 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhat can Data-Centric AI Learn from Data and ML Engineering?
Dec 13, 2021Data-centric AI is a new and exciting research topic in the AI community, but many organizations already build and maintain various "data-centric" applications whose goal is to produce high quality data. These range from traditional business data processing applications (e.g., "how much should we charge each of our customers this month?") to production ML systems such as recommendation engines. The fields of data and ML engineering have arisen in recent years to manage these applications, and both include many interesting novel tools and processes. In this paper, we discuss several lessons from data and ML engineering that could be interesting to apply in data-centric AI, based on our experience building data and ML platforms that serve thousands of applications at a range of organizations.
Production Machine Learning Pipelines: Empirical Analysis and Optimization Opportunities
Mar 30, 2021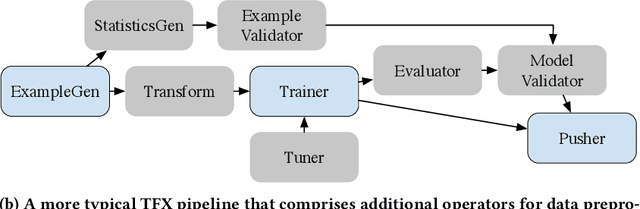
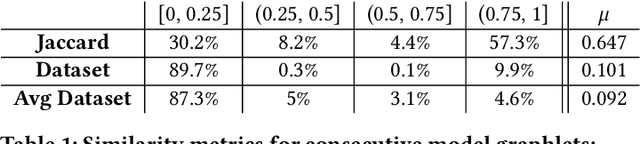
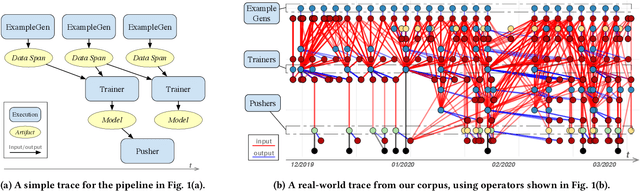
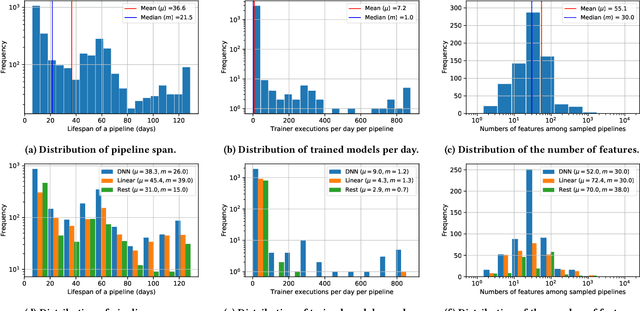
Machine learning (ML) is now commonplace, powering data-driven applications in various organizations. Unlike the traditional perception of ML in research, ML production pipelines are complex, with many interlocking analytical components beyond training, whose sub-parts are often run multiple times on overlapping subsets of data. However, there is a lack of quantitative evidence regarding the lifespan, architecture, frequency, and complexity of these pipelines to understand how data management research can be used to make them more efficient, effective, robust, and reproducible. To that end, we analyze the provenance graphs of 3000 production ML pipelines at Google, comprising over 450,000 models trained, spanning a period of over four months, in an effort to understand the complexity and challenges underlying production ML. Our analysis reveals the characteristics, components, and topologies of typical industry-strength ML pipelines at various granularities. Along the way, we introduce a specialized data model for representing and reasoning about repeatedly run components in these ML pipelines, which we call model graphlets. We identify several rich opportunities for optimization, leveraging traditional data management ideas. We show how targeting even one of these opportunities, i.e., identifying and pruning wasted computation that does not translate to model deployment, can reduce wasted computation cost by 50% without compromising the model deployment cadence.
