 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeParameter-Efficient Fine-Tuning Medical Multimodal Large Language Models for Medical Visual Grounding
Oct 31, 2024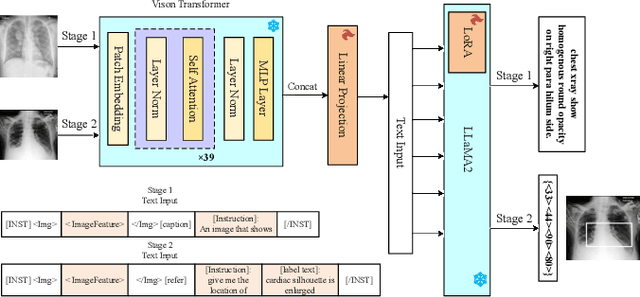


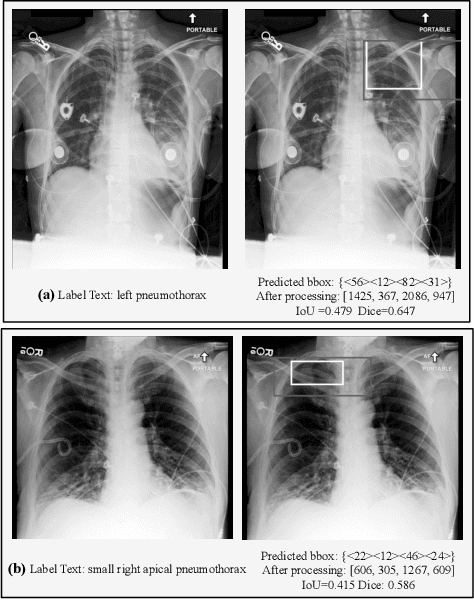
Multimodal Large Language Models (MLLMs) inherit the superior text understanding capabilities of LLMs and extend these capabilities to multimodal scenarios. These models achieve excellent results in the general domain of multimodal tasks. However, in the medical domain, the substantial training costs and the requirement for extensive medical data pose challenges to the development of medical MLLMs. Furthermore, due to the free-text form of answers, tasks such as visual grounding that need to produce output in a prescribed form become difficult for MLLMs. So far, there have been no medical MLLMs works in medical visual grounding area. For the medical vision grounding task, which involves identifying locations in medical images based on short text descriptions, we propose Parameter-efficient Fine-tuning medical multimodal large language models for Medcial Visual Grounding (PFMVG). To validate the performance of the model, we evaluate it on a public benchmark dataset for medical visual grounding, where it achieves competitive results, and significantly outperforming GPT-4v. Our code will be open sourced after peer review.
Enhancing Generalization in Medical Visual Question Answering Tasks via Gradient-Guided Model Perturbation
Mar 05, 2024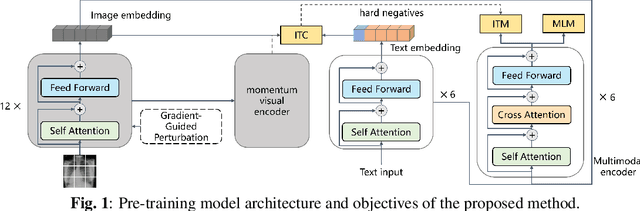


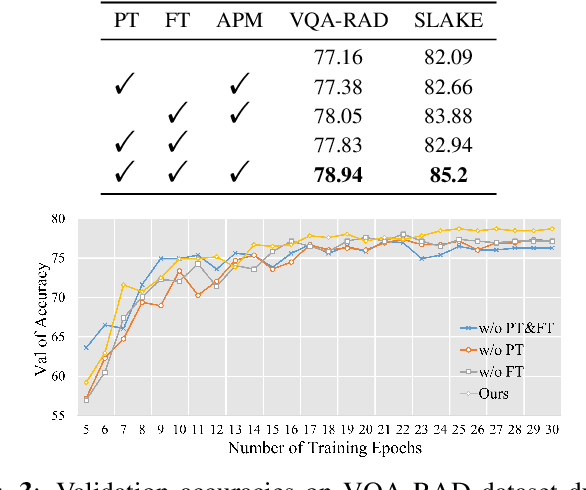
Leveraging pre-trained visual language models has become a widely adopted approach for improving performance in downstream visual question answering (VQA) applications. However, in the specialized field of medical VQA, the scarcity of available data poses a significant barrier to achieving reliable model generalization. Numerous methods have been proposed to enhance model generalization, addressing the issue from data-centric and model-centric perspectives. Data augmentation techniques are commonly employed to enrich the dataset, while various regularization approaches aim to prevent model overfitting, especially when training on limited data samples. In this paper, we introduce a method that incorporates gradient-guided parameter perturbations to the visual encoder of the multimodality model during both pre-training and fine-tuning phases, to improve model generalization for downstream medical VQA tasks. The small perturbation is adaptively generated by aligning with the direction of the moving average gradient in the optimization landscape, which is opposite to the directions of the optimizer's historical updates. It is subsequently injected into the model's visual encoder. The results show that, even with a significantly smaller pre-training image caption dataset, our approach achieves competitive outcomes on both VQA-RAD and SLAKE datasets.
