 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Scalable and Effective Alternative to Graph Transformers
Jun 17, 2024



Graph Neural Networks (GNNs) have shown impressive performance in graph representation learning, but they face challenges in capturing long-range dependencies due to their limited expressive power. To address this, Graph Transformers (GTs) were introduced, utilizing self-attention mechanism to effectively model pairwise node relationships. Despite their advantages, GTs suffer from quadratic complexity w.r.t. the number of nodes in the graph, hindering their applicability to large graphs. In this work, we present Graph-Enhanced Contextual Operator (GECO), a scalable and effective alternative to GTs that leverages neighborhood propagation and global convolutions to effectively capture local and global dependencies in quasilinear time. Our study on synthetic datasets reveals that GECO reaches 169x speedup on a graph with 2M nodes w.r.t. optimized attention. Further evaluations on diverse range of benchmarks showcase that GECO scales to large graphs where traditional GTs often face memory and time limitations. Notably, GECO consistently achieves comparable or superior quality compared to baselines, improving the SOTA up to 4.5%, and offering a scalable and effective solution for large-scale graph learning.
VCR-Graphormer: A Mini-batch Graph Transformer via Virtual Connections
Mar 24, 2024



Graph transformer has been proven as an effective graph learning method for its adoption of attention mechanism that is capable of capturing expressive representations from complex topological and feature information of graphs. Graph transformer conventionally performs dense attention (or global attention) for every pair of nodes to learn node representation vectors, resulting in quadratic computational costs that are unaffordable for large-scale graph data. Therefore, mini-batch training for graph transformers is a promising direction, but limited samples in each mini-batch can not support effective dense attention to encode informative representations. Facing this bottleneck, (1) we start by assigning each node a token list that is sampled by personalized PageRank (PPR) and then apply standard multi-head self-attention only on this list to compute its node representations. This PPR tokenization method decouples model training from complex graph topological information and makes heavy feature engineering offline and independent, such that mini-batch training of graph transformers is possible by loading each node's token list in batches. We further prove this PPR tokenization is viable as a graph convolution network with a fixed polynomial filter and jumping knowledge. However, only using personalized PageRank may limit information carried by a token list, which could not support different graph inductive biases for model training. To this end, (2) we rewire graphs by introducing multiple types of virtual connections through structure- and content-based super nodes that enable PPR tokenization to encode local and global contexts, long-range interaction, and heterophilous information into each node's token list, and then formalize our Virtual Connection Ranking based Graph Transformer (VCR-Graphormer).
MG-GCN: Scalable Multi-GPU GCN Training Framework
Oct 17, 2021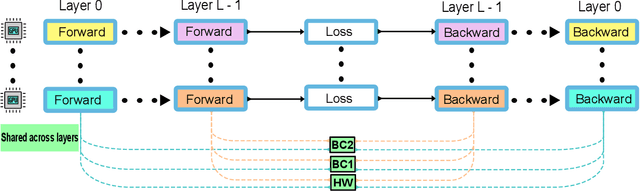
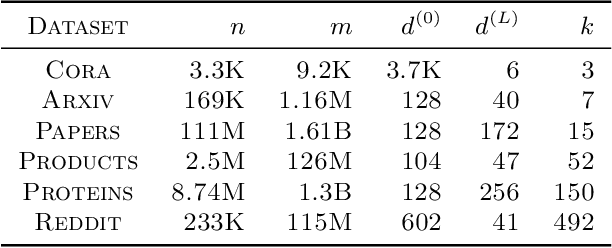
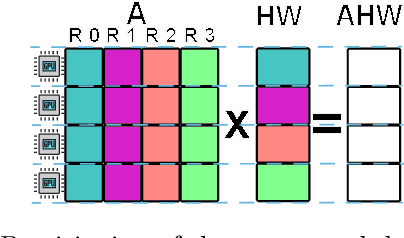
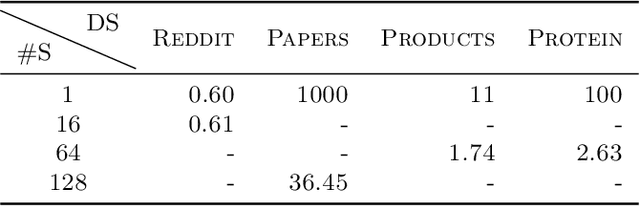
Full batch training of Graph Convolutional Network (GCN) models is not feasible on a single GPU for large graphs containing tens of millions of vertices or more. Recent work has shown that, for the graphs used in the machine learning community, communication becomes a bottleneck and scaling is blocked outside of the single machine regime. Thus, we propose MG-GCN, a multi-GPU GCN training framework taking advantage of the high-speed communication links between the GPUs present in multi-GPU systems. MG-GCN employs multiple High-Performance Computing optimizations, including efficient re-use of memory buffers to reduce the memory footprint of training GNN models, as well as communication and computation overlap. These optimizations enable execution on larger datasets, that generally do not fit into memory of a single GPU in state-of-the-art implementations. Furthermore, they contribute to achieve superior speedup compared to the state-of-the-art. For example, MG-GCN achieves super-linear speedup with respect to DGL, on the Reddit graph on both DGX-1 (V100) and DGX-A100.