Towards ML Engineering: A Brief History Of TensorFlow Extended
Oct 07, 2020Software Engineering, as a discipline, has matured over the past 5+ decades. The modern world heavily depends on it, so the increased maturity of Software Engineering was an eventuality. Practices like testing and reliable technologies help make Software Engineering reliable enough to build industries upon. Meanwhile, Machine Learning (ML) has also grown over the past 2+ decades. ML is used more and more for research, experimentation and production workloads. ML now commonly powers widely-used products integral to our lives. But ML Engineering, as a discipline, has not widely matured as much as its Software Engineering ancestor. Can we take what we have learned and help the nascent field of applied ML evolve into ML Engineering the way Programming evolved into Software Engineering [1]? In this article we will give a whirlwind tour of Sibyl [2] and TensorFlow Extended (TFX) [3], two successive end-to-end (E2E) ML platforms at Alphabet. We will share the lessons learned from over a decade of applied ML built on these platforms, explain both their similarities and their differences, and expand on the shifts (both mental and technical) that helped us on our journey. In addition, we will highlight some of the capabilities of TFX that help realize several aspects of ML Engineering. We argue that in order to unlock the gains ML can bring, organizations should advance the maturity of their ML teams by investing in robust ML infrastructure and promoting ML Engineering education. We also recommend that before focusing on cutting-edge ML modeling techniques, product leaders should invest more time in adopting interoperable ML platforms for their organizations. In closing, we will also share a glimpse into the future of TFX.
Improving Differentially Private Models with Active Learning
Oct 02, 2019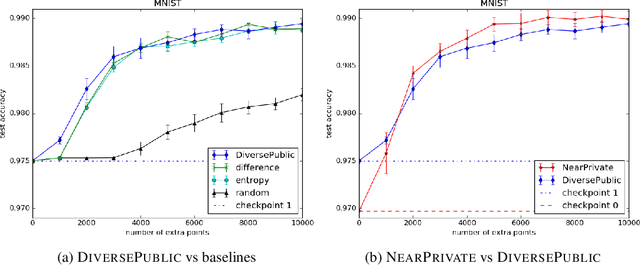
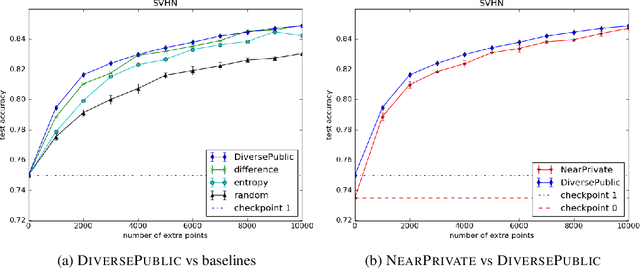
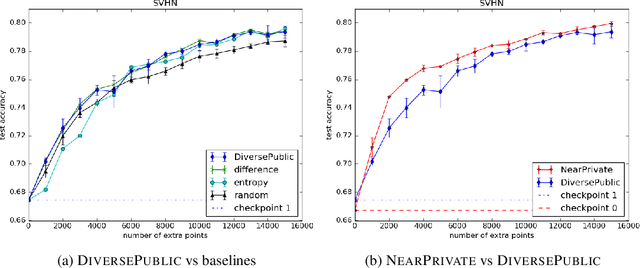
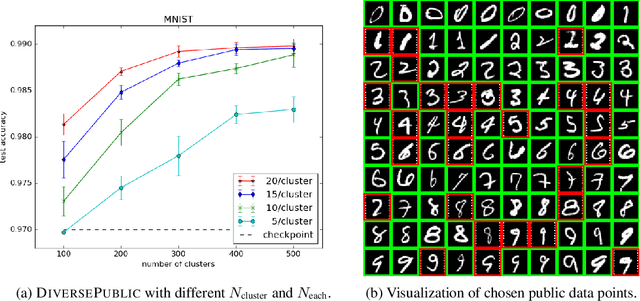
Broad adoption of machine learning techniques has increased privacy concerns for models trained on sensitive data such as medical records. Existing techniques for training differentially private (DP) models give rigorous privacy guarantees, but applying these techniques to neural networks can severely degrade model performance. This performance reduction is an obstacle to deploying private models in the real world. In this work, we improve the performance of DP models by fine-tuning them through active learning on public data. We introduce two new techniques - DIVERSEPUBLIC and NEARPRIVATE - for doing this fine-tuning in a privacy-aware way. For the MNIST and SVHN datasets, these techniques improve state-of-the-art accuracy for DP models while retaining privacy guarantees.