PeFoMed: Parameter Efficient Fine-tuning on Multimodal Large Language Models for Medical Visual Question Answering
Jan 05, 2024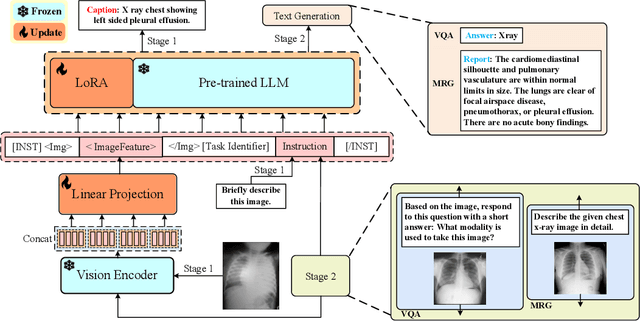
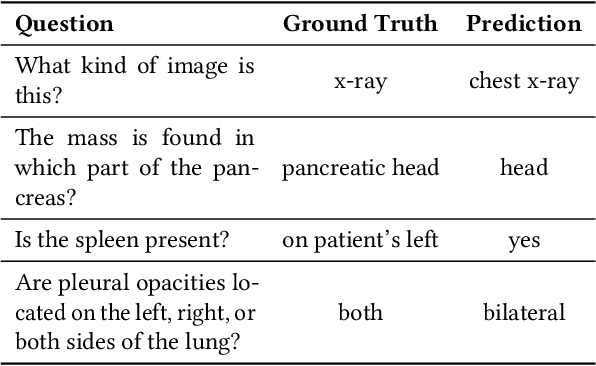

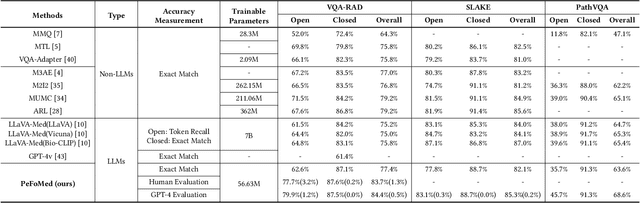
Multimodal large language models (MLLMs) represent an evolutionary expansion in the capabilities of traditional large language models, enabling them to tackle challenges that surpass the scope of purely text-based applications. It leverages the knowledge previously encoded within these language models, thereby enhancing their applicability and functionality in the reign of multimodal contexts. Recent works investigate the adaptation of MLLMs to predict free-form answers as a generative task to solve medical visual question answering (Med-VQA) tasks. In this paper, we propose a parameter efficient framework for fine-tuning MLLM specifically tailored to Med-VQA applications, and empirically validate it on a public benchmark dataset. To accurately measure the performance, we employ human evaluation and the results reveal that our model achieves an overall accuracy of 81.9%, and outperforms the GPT-4v model by a significant margin of 26% absolute accuracy on closed-ended questions. The code will be available here: https://github.com/jinlHe/PeFoMed.
