 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDINOv3-Guided Cross Fusion Framework for Semantic-aware CT generation from MRI and CBCT
Nov 15, 2025



Generating synthetic CT images from CBCT or MRI has a potential for efficient radiation dose planning and adaptive radiotherapy. However, existing CNN-based models lack global semantic understanding, while Transformers often overfit small medical datasets due to high model capacity and weak inductive bias. To address these limitations, we propose a DINOv3-Guided Cross Fusion (DGCF) framework that integrates a frozen self-supervised DINOv3 Transformer with a trainable CNN encoder-decoder. It hierarchically fuses global representation of Transformer and local features of CNN via a learnable cross fusion module, achieving balanced local appearance and contextual representation. Furthermore, we introduce a Multi-Level DINOv3 Perceptual (MLDP) loss that encourages semantic similarity between synthetic CT and the ground truth in DINOv3's feature space. Experiments on the SynthRAD2023 pelvic dataset demonstrate that DGCF achieved state-of-the-art performance in terms of MS-SSIM, PSNR and segmentation-based metrics on both MRI$\rightarrow$CT and CBCT$\rightarrow$CT translation tasks. To the best of our knowledge, this is the first work to employ DINOv3 representations for medical image translation, highlighting the potential of self-supervised Transformer guidance for semantic-aware CT synthesis. The code is available at https://github.com/HiLab-git/DGCF.
Parameter-Efficient Fine-Tuning Medical Multimodal Large Language Models for Medical Visual Grounding
Oct 31, 2024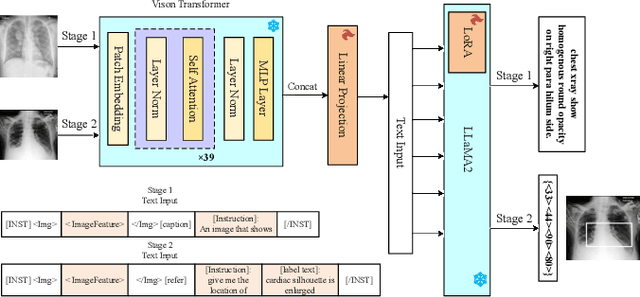


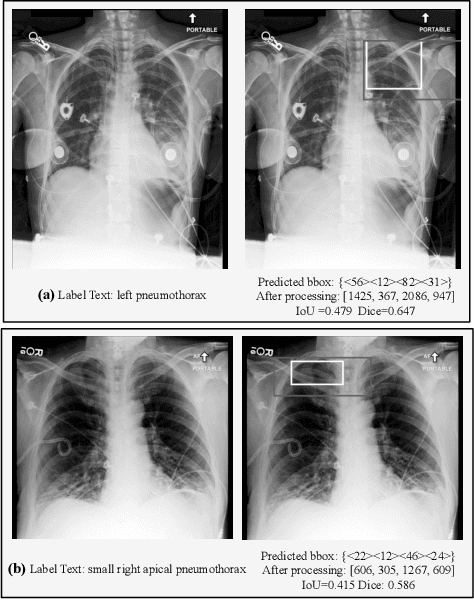
Multimodal Large Language Models (MLLMs) inherit the superior text understanding capabilities of LLMs and extend these capabilities to multimodal scenarios. These models achieve excellent results in the general domain of multimodal tasks. However, in the medical domain, the substantial training costs and the requirement for extensive medical data pose challenges to the development of medical MLLMs. Furthermore, due to the free-text form of answers, tasks such as visual grounding that need to produce output in a prescribed form become difficult for MLLMs. So far, there have been no medical MLLMs works in medical visual grounding area. For the medical vision grounding task, which involves identifying locations in medical images based on short text descriptions, we propose Parameter-efficient Fine-tuning medical multimodal large language models for Medcial Visual Grounding (PFMVG). To validate the performance of the model, we evaluate it on a public benchmark dataset for medical visual grounding, where it achieves competitive results, and significantly outperforming GPT-4v. Our code will be open sourced after peer review.
PeFoMed: Parameter Efficient Fine-tuning on Multimodal Large Language Models for Medical Visual Question Answering
Jan 05, 2024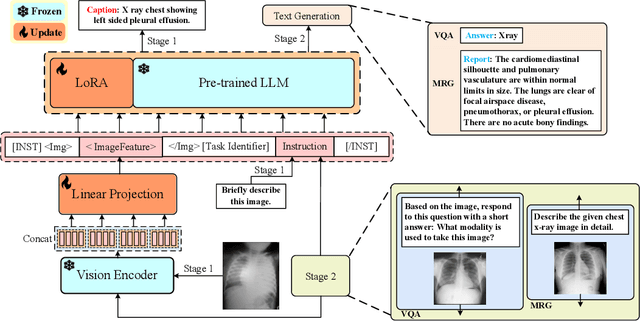
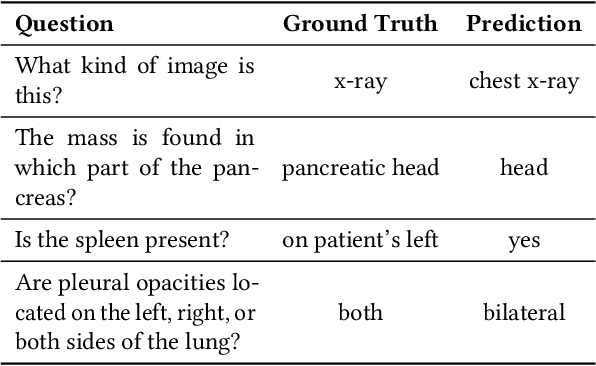