Slice Finder: Automated Data Slicing for Model Validation
Aug 01, 2018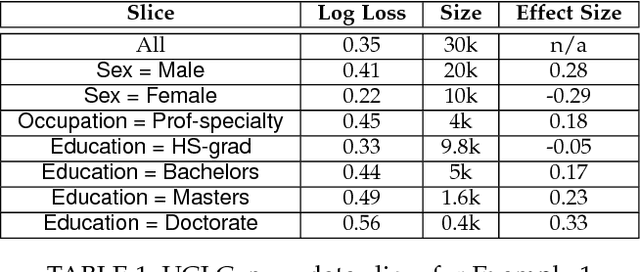
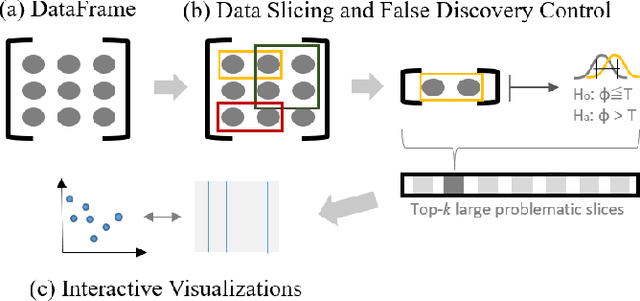

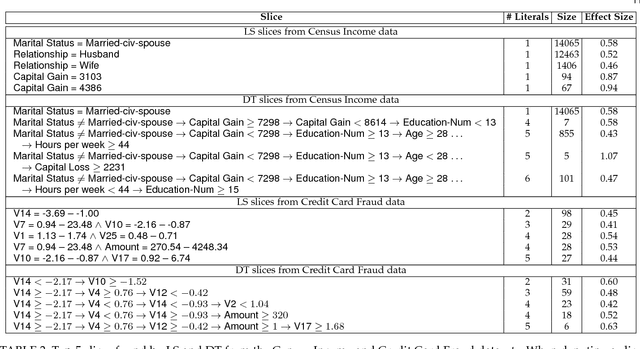
As machine learning (ML) systems become democratized, it becomes increasingly important to help users easily debug their models. However, current data tools are still primitive when it comes to helping users trace model performance problems all the way to the data. We focus on the particular problem of slicing data to identify subsets of the validation data where the model performs poorly. This is an important problem in model validation because the overall model performance can fail to reflect that of the smaller subsets, and slicing allows users to analyze the model performance on a more granular-level. Unlike general techniques (e.g., clustering) that can find arbitrary slices, our goal is to find interpretable slices (which are easier to take action compared to arbitrary subsets) that are problematic and large. We propose Slice Finder, which is an interactive framework for identifying such slices using statistical techniques. Applications include diagnosing model fairness and fraud detection, where identifying slices that are interpretable to humans is crucial.
The Case for Learned Index Structures
Apr 30, 2018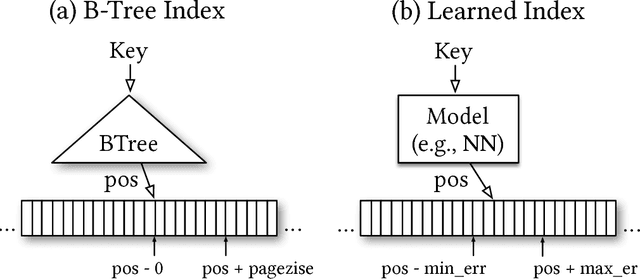

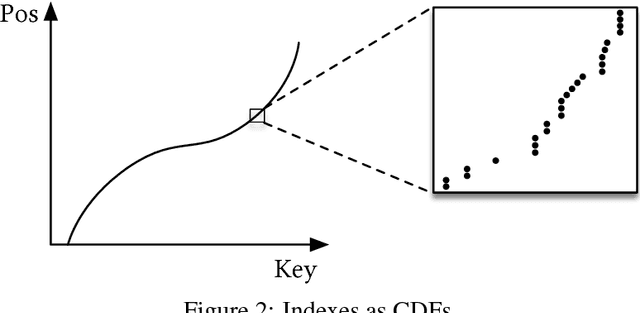
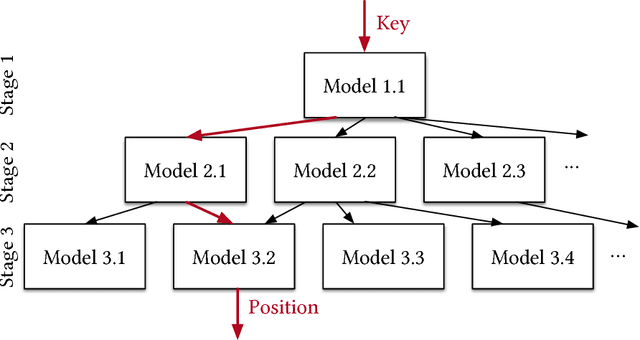
Indexes are models: a B-Tree-Index can be seen as a model to map a key to the position of a record within a sorted array, a Hash-Index as a model to map a key to a position of a record within an unsorted array, and a BitMap-Index as a model to indicate if a data record exists or not. In this exploratory research paper, we start from this premise and posit that all existing index structures can be replaced with other types of models, including deep-learning models, which we term learned indexes. The key idea is that a model can learn the sort order or structure of lookup keys and use this signal to effectively predict the position or existence of records. We theoretically analyze under which conditions learned indexes outperform traditional index structures and describe the main challenges in designing learned index structures. Our