 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePart-level Car Parsing and Reconstruction from Single Street View
Paper and Code
Nov 27, 2018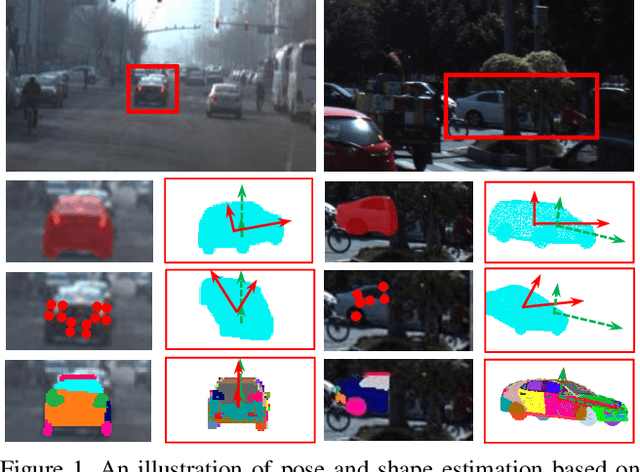
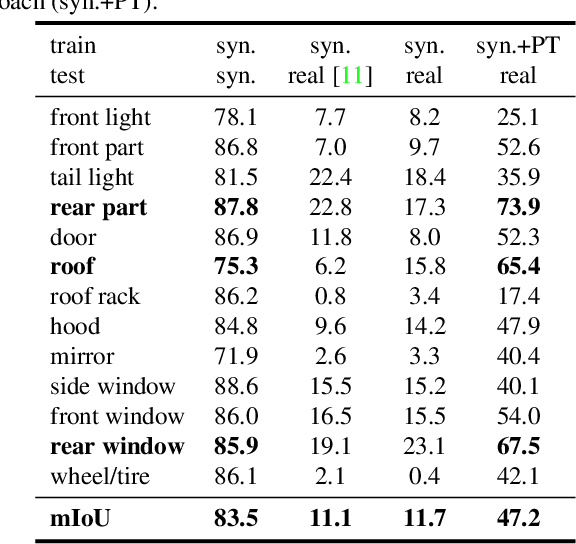
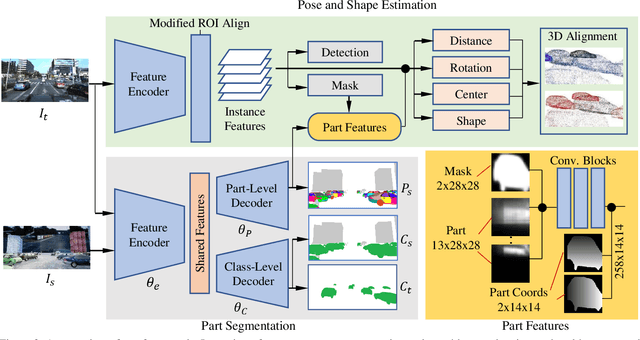
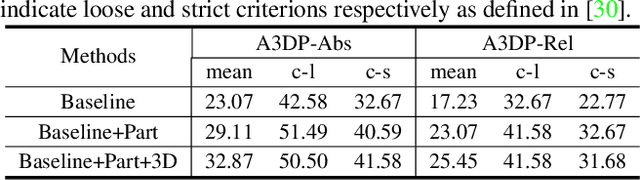
In this paper, we make the first attempt to build a framework to simultaneously estimate semantic parts, shape, translation, and orientation of cars from single street view. Our framework contains three major contributions. Firstly, a novel domain adaptation approach based on the class consistency loss is developed to transfer our part segmentation model from the synthesized images to the real images. Secondly, we propose a novel network structure that leverages part-level features from street views and 3D losses for pose and shape estimation. Thirdly, we construct a high quality dataset that contains more than 300 different car models with physical dimensions and part-level annotations based on global and local deformations. We have conducted experiments on both synthesized data and real images. Our results show that the domain adaptation approach can bring 35.5 percentage point performance improvement in terms of mean intersection-over-union score (mIoU) comparing with the baseline network using domain randomization only. Our network for translation and orientation estimation achieves competitive performance on highly complex street views (e.g., 11 cars per image on average). Moreover, our network is able to reconstruct a list of 3D car models with part-level details from street views, which could benefit various applications such as fine-grained car recognition, vehicle re-identification, and traffic simulation.