 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWeakly Supervised Label Learning Flows
Feb 19, 2023



Supervised learning usually requires a large amount of labelled data. However, attaining ground-truth labels is costly for many tasks. Alternatively, weakly supervised methods learn with cheap weak signals that only approximately label some data. Many existing weakly supervised learning methods learn a deterministic function that estimates labels given the input data and weak signals. In this paper, we develop label learning flows (LLF), a general framework for weakly supervised learning problems. Our method is a generative model based on normalizing flows. The main idea of LLF is to optimize the conditional likelihoods of all possible labelings of the data within a constrained space defined by weak signals. We develop a training method for LLF that trains the conditional flow inversely and avoids estimating the labels. Once a model is trained, we can make predictions with a sampling algorithm. We apply LLF to three weakly supervised learning problems. Experiment results show that our method outperforms many baselines we compare against.
Data Consistency for Weakly Supervised Learning
Feb 08, 2022In many applications, training machine learning models involves using large amounts of human-annotated data. Obtaining precise labels for the data is expensive. Instead, training with weak supervision provides a low-cost alternative. We propose a novel weak supervision algorithm that processes noisy labels, i.e., weak signals, while also considering features of the training data to produce accurate labels for training. Our method searches over classifiers of the data representation to find plausible labelings. We call this paradigm data consistent weak supervision. A key facet of our framework is that we are able to estimate labels for data examples low or no coverage from the weak supervision. In addition, we make no assumptions about the joint distribution of the weak signals and true labels of the data. Instead, we use weak signals and the data features to solve a constrained optimization that enforces data consistency among the labels we generate. Empirical evaluation of our method on different datasets shows that it significantly outperforms state-of-the-art weak supervision methods on both text and image classification tasks.
Constrained Labeling for Weakly Supervised Learning
Sep 15, 2020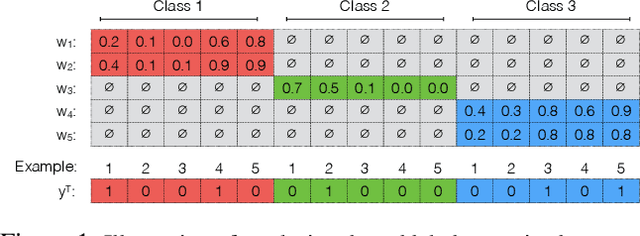
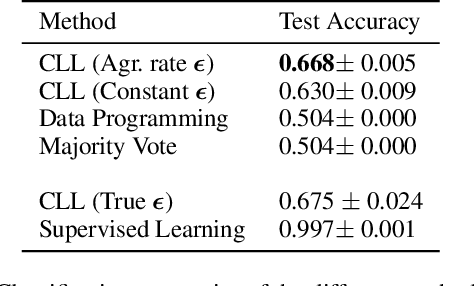
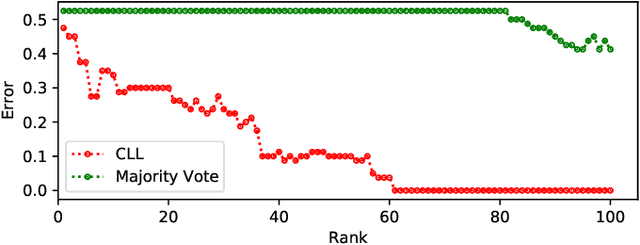
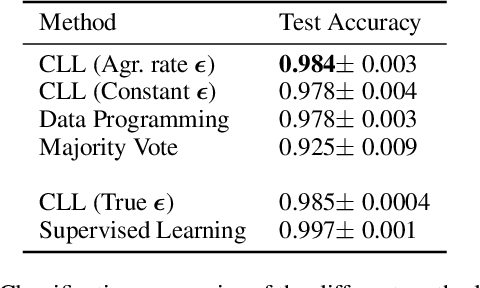
Curation of large fully supervised datasets has become one of the major roadblocks for machine learning. Weak supervision provides an alternative to supervised learning by training with cheap, noisy, and possibly correlated labeling functions from varying sources. The key challenge in weakly supervised learning is combining the different weak supervision signals while navigating misleading correlations in their errors. In this paper, we propose a simple data-free approach for combining weak supervision signals by defining a constrained space for the possible labels of the weak signals and training with a random labeling within this constrained space. Our method is efficient and stable, converging after a few iterations of gradient descent. We prove theoretical conditions under which the worst-case error of the randomized label decreases with the rank of the linear constraints. We show experimentally that our method outperforms other weak supervision methods on various text- and image-classification tasks.
