 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExpertAD: Enhancing Autonomous Driving Systems with Mixture of Experts
Nov 13, 2025Recent advancements in end-to-end autonomous driving systems (ADSs) underscore their potential for perception and planning capabilities. However, challenges remain. Complex driving scenarios contain rich semantic information, yet ambiguous or noisy semantics can compromise decision reliability, while interference between multiple driving tasks may hinder optimal planning. Furthermore, prolonged inference latency slows decision-making, increasing the risk of unsafe driving behaviors. To address these challenges, we propose ExpertAD, a novel framework that enhances the performance of ADS with Mixture of Experts (MoE) architecture. We introduce a Perception Adapter (PA) to amplify task-critical features, ensuring contextually relevant scene understanding, and a Mixture of Sparse Experts (MoSE) to minimize task interference during prediction, allowing for effective and efficient planning. Our experiments show that ExpertAD reduces average collision rates by up to 20% and inference latency by 25% compared to prior methods. We further evaluate its multi-skill planning capabilities in rare scenarios (e.g., accidents, yielding to emergency vehicles) and demonstrate strong generalization to unseen urban environments. Additionally, we present a case study that illustrates its decision-making process in complex driving scenarios.
Argus: Resilience-Oriented Safety Assurance Framework for End-to-End ADSs
Nov 12, 2025End-to-end autonomous driving systems (ADSs), with their strong capabilities in environmental perception and generalizable driving decisions, are attracting growing attention from both academia and industry. However, once deployed on public roads, ADSs are inevitably exposed to diverse driving hazards that may compromise safety and degrade system performance. This raises a strong demand for resilience of ADSs, particularly the capability to continuously monitor driving hazards and adaptively respond to potential safety violations, which is crucial for maintaining robust driving behaviors in complex driving scenarios. To bridge this gap, we propose a runtime resilience-oriented framework, Argus, to mitigate the driving hazards, thus preventing potential safety violations and improving the driving performance of an ADS. Argus continuously monitors the trajectories generated by the ADS for potential hazards and, whenever the EGO vehicle is deemed unsafe, seamlessly takes control through a hazard mitigator. We integrate Argus with three state-of-the-art end-to-end ADSs, i.e., TCP, UniAD and VAD. Our evaluation has demonstrated that Argus effectively and efficiently enhances the resilience of ADSs, improving the driving score of the ADS by up to 150.30% on average, and preventing up to 64.38% of the violations, with little additional time overhead.
* The paper has been accepted by the 40th IEEE/ACM International Conference on Automated Software Engineering, ASE 2025
RoadGen: Generating Road Scenarios for Autonomous Vehicle Testing
Nov 29, 2024



With the rapid development of autonomous vehicles, there is an increasing demand for scenario-based testing to simulate diverse driving scenarios. However, as the base of any driving scenarios, road scenarios (e.g., road topology and geometry) have received little attention by the literature. Despite several advances, they either generate basic road components without a complete road network, or generate a complete road network but with simple road components. The resulting road scenarios lack diversity in both topology and geometry. To address this problem, we propose RoadGen to systematically generate diverse road scenarios. The key idea is to connect eight types of parameterized road components to form road scenarios with high diversity in topology and geometry. Our evaluation has demonstrated the effectiveness and usefulness of RoadGen in generating diverse road scenarios for simulation.
AdvFuzz: Finding More Violations Caused by the EGO Vehicle in Simulation Testing by Adversarial NPC Vehicles
Nov 29, 2024



Recently, there has been a significant escalation in both academic and industrial commitment towards the development of autonomous driving systems (ADSs). A number of simulation testing approaches have been proposed to generate diverse driving scenarios for ADS testing. However, scenarios generated by these previous approaches are static and lack interactions between the EGO vehicle and the NPC vehicles, resulting in a large amount of time on average to find violation scenarios. Besides, a large number of the violations they found are caused by aggressive behaviors of NPC vehicles, revealing none bugs of ADS. In this work, we propose the concept of adversarial NPC vehicles and introduce AdvFuzz, a novel simulation testing approach, to generate adversarial scenarios on main lanes (e.g., urban roads and highways). AdvFuzz allows NPC vehicles to dynamically interact with the EGO vehicle and regulates the behaviors of NPC vehicles, finding more violation scenarios caused by the EGO vehicle more quickly. We compare AdvFuzz with a random approach and three state-of-the-art scenario-based testing approaches. Our experiments demonstrate that AdvFuzz can generate 198.34% more violation scenarios compared to the other four approaches in 12 hours and increase the proportion of violations caused by the EGO vehicle to 87.04%, which is more than 7 times that of other approaches. Additionally, AdvFuzz is at least 92.21% faster in finding one violation caused by the EGO vehicle than that of the other approaches.
