 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeActive Learning by Greedy Split and Label Exploration
Paper and Code
Jun 17, 2019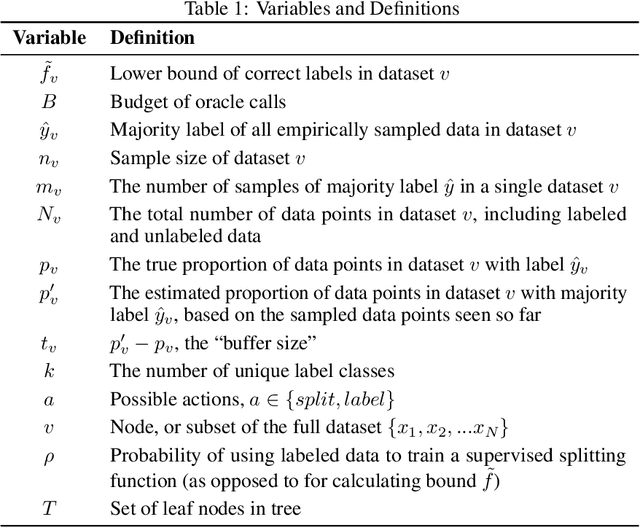
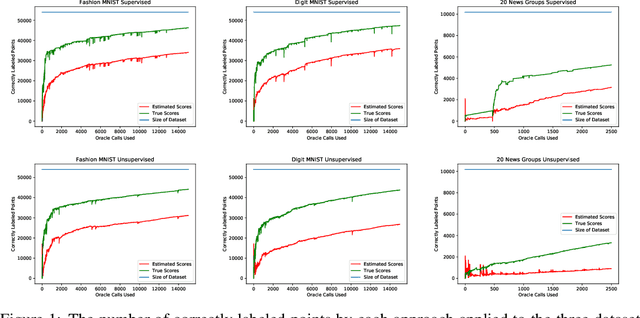

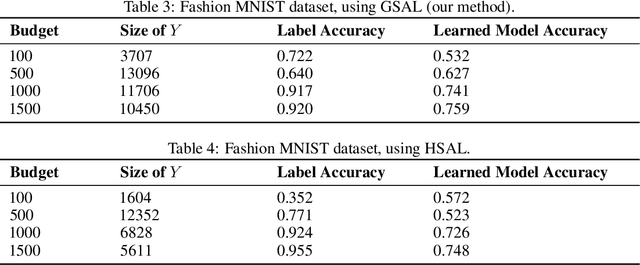
Annotating large unlabeled datasets can be a major bottleneck for machine learning applications. We introduce a scheme for inferring labels of unlabeled data at a fraction of the cost of labeling the entire dataset. We refer to the scheme as greedy split and label exploration (GSAL). GSAL greedily queries an oracle (or human labeler) and partitions a dataset to find data subsets that have mostly the same label. GSAL can then infer labels by majority vote of the known labels in each subset. GSAL makes the decision to split or label from a subset by maximizing a lower bound on the expected number of correctly labeled examples. GSAL improves upon existing hierarchical labeling schemes by using supervised models to partition the data, therefore avoiding reliance on unsupervised clustering methods that may not accurately group data by label. We design GSAL with strategies to avoid bias that could be introduced through this adaptive partitioning. We evaluate GSAL on labeling of three datasets and find that it outperforms existing strategies for adaptive labeling.