Woodbury Transformations for Deep Generative Flows
Feb 27, 2020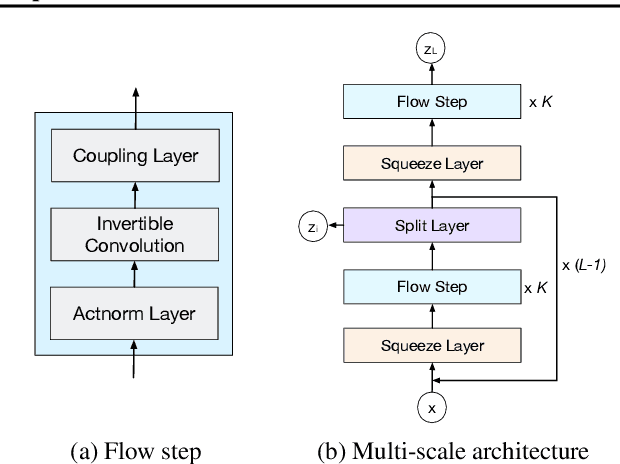
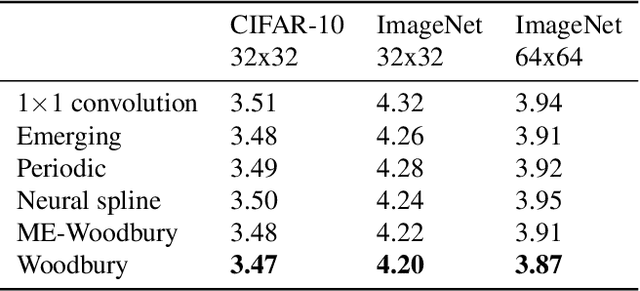
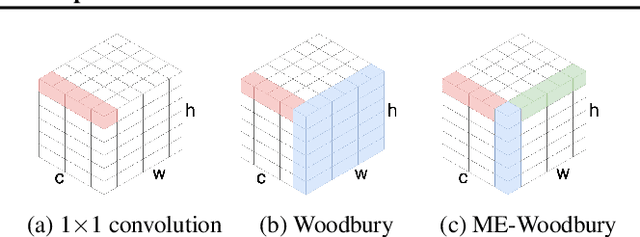
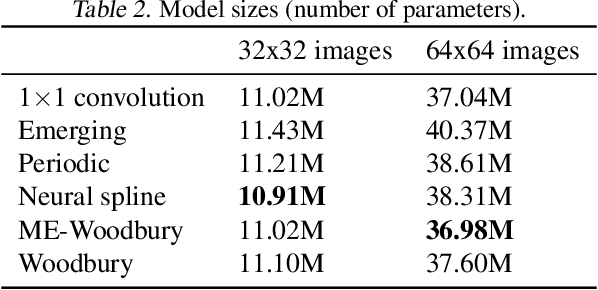
Normalizing flows are deep generative models that allow efficient likelihood calculation and sampling. The core requirement for this advantage is that they are constructed using functions that can be efficiently inverted and for which the determinant of the function's Jacobian can be efficiently computed. Researchers have introduced various such flow operations, but few of these allow rich interactions among variables without incurring significant computational costs. In this paper, we introduce Woodbury transformations, which achieve efficient invertibility via the Woodbury matrix identity and efficient determinant calculation via Sylvester's determinant identity. In contrast with other operations used in state-of-the-art normalizing flows, Woodbury transformations enable (1) high-dimensional interactions, (2) efficient sampling, and (3) efficient likelihood evaluation. Other similar operations, such as 1x1 convolutions, emerging convolutions, or periodic convolutions allow at most two of these three advantages. In our experiments on multiple image datasets, we find that Woodbury transformations allow learning of higher-likelihood models than other flow architectures while still enjoying their efficiency advantages.