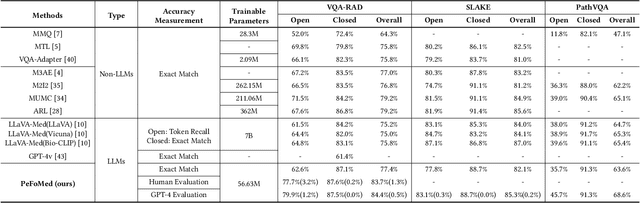
Multimodal large language models (MLLMs) represent an evolutionary expansion in the capabilities of traditional large language models, enabling them to tackle challenges that surpass the scope of purely text-based applications. It leverages the knowledge previously encoded within these language models, thereby enhancing their applicability and functionality in the reign of multimodal contexts. Recent works investigate the adaptation of MLLMs to predict free-form answers as a generative task to solve medical visual question answering (Med-VQA) tasks. In this paper, we propose a parameter efficient framework for fine-tuning MLLM specifically tailored to Med-VQA applications, and empirically validate it on a public benchmark dataset. To accurately measure the performance, we employ human evaluation and the results reveal that our model achieves an overall accuracy of 81.9%, and outperforms the GPT-4v model by a significant margin of 26% absolute accuracy on closed-ended questions. The code will be available here: https://github.com/jinlHe/PeFoMed.
Masked Vision and Language Pre-training with Unimodal and Multimodal Contrastive Losses for Medical Visual Question Answering
Jul 11, 2023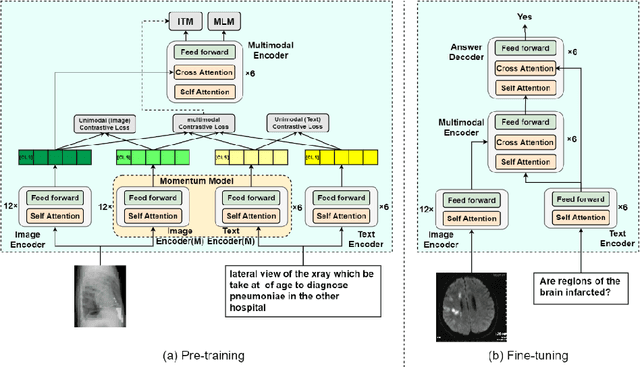
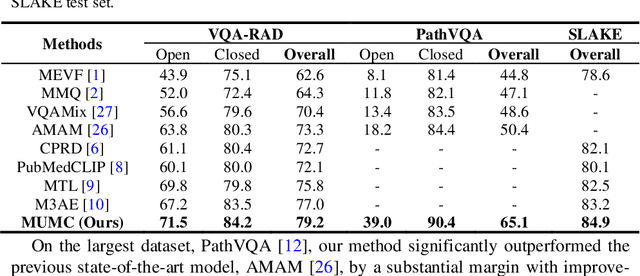
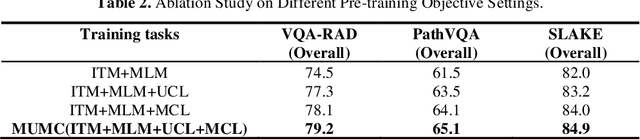
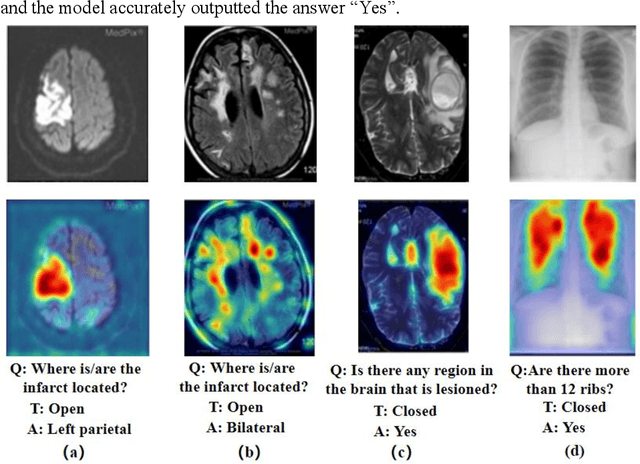
Medical visual question answering (VQA) is a challenging task that requires answering clinical questions of a given medical image, by taking consider of both visual and language information. However, due to the small scale of training data for medical VQA, pre-training fine-tuning paradigms have been a commonly used solution to improve model generalization performance. In this paper, we present a novel self-supervised approach that learns unimodal and multimodal feature representations of input images and text using medical image caption datasets, by leveraging both unimodal and multimodal contrastive losses, along with masked language modeling and image text matching as pretraining objectives. The pre-trained model is then transferred to downstream medical VQA tasks. The proposed approach achieves state-of-the-art (SOTA) performance on three publicly available medical VQA datasets with significant accuracy improvements of 2.2%, 14.7%, and 1.7% respectively. Besides, we conduct a comprehensive analysis to validate the effectiveness of different components of the approach and study different pre-training settings. Our codes and models are available at https://github.com/pengfeiliHEU/MUMC.