 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFast Variational AutoEncoder with Inverted Multi-Index for Collaborative Filtering
Sep 13, 2021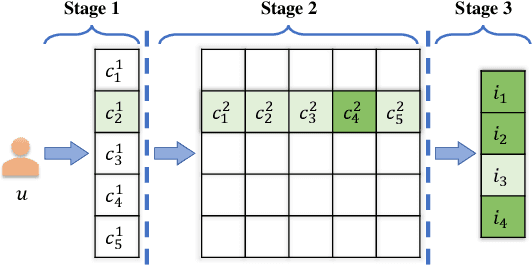

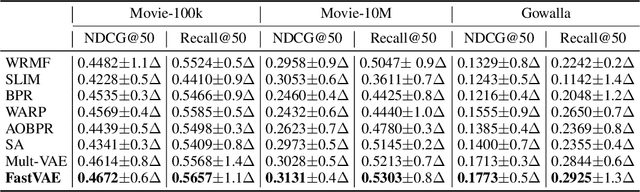

Variational AutoEncoder (VAE) has been extended as a representative nonlinear method for collaborative filtering. However, the bottleneck of VAE lies in the softmax computation over all items, such that it takes linear costs in the number of items to compute the loss and gradient for optimization. This hinders the practical use due to millions of items in real-world scenarios. Importance sampling is an effective approximation method, based on which the sampled softmax has been derived. However, existing methods usually exploit the uniform or popularity sampler as proposal distributions, leading to a large bias of gradient estimation. To this end, we propose to decompose the inner-product-based softmax probability based on the inverted multi-index, leading to sublinear-time and highly accurate sampling. Based on the proposed proposals, we develop a fast Variational AutoEncoder (FastVAE) for collaborative filtering. FastVAE can outperform the state-of-the-art baselines in terms of both sampling quality and efficiency according to the experiments on three real-world datasets.
Sampling-Decomposable Generative Adversarial Recommender
Nov 02, 2020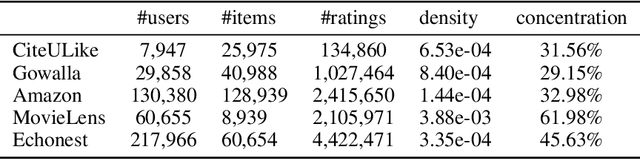
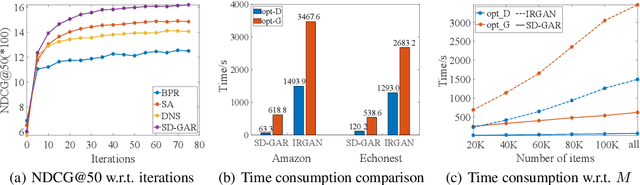
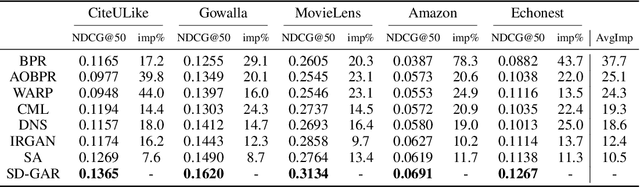
Recommendation techniques are important approaches for alleviating information overload. Being often trained on implicit user feedback, many recommenders suffer from the sparsity challenge due to the lack of explicitly negative samples. The GAN-style recommenders (i.e., IRGAN) addresses the challenge by learning a generator and a discriminator adversarially, such that the generator produces increasingly difficult samples for the discriminator to accelerate optimizing the discrimination objective. However, producing samples from the generator is very time-consuming, and our empirical study shows that the discriminator performs poor in top-k item recommendation. To this end, a theoretical analysis is made for the GAN-style algorithms, showing that the generator of limit capacity is diverged from the optimal generator. This may interpret the limitation of discriminator's performance. Based on these findings, we propose a Sampling-Decomposable Generative Adversarial Recommender (SD-GAR). In the framework, the divergence between some generator and the optimum is compensated by self-normalized importance sampling; the efficiency of sample generation is improved with a sampling-decomposable generator, such that each sample can be generated in O(1) with the Vose-Alias method. Interestingly, due to decomposability of sampling, the generator can be optimized with the closed-form solutions in an alternating manner, being different from policy gradient in the GAN-style algorithms. We extensively evaluate the proposed algorithm with five real-world recommendation datasets. The results show that SD-GAR outperforms IRGAN by 12.4% and the SOTA recommender by 10% on average. Moreover, discriminator training can be 20x faster on the dataset with more than 120K items.
Promotion of Answer Value Measurement with Domain Effects in Community Question Answering Systems
Jun 01, 2019
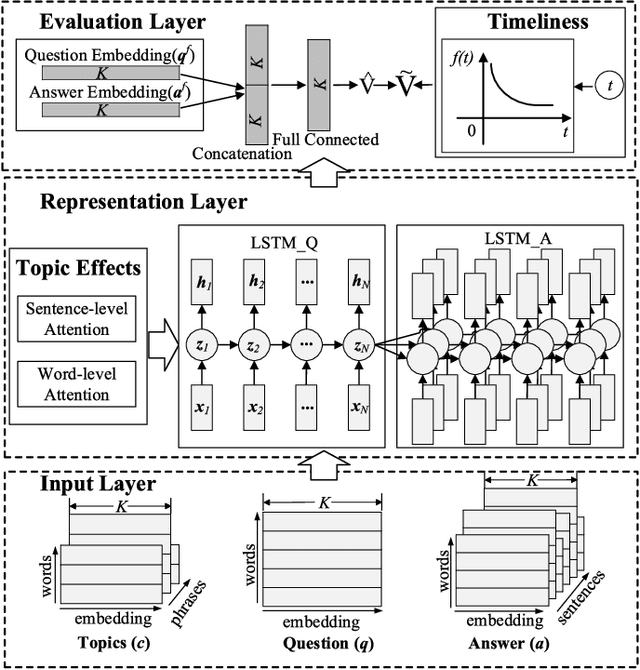
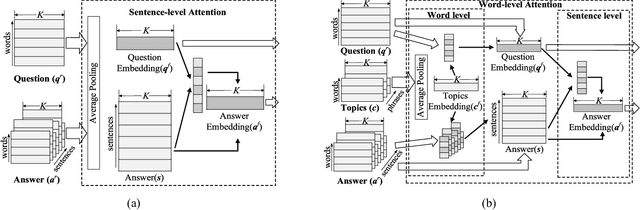

In the area of community question answering (CQA), answer selection and answer ranking are two tasks which are applied to help users quickly access valuable answers. Existing solutions mainly exploit the syntactic or semantic correlation between a question and its related answers (Q&A), where the multi-facet domain effects in CQA are still underexplored. In this paper, we propose a unified model, Enhanced Attentive Recurrent Neural Network (EARNN), for both answer selection and answer ranking tasks by taking full advantages of both Q&A semantics and multi-facet domain effects (i.e., topic effects and timeliness). Specifically, we develop a serialized LSTM to learn the unified representations of Q&A, where two attention mechanisms at either sentence-level or word-level are designed for capturing the deep effects of topics. Meanwhile, the emphasis of Q&A can be automatically distinguished. Furthermore, we design a time-sensitive ranking function to model the timeliness in CQA. To effectively train EARNN, a question-dependent pairwise learning strategy is also developed. Finally, we conduct extensive experiments on a real-world dataset from Quora. Experimental results validate the effectiveness and interpretability of our proposed EARNN model.