Active Learning by Greedy Split and Label Exploration
Jun 17, 2019
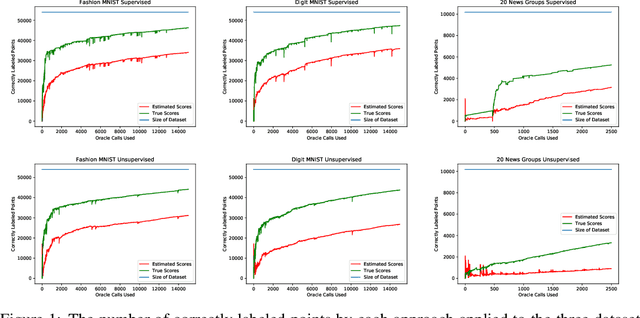

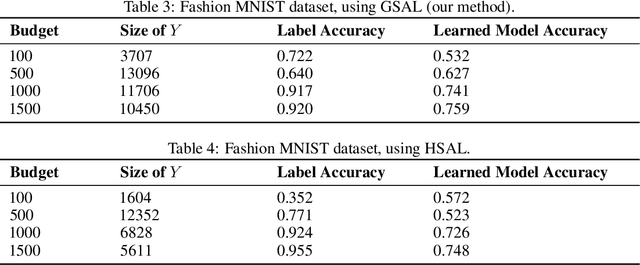
Annotating large unlabeled datasets can be a major bottleneck for machine learning applications. We introduce a scheme for inferring labels of unlabeled data at a fraction of the cost of labeling the entire dataset. We refer to the scheme as greedy split and label exploration (GSAL). GSAL greedily queries an oracle (or human labeler) and partitions a dataset to find data subsets that have mostly the same label. GSAL can then infer labels by majority vote of the known labels in each subset. GSAL makes the decision to split or label from a subset by maximizing a lower bound on the expected number of correctly labeled examples. GSAL improves upon existing hierarchical labeling schemes by using supervised models to partition the data, therefore avoiding reliance on unsupervised clustering methods that may not accurately group data by label. We design GSAL with strategies to avoid bias that could be introduced through this adaptive partitioning. We evaluate GSAL on labeling of three datasets and find that it outperforms existing strategies for adaptive labeling.
Labeled Graph Generative Adversarial Networks
Jun 07, 2019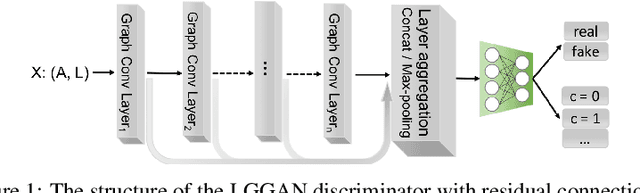
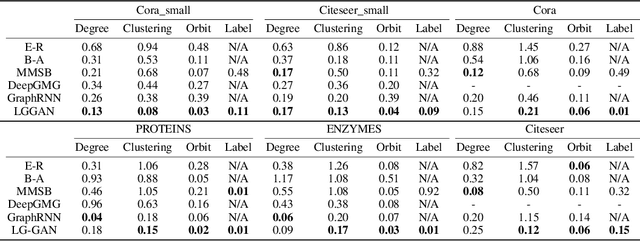
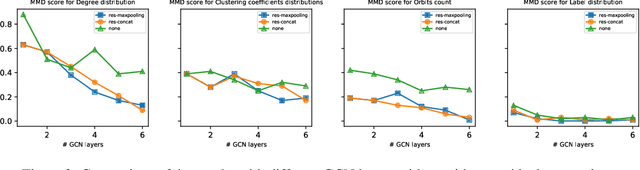

As a new way to train generative models, generative adversarial networks (GANs) have achieved considerable success in image generation, and this framework has also recently been applied to data with graph structures. We identify the drawbacks of existing deep frameworks for generating graphs, and we propose labeled-graph generative adversarial networks (LGGAN) to train deep generative models for graph-structured data with node labels. We test the approach on various types of graph datasets, such as collections of citation networks and protein graphs. Experiment results show that our model can generate diverse labeled graphs that match the structural characteristics of the training data and outperforms all baselines in terms of quality, generality, and scalability. To further evaluate the quality of the generated graphs, we apply it to a downstream task for graph classification, and the results show that LGGAN can better capture the important aspects of the graph structure.
