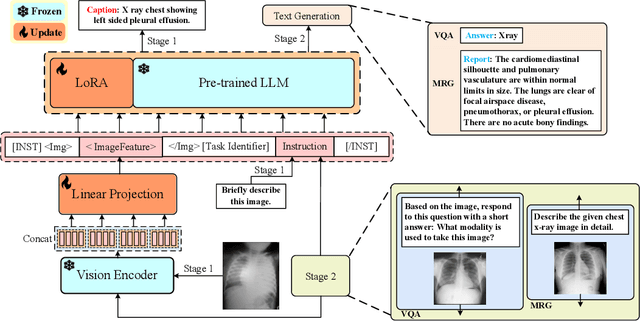
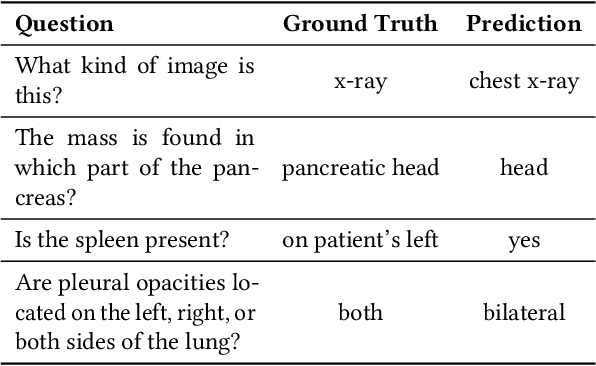

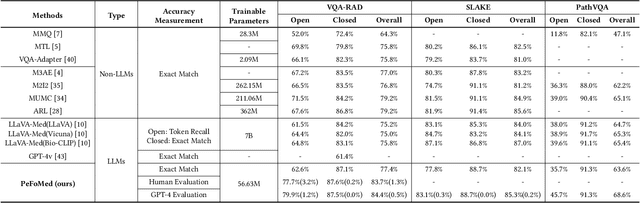
Multimodal large language models (MLLMs) represent an evolutionary expansion in the capabilities of traditional large language models, enabling them to tackle challenges that surpass the scope of purely text-based applications. It leverages the knowledge previously encoded within these language models, thereby enhancing their applicability and functionality in the reign of multimodal contexts. Recent works investigate the adaptation of MLLMs to predict free-form answers as a generative task to solve medical visual question answering (Med-VQA) tasks. In this paper, we propose a parameter efficient framework for fine-tuning MLLM specifically tailored to Med-VQA applications, and empirically validate it on a public benchmark dataset. To accurately measure the performance, we employ human evaluation and the results reveal that our model achieves an overall accuracy of 81.9%, and outperforms the GPT-4v model by a significant margin of 26% absolute accuracy on closed-ended questions. The code will be available here: https://github.com/jinlHe/PeFoMed.
Unsupervised Open-Vocabulary Object Localization in Videos
Sep 18, 2023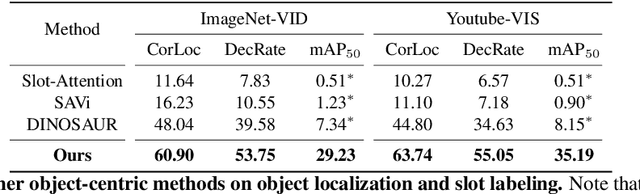
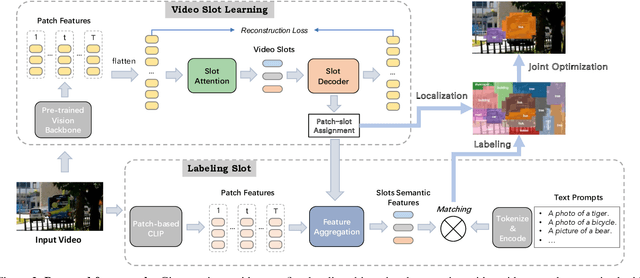
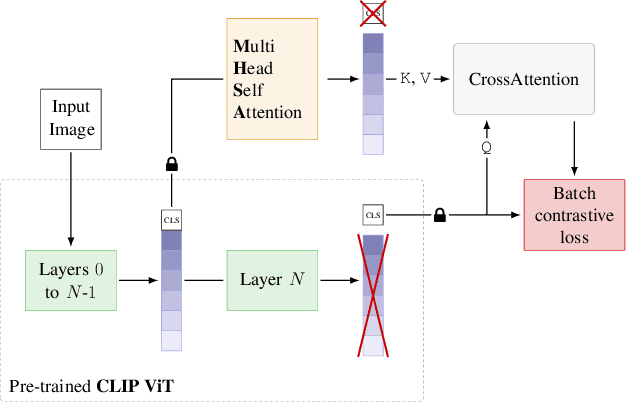
In this paper, we show that recent advances in video representation learning and pre-trained vision-language models allow for substantial improvements in self-supervised video object localization. We propose a method that first localizes objects in videos via a slot attention approach and then assigns text to the obtained slots. The latter is achieved by an unsupervised way to read localized semantic information from the pre-trained CLIP model. The resulting video object localization is entirely unsupervised apart from the implicit annotation contained in CLIP, and it is effectively the first unsupervised approach that yields good results on regular video benchmarks.