Weakly Supervised Label Learning Flows
Feb 19, 2023



Supervised learning usually requires a large amount of labelled data. However, attaining ground-truth labels is costly for many tasks. Alternatively, weakly supervised methods learn with cheap weak signals that only approximately label some data. Many existing weakly supervised learning methods learn a deterministic function that estimates labels given the input data and weak signals. In this paper, we develop label learning flows (LLF), a general framework for weakly supervised learning problems. Our method is a generative model based on normalizing flows. The main idea of LLF is to optimize the conditional likelihoods of all possible labelings of the data within a constrained space defined by weak signals. We develop a training method for LLF that trains the conditional flow inversely and avoids estimating the labels. Once a model is trained, we can make predictions with a sampling algorithm. We apply LLF to three weakly supervised learning problems. Experiment results show that our method outperforms many baselines we compare against.
Woodbury Transformations for Deep Generative Flows
Feb 27, 2020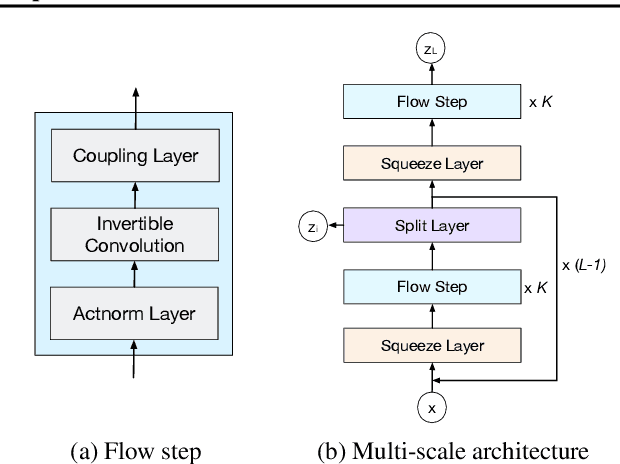
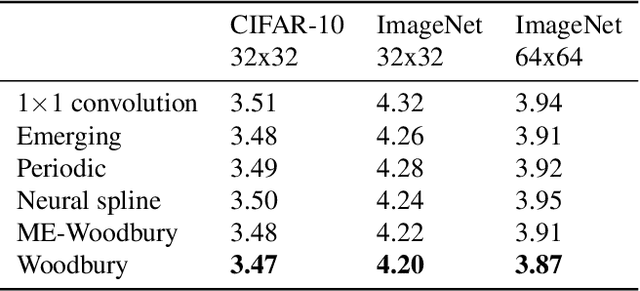
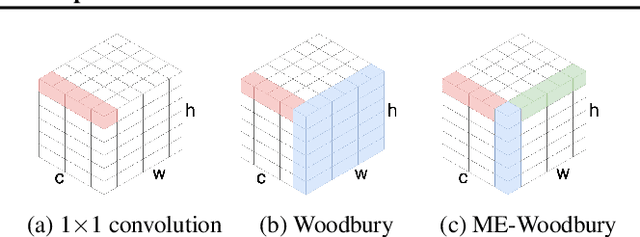
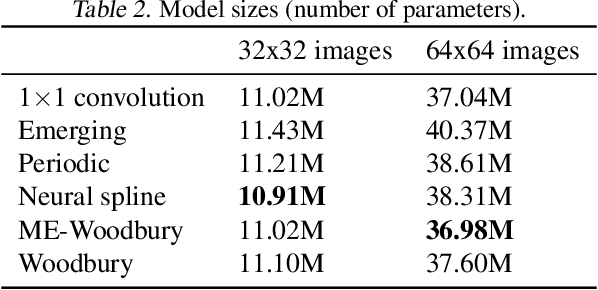
Normalizing flows are deep generative models that allow efficient likelihood calculation and sampling. The core requirement for this advantage is that they are constructed using functions that can be efficiently inverted and for which the determinant of the function's Jacobian can be efficiently computed. Researchers have introduced various such flow operations, but few of these allow rich interactions among variables without incurring significant computational costs. In this paper, we introduce Woodbury transformations, which achieve efficient invertibility via the Woodbury matrix identity and efficient determinant calculation via Sylvester's determinant identity. In contrast with other operations used in state-of-the-art normalizing flows, Woodbury transformations enable (1) high-dimensional interactions, (2) efficient sampling, and (3) efficient likelihood evaluation. Other similar operations, such as 1x1 convolutions, emerging convolutions, or periodic convolutions allow at most two of these three advantages. In our experiments on multiple image datasets, we find that Woodbury transformations allow learning of higher-likelihood models than other flow architectures while still enjoying their efficiency advantages.
