 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePseudo-label Guided Cross-video Pixel Contrast for Robotic Surgical Scene Segmentation with Limited Annotations
Paper and Code
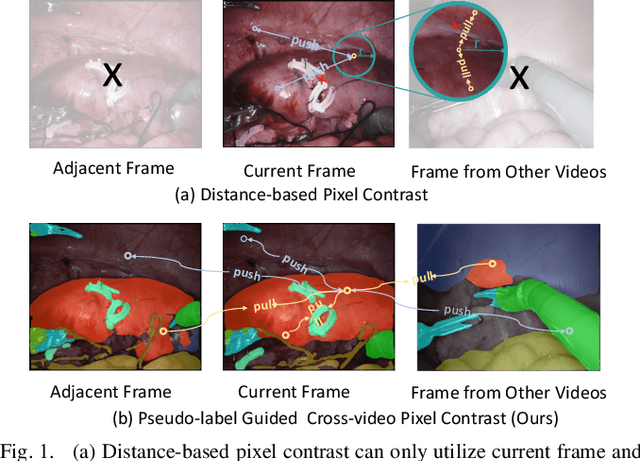
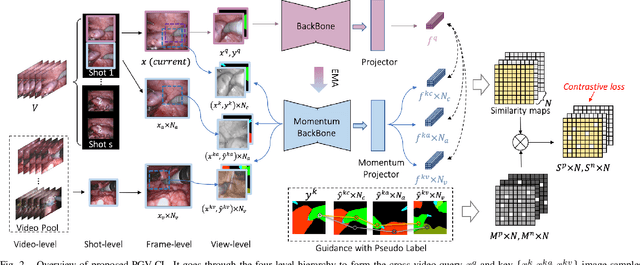
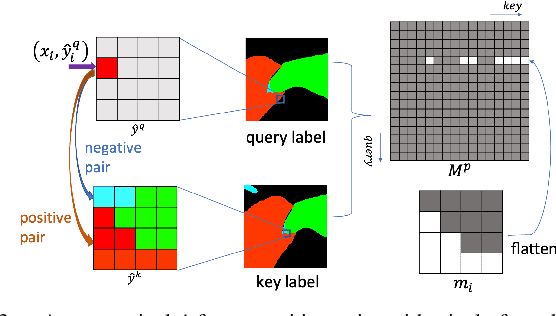
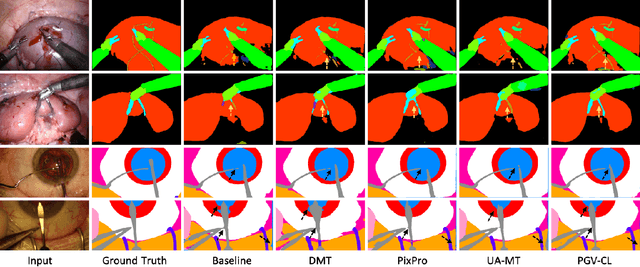
Surgical scene segmentation is fundamentally crucial for prompting cognitive assistance in robotic surgery. However, pixel-wise annotating surgical video in a frame-by-frame manner is expensive and time consuming. To greatly reduce the labeling burden, in this work, we study semi-supervised scene segmentation from robotic surgical video, which is practically essential yet rarely explored before. We consider a clinically suitable annotation situation under the equidistant sampling. We then propose PGV-CL, a novel pseudo-label guided cross-video contrast learning method to boost scene segmentation. It effectively leverages unlabeled data for a trusty and global model regularization that produces more discriminative feature representation. Concretely, for trusty representation learning, we propose to incorporate pseudo labels to instruct the pair selection, obtaining more reliable representation pairs for pixel contrast. Moreover, we expand the representation learning space from previous image-level to cross-video, which can capture the global semantics to benefit the learning process. We extensively evaluate our method on a public robotic surgery dataset EndoVis18 and a public cataract dataset CaDIS. Experimental results demonstrate the effectiveness of our method, consistently outperforming the state-of-the-art semi-supervised methods under different labeling ratios, and even surpassing fully supervised training on EndoVis18 with 10.1% labeling.