Object-Centric Multiple Object Tracking
Sep 05, 2023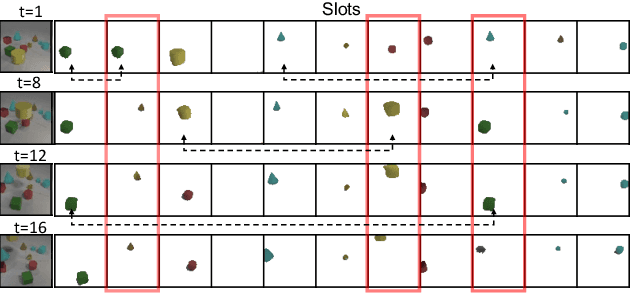
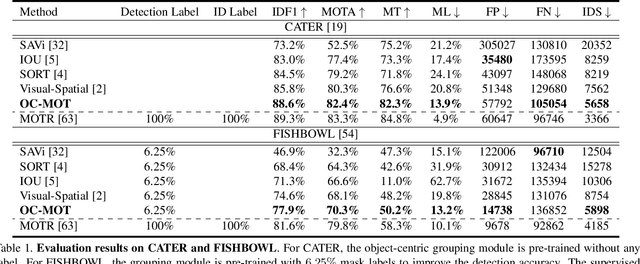
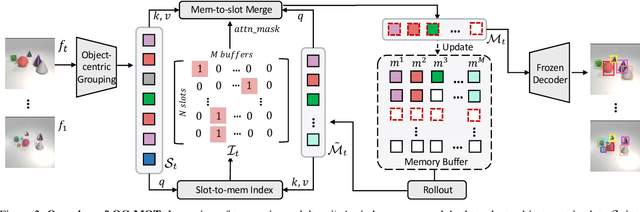
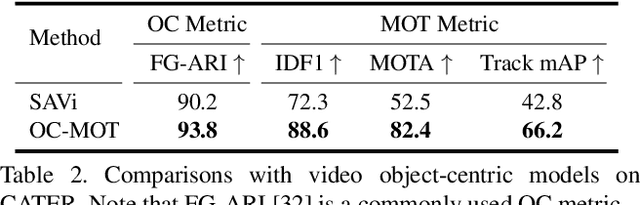
Unsupervised object-centric learning methods allow the partitioning of scenes into entities without additional localization information and are excellent candidates for reducing the annotation burden of multiple-object tracking (MOT) pipelines. Unfortunately, they lack two key properties: objects are often split into parts and are not consistently tracked over time. In fact, state-of-the-art models achieve pixel-level accuracy and temporal consistency by relying on supervised object detection with additional ID labels for the association through time. This paper proposes a video object-centric model for MOT. It consists of an index-merge module that adapts the object-centric slots into detection outputs and an object memory module that builds complete object prototypes to handle occlusions. Benefited from object-centric learning, we only require sparse detection labels (0%-6.25%) for object localization and feature binding. Relying on our self-supervised Expectation-Maximization-inspired loss for object association, our approach requires no ID labels. Our experiments significantly narrow the gap between the existing object-centric model and the fully supervised state-of-the-art and outperform several unsupervised trackers.