An Adaptable Framework for Deep Adversarial Label Learning from Weak Supervision
Jun 03, 2019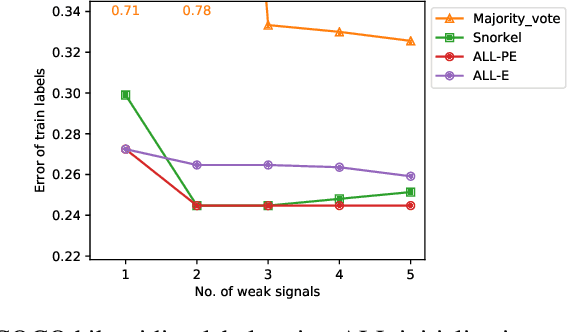
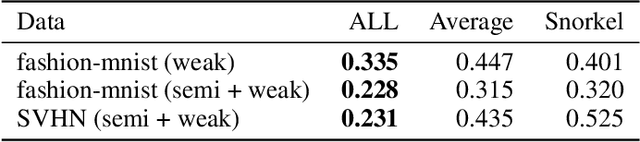
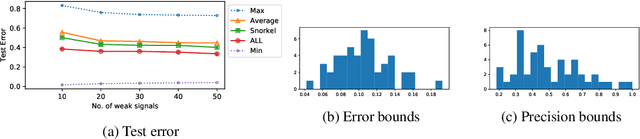
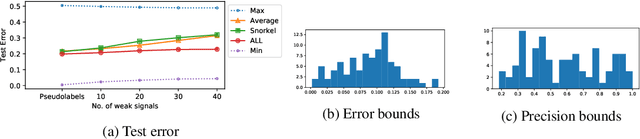
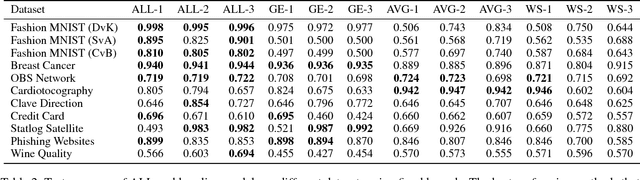
In this paper, we propose a general framework for using adversarial label learning (ALL) [1] for multiclass classification when the data is weakly supervised. We introduce a new variant of ALL that incorporates human knowledge through multiple constraint types. Like adversarial label learning, we learn by adversarially finding labels constrained to be partially consistent with the weak supervision. However, we describe a different approach to solve the optimization that enjoys faster convergence when training large deep models. Our framework allows for human knowledge to be encoded into the algorithm as a set of linear constraints. We then solve a two-player game optimization subject to these constraints. We test our method on three data sets by training convolutional neural network models that learn to classify image objects with limited access to training labels. Our approach is able to learn even in settings where the weak supervision confounds state-of-the-art weakly supervised learning methods. The results of our experiments demonstrate the applicability of this approach to general classification tasks.
Structured Output Learning with Conditional Generative Flows
May 30, 2019



Traditional structured prediction models try to learn the conditional likelihood, i.e., p(y|x), to capture the relationship between the structured output y and the input features x. For many models, computing the likelihood is intractable. These models are therefore hard to train, requiring the use of surrogate objectives or variational inference to approximate likelihood. In this paper, we propose conditional Glow (c-Glow), a conditional generative flow for structured output learning. C-Glow benefits from the ability of flow-based models to compute p(y|x) exactly and efficiently. Learning with c-Glow does not require a surrogate objective or performing inference during training. Once trained, we can directly and efficiently generate conditional samples to do structured prediction. We evaluate this approach on different structured prediction tasks and find c-Glow's structured outputs comparable in quality with state-of-the-art deep structured prediction approaches.