Masked Vision and Language Pre-training with Unimodal and Multimodal Contrastive Losses for Medical Visual Question Answering
Jul 11, 2023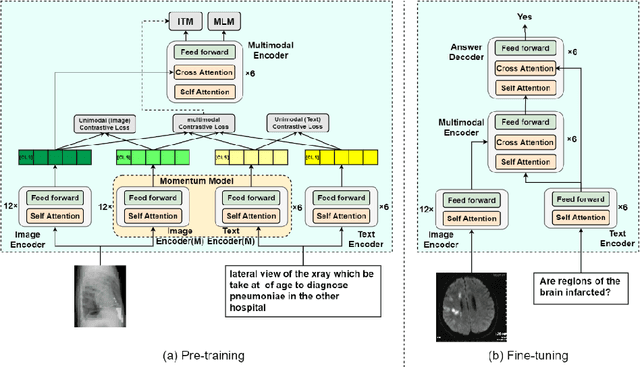
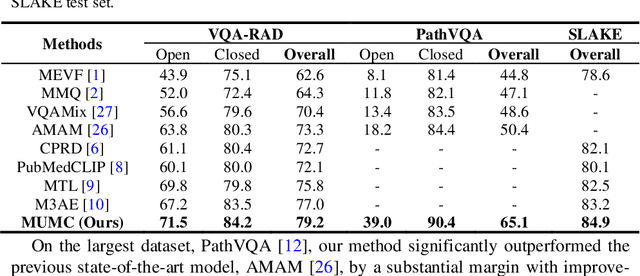
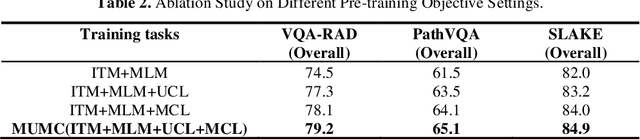
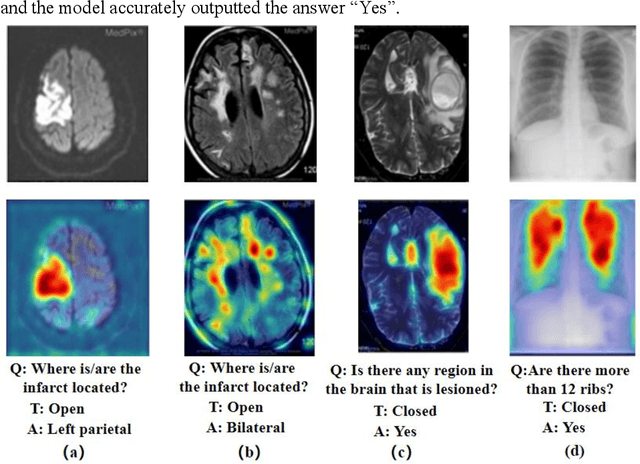
Medical visual question answering (VQA) is a challenging task that requires answering clinical questions of a given medical image, by taking consider of both visual and language information. However, due to the small scale of training data for medical VQA, pre-training fine-tuning paradigms have been a commonly used solution to improve model generalization performance. In this paper, we present a novel self-supervised approach that learns unimodal and multimodal feature representations of input images and text using medical image caption datasets, by leveraging both unimodal and multimodal contrastive losses, along with masked language modeling and image text matching as pretraining objectives. The pre-trained model is then transferred to downstream medical VQA tasks. The proposed approach achieves state-of-the-art (SOTA) performance on three publicly available medical VQA datasets with significant accuracy improvements of 2.2%, 14.7%, and 1.7% respectively. Besides, we conduct a comprehensive analysis to validate the effectiveness of different components of the approach and study different pre-training settings. Our codes and models are available at https://github.com/pengfeiliHEU/MUMC.