Masked Vision and Language Pre-training with Unimodal and Multimodal Contrastive Losses for Medical Visual Question Answering
Jul 11, 2023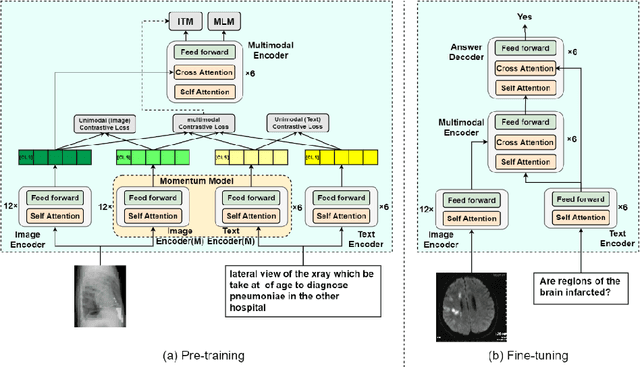
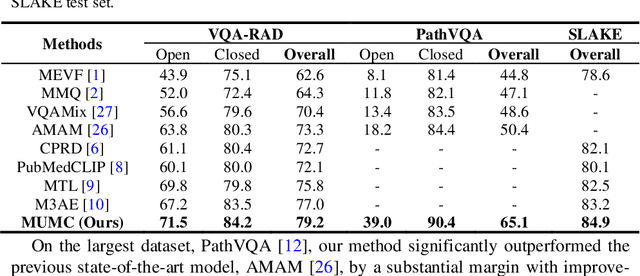
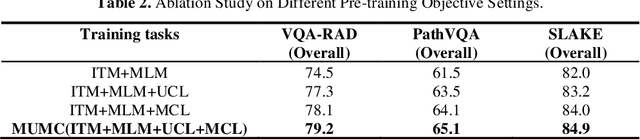
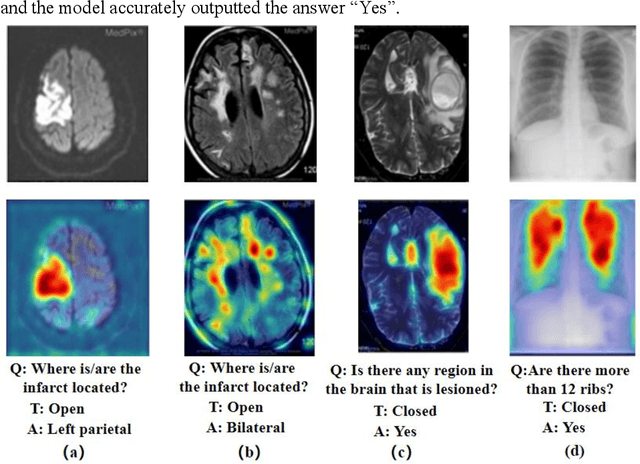
Medical visual question answering (VQA) is a challenging task that requires answering clinical questions of a given medical image, by taking consider of both visual and language information. However, due to the small scale of training data for medical VQA, pre-training fine-tuning paradigms have been a commonly used solution to improve model generalization performance. In this paper, we present a novel self-supervised approach that learns unimodal and multimodal feature representations of input images and text using medical image caption datasets, by leveraging both unimodal and multimodal contrastive losses, along with masked language modeling and image text matching as pretraining objectives. The pre-trained model is then transferred to downstream medical VQA tasks. The proposed approach achieves state-of-the-art (SOTA) performance on three publicly available medical VQA datasets with significant accuracy improvements of 2.2%, 14.7%, and 1.7% respectively. Besides, we conduct a comprehensive analysis to validate the effectiveness of different components of the approach and study different pre-training settings. Our codes and models are available at https://github.com/pengfeiliHEU/MUMC.