Structured Output Learning with Conditional Generative Flows
May 30, 2019



Traditional structured prediction models try to learn the conditional likelihood, i.e., p(y|x), to capture the relationship between the structured output y and the input features x. For many models, computing the likelihood is intractable. These models are therefore hard to train, requiring the use of surrogate objectives or variational inference to approximate likelihood. In this paper, we propose conditional Glow (c-Glow), a conditional generative flow for structured output learning. C-Glow benefits from the ability of flow-based models to compute p(y|x) exactly and efficiently. Learning with c-Glow does not require a surrogate objective or performing inference during training. Once trained, we can directly and efficiently generate conditional samples to do structured prediction. We evaluate this approach on different structured prediction tasks and find c-Glow's structured outputs comparable in quality with state-of-the-art deep structured prediction approaches.
Block Belief Propagation for Parameter Learning in Markov Random Fields
Nov 09, 2018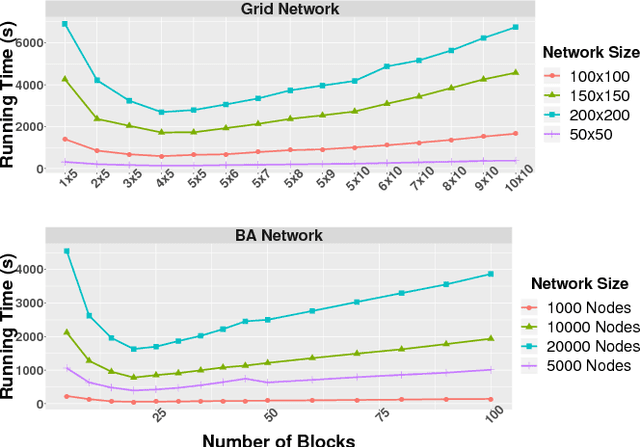
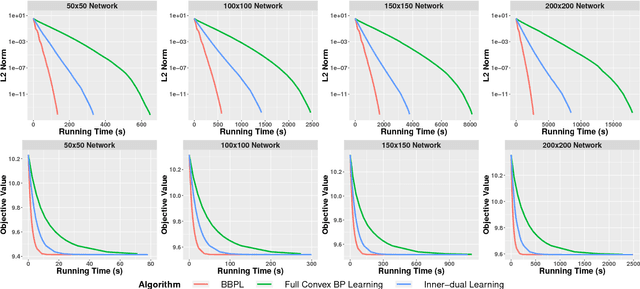
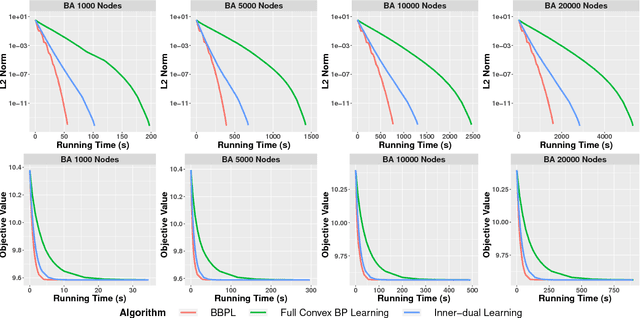
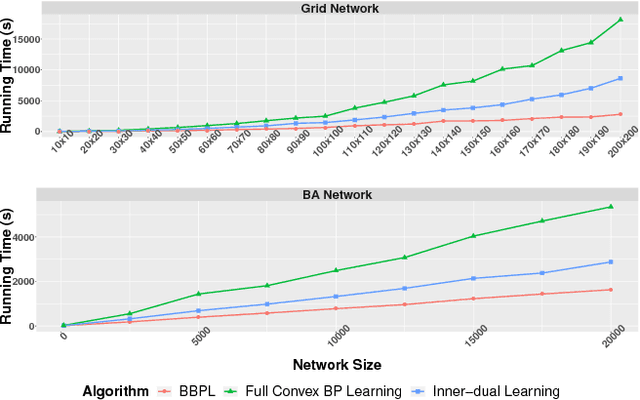
Traditional learning methods for training Markov random fields require doing inference over all variables to compute the likelihood gradient. The iteration complexity for those methods therefore scales with the size of the graphical models. In this paper, we propose \emph{block belief propagation learning} (BBPL), which uses block-coordinate updates of approximate marginals to compute approximate gradients, removing the need to compute inference on the entire graphical model. Thus, the iteration complexity of BBPL does not scale with the size of the graphs. We prove that the method converges to the same solution as that obtained by using full inference per iteration, despite these approximations, and we empirically demonstrate its scalability improvements over standard training methods.