 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-supervised vision-language pretraining for Medical visual question answering
Nov 24, 2022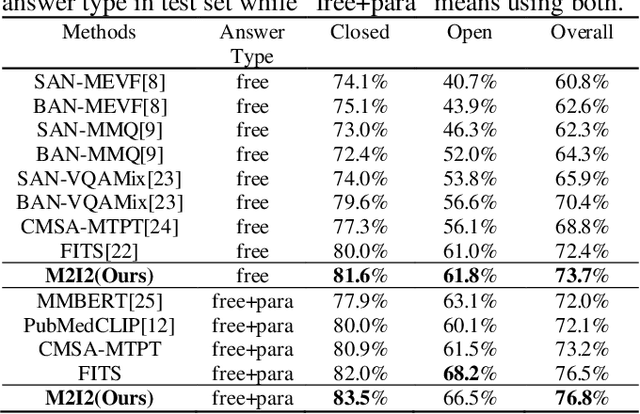


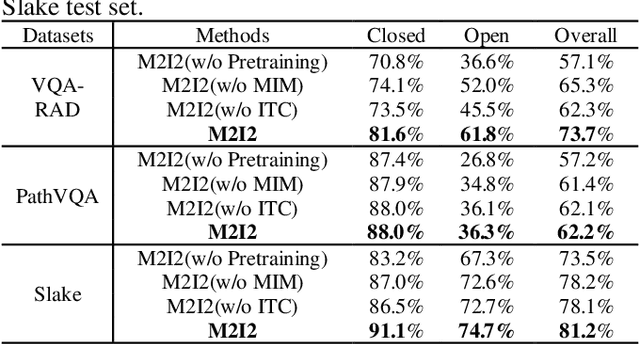
Medical image visual question answering (VQA) is a task to answer clinical questions, given a radiographic image, which is a challenging problem that requires a model to integrate both vision and language information. To solve medical VQA problems with a limited number of training data, pretrain-finetune paradigm is widely used to improve the model generalization. In this paper, we propose a self-supervised method that applies Masked image modeling, Masked language modeling, Image text matching and Image text alignment via contrastive learning (M2I2) for pretraining on medical image caption dataset, and finetunes to downstream medical VQA tasks. The proposed method achieves state-of-the-art performance on all the three public medical VQA datasets. Our codes and models are available at https://github.com/pengfeiliHEU/M2I2.