PointPatchMix: Point Cloud Mixing with Patch Scoring
Mar 12, 2023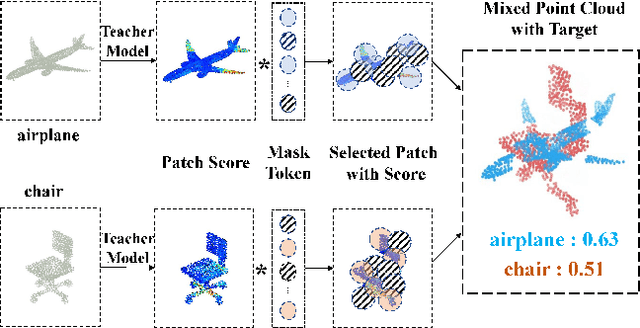



Data augmentation is an effective regularization strategy for mitigating overfitting in deep neural networks, and it plays a crucial role in 3D vision tasks, where the point cloud data is relatively limited. While mixing-based augmentation has shown promise for point clouds, previous methods mix point clouds either on block level or point level, which has constrained their ability to strike a balance between generating diverse training samples and preserving the local characteristics of point clouds. Additionally, the varying importance of each part of the point clouds has not been fully considered, cause not all parts contribute equally to the classification task, and some parts may contain unimportant or redundant information. To overcome these challenges, we propose PointPatchMix, a novel approach that mixes point clouds at the patch level and integrates a patch scoring module to generate content-based targets for mixed point clouds. Our approach preserves local features at the patch level, while the patch scoring module assigns targets based on the content-based significance score from a pre-trained teacher model. We evaluate PointPatchMix on two benchmark datasets, ModelNet40 and ScanObjectNN, and demonstrate significant improvements over various baselines in both synthetic and real-world datasets, as well as few-shot settings. With Point-MAE as our baseline, our model surpasses previous methods by a significant margin, achieving 86.3% accuracy on ScanObjectNN and 94.1% accuracy on ModelNet40. Furthermore, our approach shows strong generalization across multiple architectures and enhances the robustness of the baseline model.
Pseudo-label Guided Cross-video Pixel Contrast for Robotic Surgical Scene Segmentation with Limited Annotations
Jul 20, 2022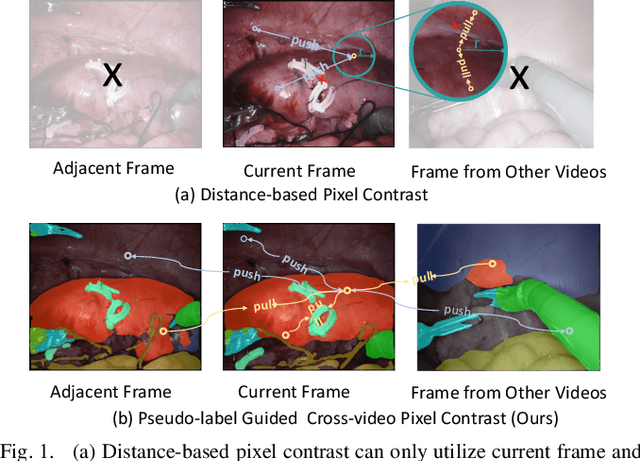
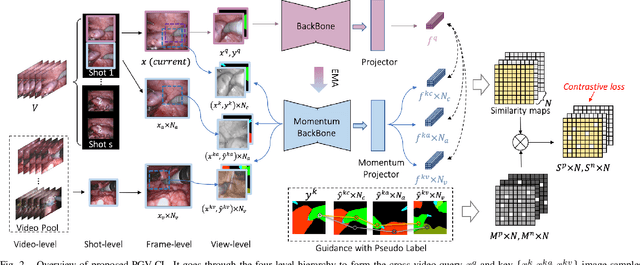
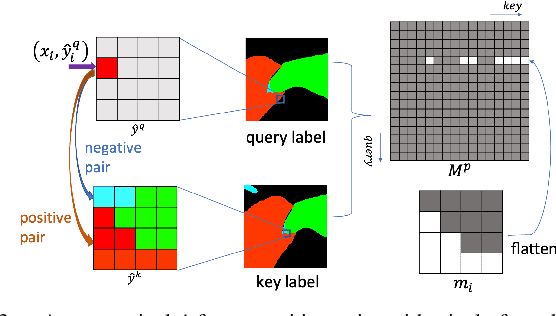
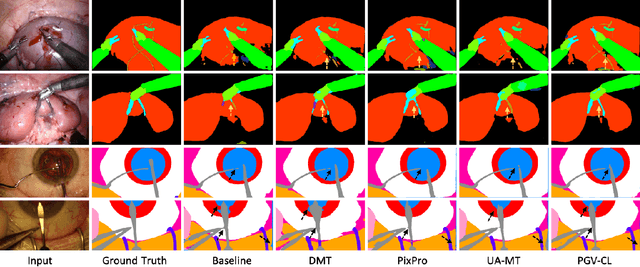
Surgical scene segmentation is fundamentally crucial for prompting cognitive assistance in robotic surgery. However, pixel-wise annotating surgical video in a frame-by-frame manner is expensive and time consuming. To greatly reduce the labeling burden, in this work, we study semi-supervised scene segmentation from robotic surgical video, which is practically essential yet rarely explored before. We consider a clinically suitable annotation situation under the equidistant sampling. We then propose PGV-CL, a novel