Block Belief Propagation for Parameter Learning in Markov Random Fields
Nov 09, 2018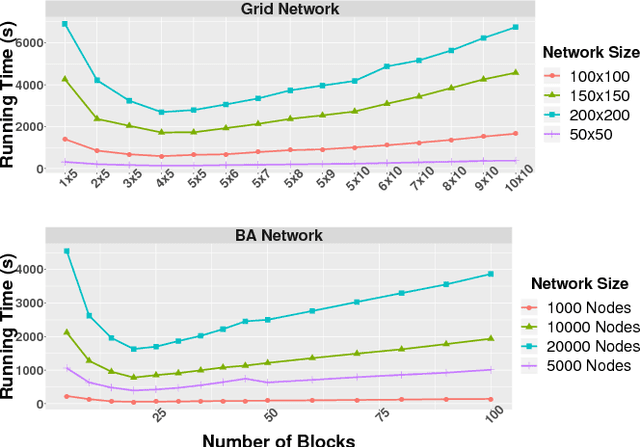
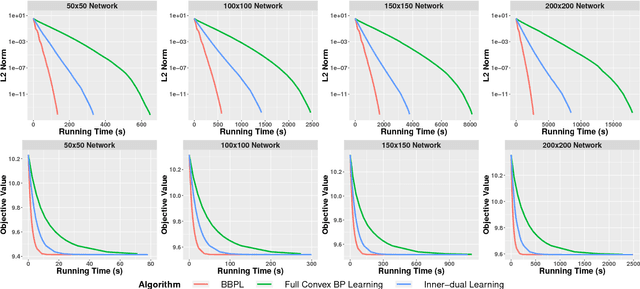
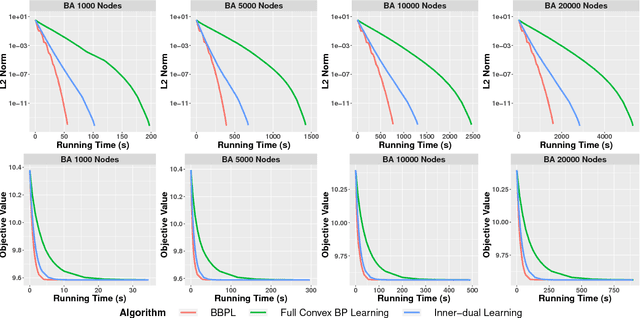
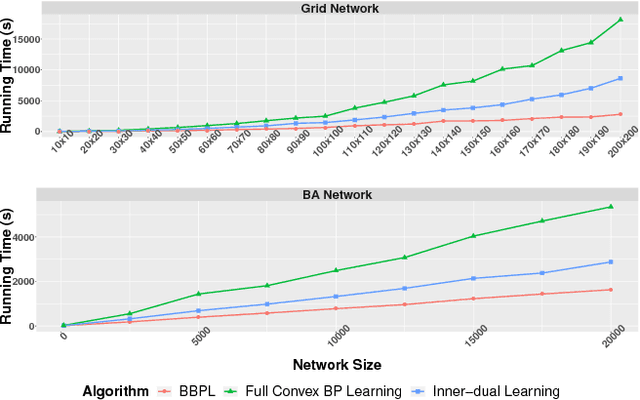
Traditional learning methods for training Markov random fields require doing inference over all variables to compute the likelihood gradient. The iteration complexity for those methods therefore scales with the size of the graphical models. In this paper, we propose \emph{block belief propagation learning} (BBPL), which uses block-coordinate updates of approximate marginals to compute approximate gradients, removing the need to compute inference on the entire graphical model. Thus, the iteration complexity of BBPL does not scale with the size of the graphs. We prove that the method converges to the same solution as that obtained by using full inference per iteration, despite these approximations, and we empirically demonstrate its scalability improvements over standard training methods.
Adversarial Labeling for Learning without Labels
Jun 07, 2018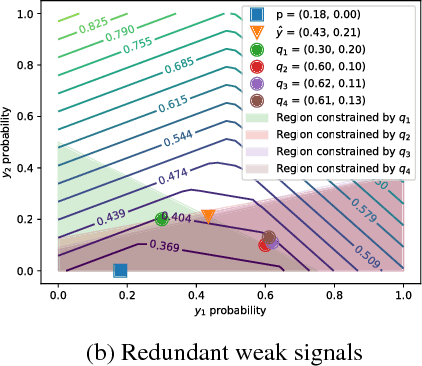
We consider the task of training classifiers without labels. We propose a weakly supervised method---adversarial label learning---that trains classifiers to perform well against an adversary that chooses labels for training data. The weak supervision constrains what labels the adversary can choose. The method therefore minimizes an upper bound of the classifier's error rate using projected primal-dual subgradient descent. Minimizing this bound protects against bias and dependencies in the weak supervision. Experiments on three real datasets show that our method can train without labels and outperforms other approaches for weakly supervised learning.