initial results show, that by using neural nets we are able to outperform cache-optimized B-Trees by up to 70% in speed while saving an order-of-magnitude in memory over several real-world data sets. More importantly though, we believe that the idea of replacing core components of a data management system through learned models has far reaching implications for future systems designs and that this work just provides a glimpse of what might be possible.
Iterative MapReduce for Large Scale Machine Learning
Mar 13, 2013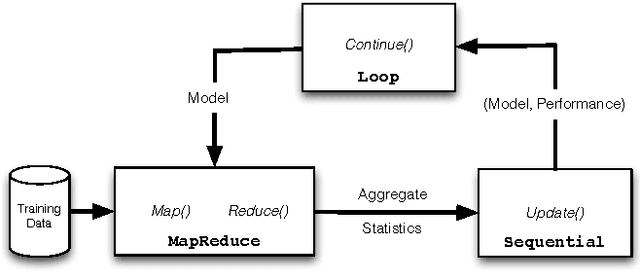

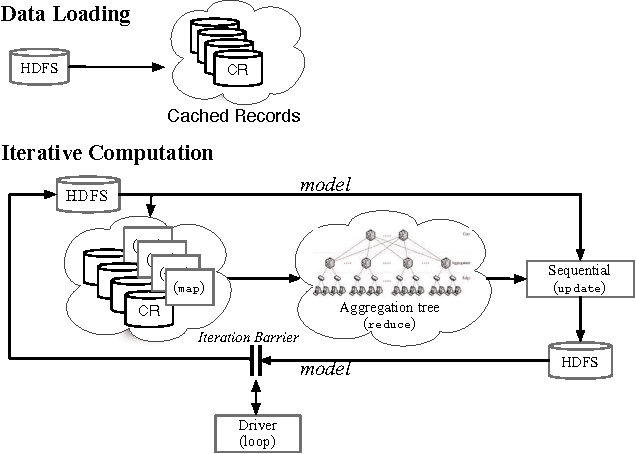

Large datasets ("Big Data") are becoming ubiquitous because the potential value in deriving insights from data, across a wide range of business and scientific applications, is increasingly recognized. In particular, machine learning - one of the foundational disciplines for data analysis, summarization and inference - on Big Data has become routine at most organizations that operate large clouds, usually based on systems such as Hadoop that support the MapReduce programming paradigm. It is now widely recognized that while MapReduce is highly scalable, it suffers from a critical weakness for machine learning: it does not support iteration. Consequently, one has to program around this limitation, leading to fragile, inefficient code. Further, reliance on the programmer is inherently flawed in a multi-tenanted cloud environment, since the programmer does not have visibility into the state of the system when his or her program executes. Prior work has sought to address this problem by either developing specialized systems aimed at stylized applications, or by augmenting MapReduce with ad hoc support for saving state across iterations (driven by an external loop). In this paper, we advocate support for looping as a first-class construct, and propose an extension of the MapReduce programming paradigm called {\em Iterative MapReduce}. We then develop an optimizer for a class of Iterative MapReduce programs that cover most machine learning techniques, provide theoretical justifications for the key optimization steps, and empirically demonstrate that system-optimized programs for significant machine learning tasks are competitive with state-of-the-art specialized solutions.