pseudo-label guided cross-video contrast learning method to boost scene segmentation. It effectively leverages unlabeled data for a trusty and global model regularization that produces more discriminative feature representation. Concretely, for trusty representation learning, we propose to incorporate pseudo labels to instruct the pair selection, obtaining more reliable representation pairs for pixel contrast. Moreover, we expand the representation learning space from previous image-level to cross-video, which can capture the global semantics to benefit the learning process. We extensively evaluate our method on a public robotic surgery dataset EndoVis18 and a public cataract dataset CaDIS. Experimental results demonstrate the effectiveness of our method, consistently outperforming the state-of-the-art semi-supervised methods under different labeling ratios, and even surpassing fully supervised training on EndoVis18 with 10.1% labeling.
Exploring Intra- and Inter-Video Relation for Surgical Semantic Scene Segmentation
Mar 29, 2022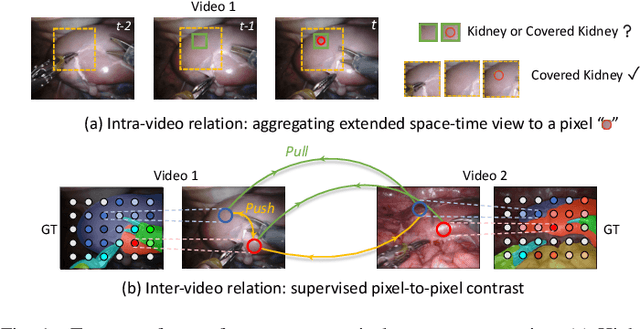
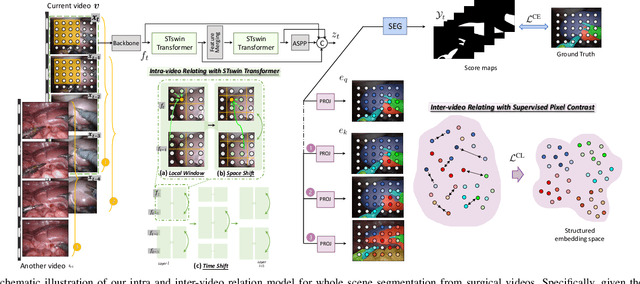
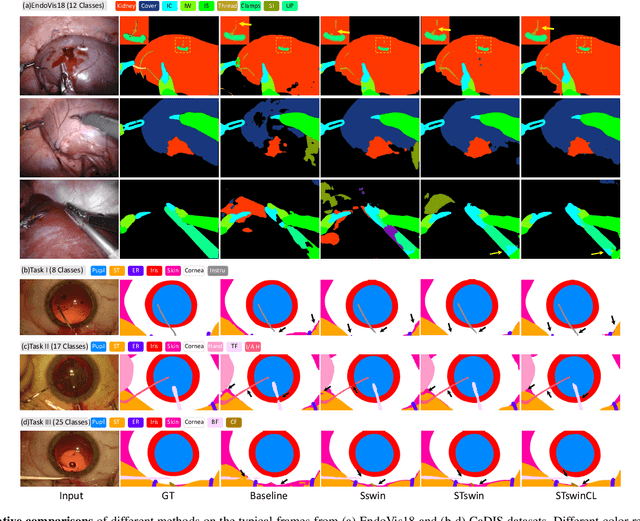

Automatic surgical scene segmentation is fundamental for facilitating cognitive intelligence in the modern operating theatre. Previous works rely on conventional aggregation modules (e.g., dilated convolution, convolutional LSTM), which only make use of the local context. In this paper, we propose a novel framework STswinCL that explores the complementary intra- and inter-video relations to boost segmentation performance, by progressively capturing the global context. We firstly develop a hierarchy Transformer to capture intra-video relation that includes richer spatial and temporal cues from neighbor pixels and previous frames. A joint space-time window shift scheme is proposed to efficiently aggregate these two cues into each pixel embedding. Then, we explore inter-video relation via pixel-to-pixel contrastive learning, which well structures the global embedding space. A multi-source contrast training objective is developed to group the pixel embeddings across videos with the ground-truth guidance, which is crucial for learning the global property of the whole data. We extensively validate our approach on two public surgical video benchmarks, including EndoVis18 Challenge and CaDIS dataset. Experimental results demonstrate the promising performance of our method, which consistently exceeds previous state-of-the-art approaches. Code will be available at https://github.com/YuemingJin/STswinCL.
