 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelective Mixup for Debiasing Question Selection in Computerized Adaptive Testing
Nov 19, 2025Computerized Adaptive Testing (CAT) is a widely used technology for evaluating learners' proficiency in online education platforms. By leveraging prior estimates of proficiency to select questions and updating the estimates iteratively based on responses, CAT enables personalized learner modeling and has attracted substantial attention. Despite this progress, most existing works focus primarily on improving diagnostic accuracy, while overlooking the selection bias inherent in the adaptive process. Selection Bias arises because the question selection is strongly influenced by the estimated proficiency, such as assigning easier questions to learners with lower proficiency and harder ones to learners with higher proficiency. Since the selection depends on prior estimation, this bias propagates into the diagnosis model, which is further amplified during iterative updates, leading to misalignment and biased predictions. Moreover, the imbalanced nature of learners' historical interactions often exacerbates the bias in diagnosis models. To address this issue, we propose a debiasing framework consisting of two key modules: Cross-Attribute Examinee Retrieval and Selective Mixup-based Regularization. First, we retrieve balanced examinees with relatively even distributions of correct and incorrect responses and use them as neutral references for biased examinees. Then, mixup is applied between each biased examinee and its matched balanced counterpart under label consistency. This augmentation enriches the diversity of bias-conflicting samples and smooths selection boundaries. Finally, extensive experiments on two benchmark datasets with multiple advanced diagnosis models demonstrate that our method substantially improves both the generalization ability and fairness of question selection in CAT.
MoLoRec: A Generalizable and Efficient Framework for LLM-Based Recommendation
Feb 12, 2025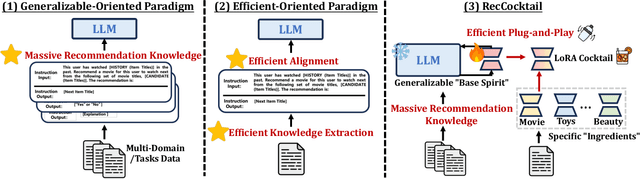
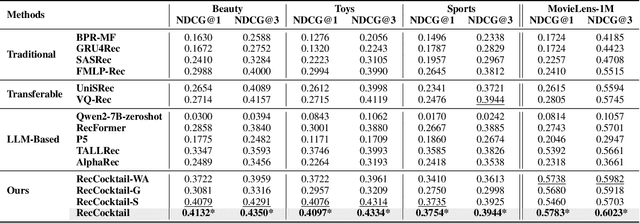
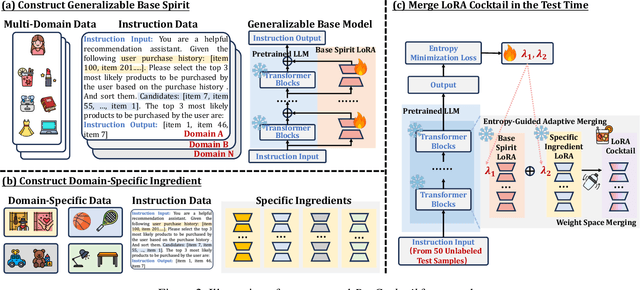
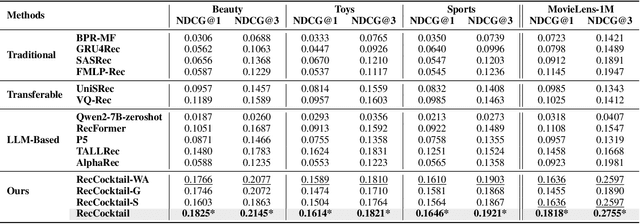
Large Language Models (LLMs) have achieved remarkable success in recent years, owing to their impressive generalization capabilities and rich world knowledge. To capitalize on the potential of using LLMs as recommender systems, mainstream approaches typically focus on two paradigms. The first paradigm designs multi-domain or multi-task instruction data for generalizable recommendation, so as to align LLMs with general recommendation areas and deal with cold-start recommendation. The second paradigm enhances domain-specific recommendation tasks with parameter-efficient fine-tuning techniques, in order to improve models under the warm recommendation scenarios. While most previous works treat these two paradigms separately, we argue that they have complementary advantages, and combining them together would be helpful. To that end, in this paper, we propose a generalizable and efficient LLM-based recommendation framework MoLoRec. Our approach starts by parameter-efficient fine-tuning a domain-general module with general recommendation instruction data, to align LLM with recommendation knowledge. Then, given users' behavior of a specific domain, we construct a domain-specific instruction dataset and apply efficient fine-tuning to the pre-trained LLM. After that, we provide approaches to integrate the above domain-general part and domain-specific part with parameters mixture. Please note that, MoLoRec is efficient with plug and play, as the domain-general module is trained only once, and any domain-specific plug-in can be efficiently merged with only domain-specific fine-tuning. Extensive experiments on multiple datasets under both warm and cold-start recommendation scenarios validate the effectiveness and generality of the proposed MoLoRec.
InvDiff: Invariant Guidance for Bias Mitigation in Diffusion Models
Dec 11, 2024



As one of the most successful generative models, diffusion models have demonstrated remarkable efficacy in synthesizing high-quality images. These models learn the underlying high-dimensional data distribution in an unsupervised manner. Despite their success, diffusion models are highly data-driven and prone to inheriting the imbalances and biases present in real-world data. Some studies have attempted to address these issues by designing text prompts for known biases or using bias labels to construct unbiased data. While these methods have shown improved results, real-world scenarios often contain various unknown biases, and obtaining bias labels is particularly challenging. In this paper, we emphasize the necessity of mitigating bias in pre-trained diffusion models without relying on auxiliary bias annotations. To tackle this problem, we propose a framework, InvDiff, which aims to learn invariant semantic information for diffusion guidance. Specifically, we propose identifying underlying biases in the training data and designing a novel debiasing training objective. Then, we employ a lightweight trainable module that automatically preserves invariant semantic information and uses it to guide the diffusion model's sampling process toward unbiased outcomes simultaneously. Notably, we only need to learn a small number of parameters in the lightweight learnable module without altering the pre-trained diffusion model. Furthermore, we provide a theoretical guarantee that the implementation of InvDiff is equivalent to reducing the error upper bound of generalization. Extensive experimental results on three publicly available benchmarks demonstrate that InvDiff effectively reduces biases while maintaining the quality of image generation. Our code is available at https://github.com/Hundredl/InvDiff.