Scaling Datalog for Machine Learning on Big Data
Mar 02, 2012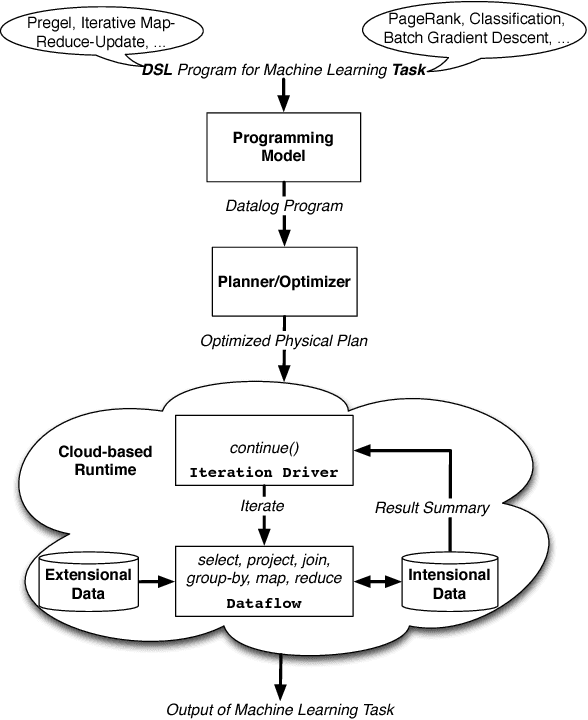
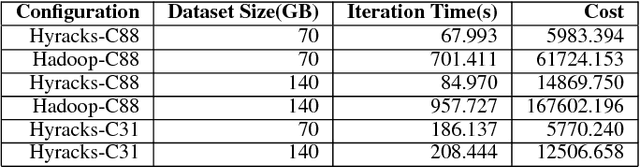
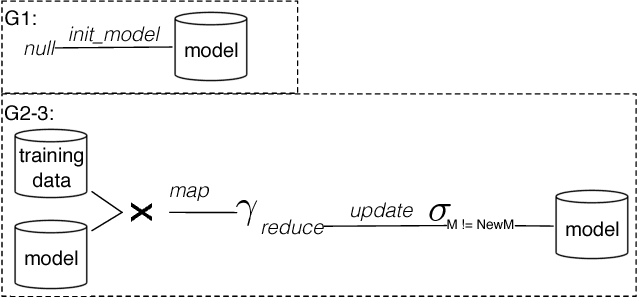
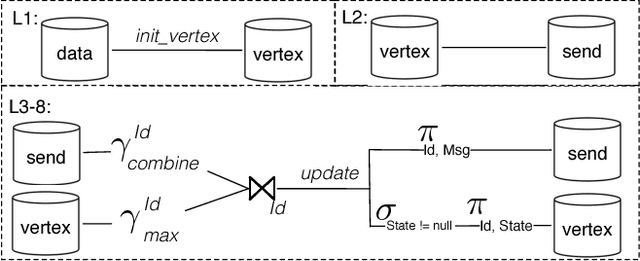
In this paper, we present the case for a declarative foundation for data-intensive machine learning systems. Instead of creating a new system for each specific flavor of machine learning task, or hardcoding new optimizations, we argue for the use of recursive queries to program a variety of machine learning systems. By taking this approach, database query optimization techniques can be utilized to identify effective execution plans, and the resulting runtime plans can be executed on a single unified data-parallel query processing engine. As a proof of concept, we consider two programming models--Pregel and Iterative Map-Reduce-Update---from the machine learning domain, and show how they can be captured in Datalog, tuned for a specific task, and then compiled into an optimized physical plan. Experiments performed on a large computing cluster with real data demonstrate that this declarative approach can provide very good performance while offering both increased generality and programming ease.