TraSeTR: Track-to-Segment Transformer with Contrastive Query for Instance-level Instrument Segmentation in Robotic Surgery
Feb 17, 2022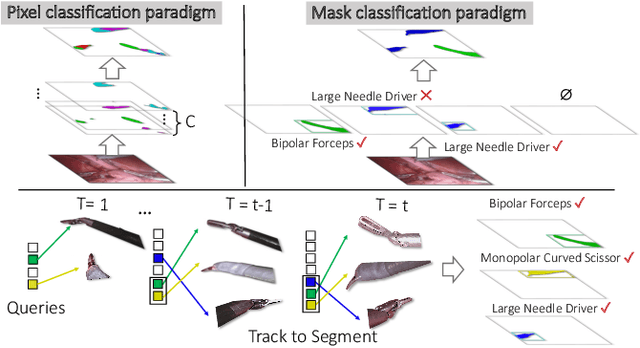
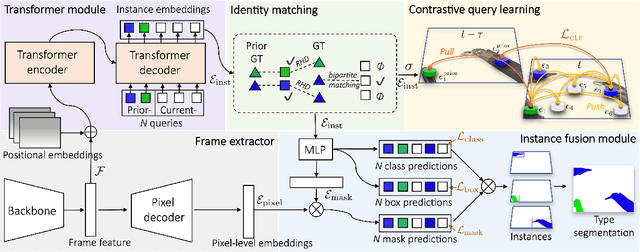
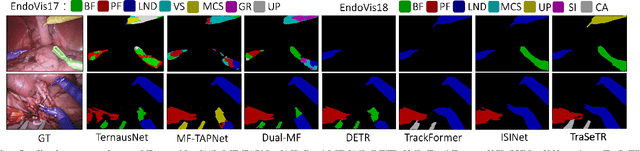
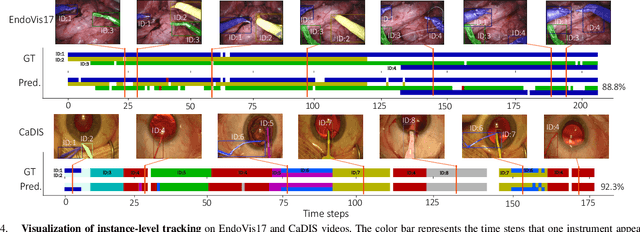
Surgical instrument segmentation -- in general a pixel classification task -- is fundamentally crucial for promoting cognitive intelligence in robot-assisted surgery (RAS). However, previous methods are struggling with discriminating instrument types and instances. To address the above issues, we explore a mask classification paradigm that produces per-segment predictions. We propose TraSeTR, a novel Track-to-Segment Transformer that wisely exploits tracking cues to assist surgical instrument segmentation. TraSeTR jointly reasons about the instrument type, location, and identity with instance-level predictions i.e., a set of class-bbox-mask pairs, by decoding query embeddings. Specifically, we introduce the prior query that encoded with previous temporal knowledge, to transfer tracking signals to current instances via identity matching. A contrastive query learning strategy is further applied to reshape the query feature space, which greatly alleviates the tracking difficulty caused by large temporal variations. The effectiveness of our method is demonstrated with state-of-the-art instrument type segmentation results on three public datasets, including two RAS benchmarks from EndoVis Challenges and one cataract surgery dataset CaDIS.