 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImitate then Transcend: Multi-Agent Optimal Execution with Dual-Window Denoise PPO
Jun 21, 2022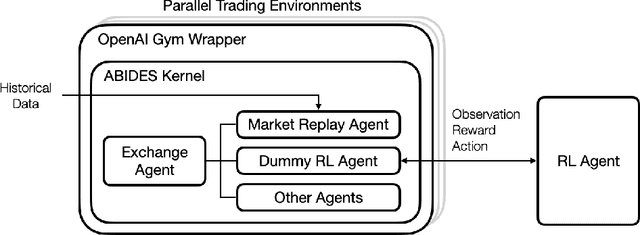
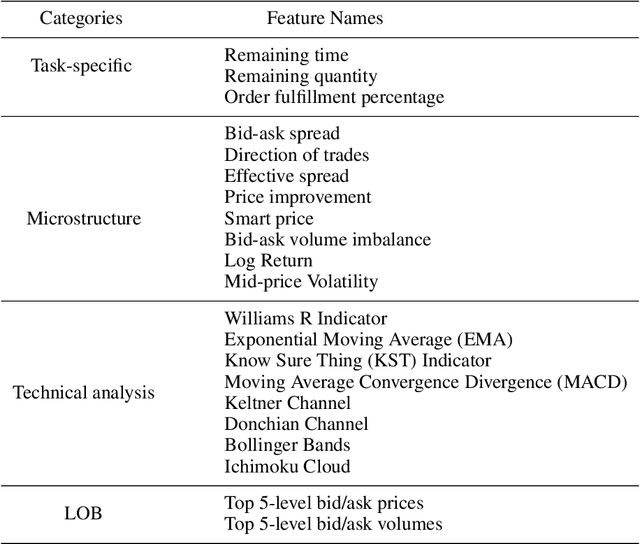
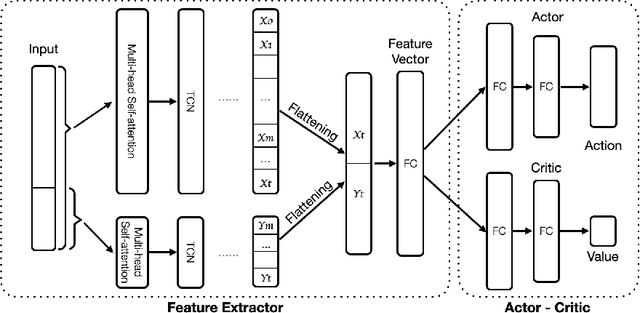
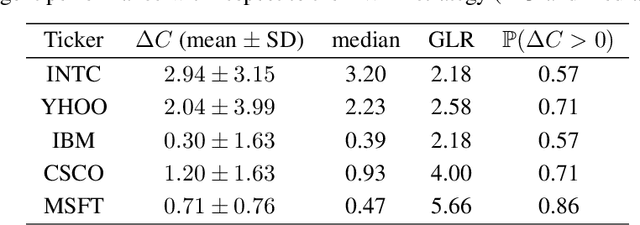
A novel framework for solving the optimal execution and placement problems using reinforcement learning (RL) with imitation was proposed. The RL agents trained from the proposed framework consistently outperformed the industry benchmark time-weighted average price (TWAP) strategy in execution cost and showed great generalization across out-of-sample trading dates and tickers. The impressive performance was achieved from three aspects. First, our RL network architecture called Dual-window Denoise PPO enabled efficient learning in a noisy market environment. Second, a reward scheme with imitation learning was designed, and a comprehensive set of market features was studied. Third, our flexible action formulation allowed the RL agent to tackle optimal execution and placement collectively resulting in better performance than solving individual problems separately. The RL agent's performance was evaluated in our multi-agent realistic historical limit order book simulator in which price impact was accurately assessed. In addition, ablation studies were also performed, confirming the superiority of our framework.