Self-supervised vision-language pretraining for Medical visual question answering
Nov 24, 2022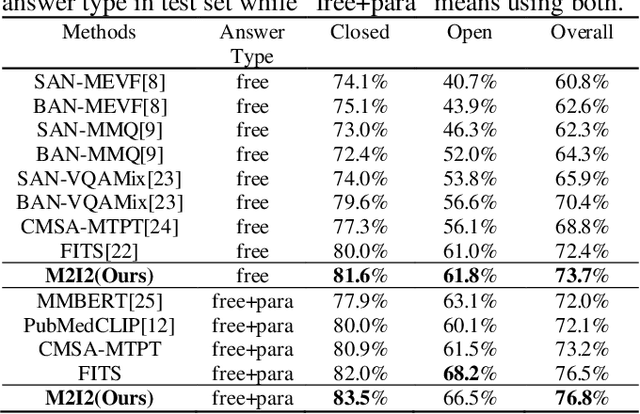


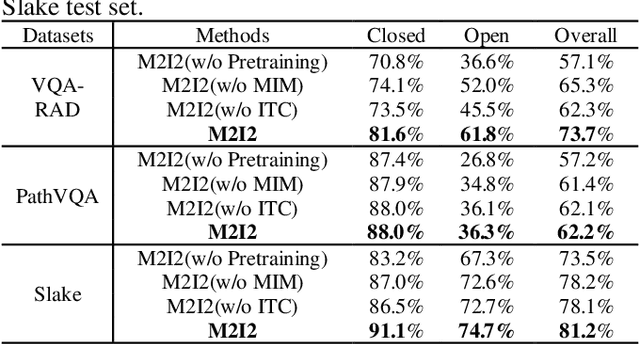
Medical image visual question answering (VQA) is a task to answer clinical questions, given a radiographic image, which is a challenging problem that requires a model to integrate both vision and language information. To solve medical VQA problems with a limited number of training data, pretrain-finetune paradigm is widely used to improve the model generalization. In this paper, we propose a self-supervised method that applies Masked image modeling, Masked language modeling, Image text matching and Image text alignment via contrastive learning (M2I2) for pretraining on medical image caption dataset, and finetunes to downstream medical VQA tasks. The proposed method achieves state-of-the-art performance on all the three public medical VQA datasets. Our codes and models are available at https://github.com/pengfeiliHEU/M2I2.
A comprehensive solution to retrieval-based chatbot construction
Jun 11, 2021
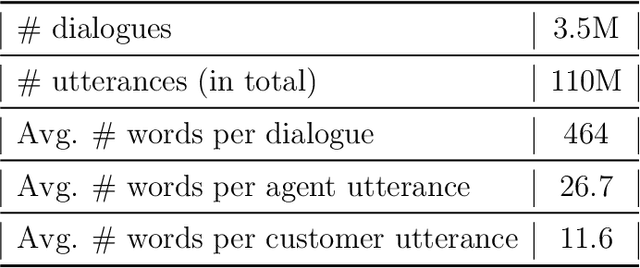
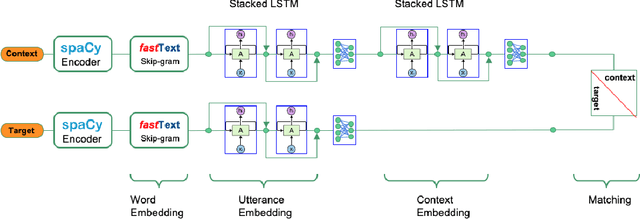
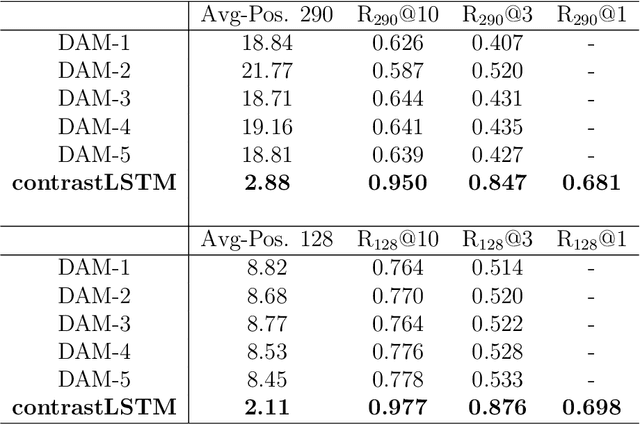
In this paper we present the results of our experiments in training and deploying a self-supervised retrieval-based chatbot trained with contrastive learning for assisting customer support agents. In contrast to most existing research papers in this area where the focus is on solving just one component of a deployable chatbot, we present an end-to-end set of solutions to take the reader from an unlabelled chatlogs to a deployed chatbot. This set of solutions includes creating a self-supervised dataset and a weakly labelled dataset from chatlogs, as well as a systematic approach to selecting a fixed list of canned responses. We present a hierarchical-based RNN architecture for the response selection model, chosen for its ability to cache intermediate utterance embeddings, which helped to meet deployment inference speed requirements. We compare the performance of this architecture across 3 different learning objectives: self-supervised contrastive learning, binary classification, and multi-class classification. We find that using a self-supervised contrastive learning model outperforms training the binary and multi-class classification models on a weakly labelled dataset. Our results validate that the self-supervised contrastive learning approach can be effectively used for a real-world chatbot scenario.