 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExpertAD: Enhancing Autonomous Driving Systems with Mixture of Experts
Nov 13, 2025Recent advancements in end-to-end autonomous driving systems (ADSs) underscore their potential for perception and planning capabilities. However, challenges remain. Complex driving scenarios contain rich semantic information, yet ambiguous or noisy semantics can compromise decision reliability, while interference between multiple driving tasks may hinder optimal planning. Furthermore, prolonged inference latency slows decision-making, increasing the risk of unsafe driving behaviors. To address these challenges, we propose ExpertAD, a novel framework that enhances the performance of ADS with Mixture of Experts (MoE) architecture. We introduce a Perception Adapter (PA) to amplify task-critical features, ensuring contextually relevant scene understanding, and a Mixture of Sparse Experts (MoSE) to minimize task interference during prediction, allowing for effective and efficient planning. Our experiments show that ExpertAD reduces average collision rates by up to 20% and inference latency by 25% compared to prior methods. We further evaluate its multi-skill planning capabilities in rare scenarios (e.g., accidents, yielding to emergency vehicles) and demonstrate strong generalization to unseen urban environments. Additionally, we present a case study that illustrates its decision-making process in complex driving scenarios.
Argus: Resilience-Oriented Safety Assurance Framework for End-to-End ADSs
Nov 12, 2025End-to-end autonomous driving systems (ADSs), with their strong capabilities in environmental perception and generalizable driving decisions, are attracting growing attention from both academia and industry. However, once deployed on public roads, ADSs are inevitably exposed to diverse driving hazards that may compromise safety and degrade system performance. This raises a strong demand for resilience of ADSs, particularly the capability to continuously monitor driving hazards and adaptively respond to potential safety violations, which is crucial for maintaining robust driving behaviors in complex driving scenarios. To bridge this gap, we propose a runtime resilience-oriented framework, Argus, to mitigate the driving hazards, thus preventing potential safety violations and improving the driving performance of an ADS. Argus continuously monitors the trajectories generated by the ADS for potential hazards and, whenever the EGO vehicle is deemed unsafe, seamlessly takes control through a hazard mitigator. We integrate Argus with three state-of-the-art end-to-end ADSs, i.e., TCP, UniAD and VAD. Our evaluation has demonstrated that Argus effectively and efficiently enhances the resilience of ADSs, improving the driving score of the ADS by up to 150.30% on average, and preventing up to 64.38% of the violations, with little additional time overhead.
* The paper has been accepted by the 40th IEEE/ACM International Conference on Automated Software Engineering, ASE 2025
AdvFuzz: Finding More Violations Caused by the EGO Vehicle in Simulation Testing by Adversarial NPC Vehicles
Nov 29, 2024



Recently, there has been a significant escalation in both academic and industrial commitment towards the development of autonomous driving systems (ADSs). A number of simulation testing approaches have been proposed to generate diverse driving scenarios for ADS testing. However, scenarios generated by these previous approaches are static and lack interactions between the EGO vehicle and the NPC vehicles, resulting in a large amount of time on average to find violation scenarios. Besides, a large number of the violations they found are caused by aggressive behaviors of NPC vehicles, revealing none bugs of ADS. In this work, we propose the concept of adversarial NPC vehicles and introduce AdvFuzz, a novel simulation testing approach, to generate adversarial scenarios on main lanes (e.g., urban roads and highways). AdvFuzz allows NPC vehicles to dynamically interact with the EGO vehicle and regulates the behaviors of NPC vehicles, finding more violation scenarios caused by the EGO vehicle more quickly. We compare AdvFuzz with a random approach and three state-of-the-art scenario-based testing approaches. Our experiments demonstrate that AdvFuzz can generate 198.34% more violation scenarios compared to the other four approaches in 12 hours and increase the proportion of violations caused by the EGO vehicle to 87.04%, which is more than 7 times that of other approaches. Additionally, AdvFuzz is at least 92.21% faster in finding one violation caused by the EGO vehicle than that of the other approaches.
RoadGen: Generating Road Scenarios for Autonomous Vehicle Testing
Nov 29, 2024



