 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGraphMI: Extracting Private Graph Data from Graph Neural Networks
Paper and Code
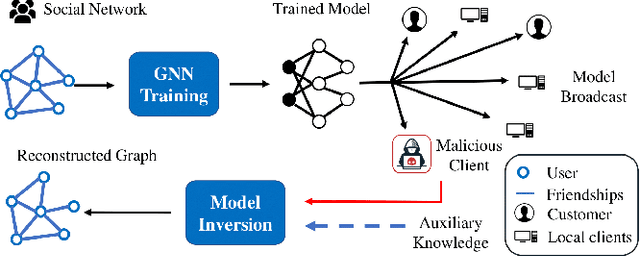

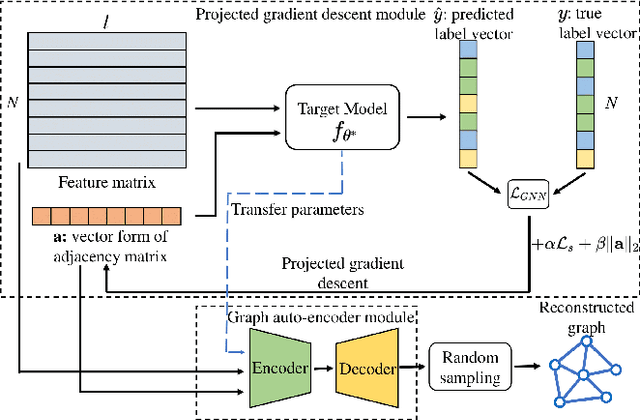
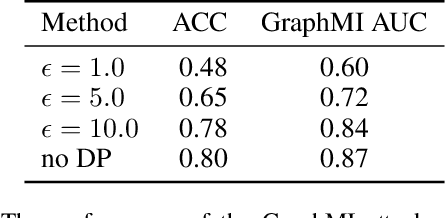
As machine learning becomes more widely used for critical applications, the need to study its implications in privacy turns to be urgent. Given access to the target model and auxiliary information, the model inversion attack aims to infer sensitive features of the training dataset, which leads to great privacy concerns. Despite its success in grid-like domains, directly applying model inversion techniques on non-grid domains such as graph achieves poor attack performance due to the difficulty to fully exploit the intrinsic properties of graphs and attributes of nodes used in Graph Neural Networks (GNN). To bridge this gap, we present \textbf{Graph} \textbf{M}odel \textbf{I}nversion attack (GraphMI), which aims to extract private graph data of the training graph by inverting GNN, one of the state-of-the-art graph analysis tools. Specifically, we firstly propose a projected gradient module to tackle the discreteness of graph edges while preserving the sparsity and smoothness of graph features. Then we design a graph auto-encoder module to efficiently exploit graph topology, node attributes, and target model parameters for edge inference. With the proposed methods, we study the connection between model inversion risk and edge influence and show that edges with greater influence are more likely to be recovered. Extensive experiments over several public datasets demonstrate the effectiveness of our method. We also show that differential privacy in its canonical form can hardly defend our attack while preserving decent utility.