With the rapid development of autonomous vehicles, there is an increasing demand for scenario-based testing to simulate diverse driving scenarios. However, as the base of any driving scenarios, road scenarios (e.g., road topology and geometry) have received little attention by the literature. Despite several advances, they either generate basic road components without a complete road network, or generate a complete road network but with simple road components. The resulting road scenarios lack diversity in both topology and geometry. To address this problem, we propose RoadGen to systematically generate diverse road scenarios. The key idea is to connect eight types of parameterized road components to form road scenarios with high diversity in topology and geometry. Our evaluation has demonstrated the effectiveness and usefulness of RoadGen in generating diverse road scenarios for simulation.
A general approach to enhance the survivability of backdoor attacks by decision path coupling
Mar 05, 2024



Backdoor attacks have been one of the emerging security threats to deep neural networks (DNNs), leading to serious consequences. One of the mainstream backdoor defenses is model reconstruction-based. Such defenses adopt model unlearning or pruning to eliminate backdoors. However, little attention has been paid to survive from such defenses. To bridge the gap, we propose Venom, the first generic backdoor attack enhancer to improve the survivability of existing backdoor attacks against model reconstruction-based defenses. We formalize Venom as a binary-task optimization problem. The first is the original backdoor attack task to preserve the original attack capability, while the second is the attack enhancement task to improve the attack survivability. To realize the second task, we propose attention imitation loss to force the decision path of poisoned samples in backdoored models to couple with the crucial decision path of benign samples, which makes backdoors difficult to eliminate. Our extensive evaluation on two DNNs and three datasets has demonstrated that Venom significantly improves the survivability of eight state-of-the-art attacks against eight state-of-the-art defenses without impacting the capability of the original attacks.
Understanding the Complexity and Its Impact on Testing in ML-Enabled Systems
Jan 10, 2023



Machine learning (ML) enabled systems are emerging with recent breakthroughs in ML. A model-centric view is widely taken by the literature to focus only on the analysis of ML models. However, only a small body of work takes a system view that looks at how ML components work with the system and how they affect software engineering for MLenabled systems. In this paper, we adopt this system view, and conduct a case study on Rasa 3.0, an industrial dialogue system that has been widely adopted by various companies around the world. Our goal is to characterize the complexity of such a largescale ML-enabled system and to understand the impact of the complexity on testing. Our study reveals practical implications for software engineering for ML-enabled systems.
Characterizing Performance Bugs in Deep Learning Systems
Dec 03, 2021

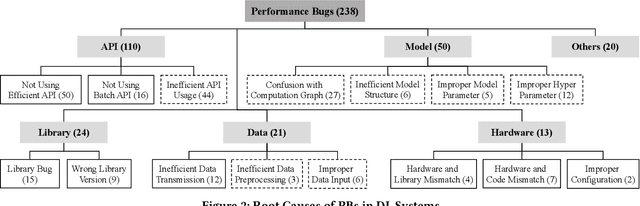

Deep learning (DL) has been increasingly applied to a variety of domains. The programming paradigm shift from traditional systems to DL systems poses unique challenges in engineering DL systems. Performance is one of the challenges, and performance bugs(PBs) in DL systems can cause severe consequences such as excessive resource consumption and financial loss. While bugs in DL systems have been extensively investigated, PBs in DL systems have hardly been explored. To bridge this gap, we present the first comprehensive study to characterize symptoms, root causes, and introducing and exposing stages of PBs in DL systems developed in TensorFLow and Keras, with a total of 238 PBs collected from 225 StackOverflow posts. Our findings shed light on the implications on developing high performance DL systems, and detecting and localizing PBs in DL systems. We also build the first benchmark of 56 PBs in DL systems, and assess the capability of existing approaches in tackling them. Moreover, we develop a static checker DeepPerf to detect three types of PBs, and identify 488 new PBs in 130 GitHub projects.62 and 18 of them have been respectively confirmed and fixed by developers.