 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptSSR: Pre-training User Model with Augmentation-Adaptive Self-Supervised Ranking
Oct 24, 2023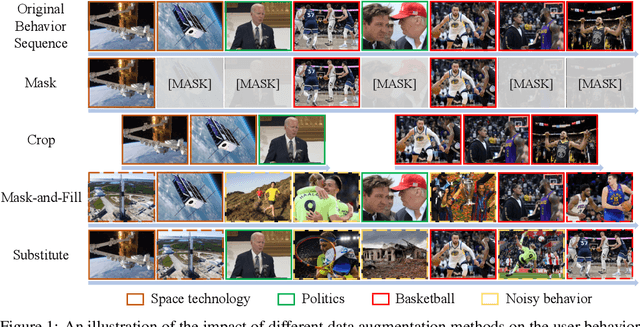
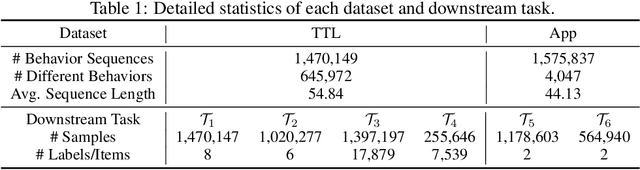
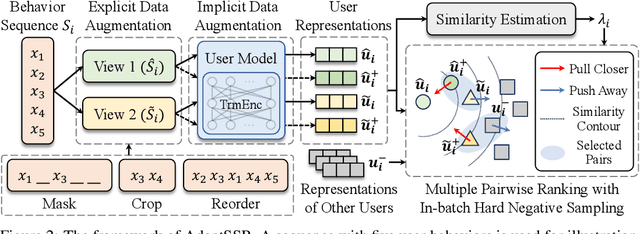
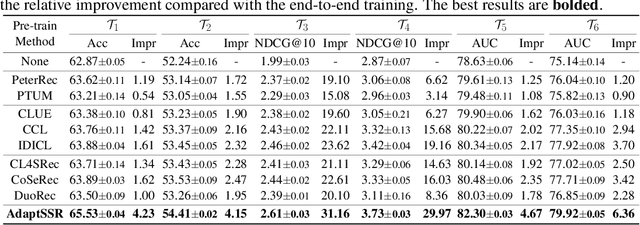
User modeling, which aims to capture users' characteristics or interests, heavily relies on task-specific labeled data and suffers from the data sparsity issue. Several recent studies tackled this problem by pre-training the user model on massive user behavior sequences with a contrastive learning task. Generally, these methods assume different views of the same behavior sequence constructed via data augmentation are semantically consistent, i.e., reflecting similar characteristics or interests of the user, and thus maximizing their agreement in the feature space. However, due to the diverse interests and heavy noise in user behaviors, existing augmentation methods tend to lose certain characteristics of the user or introduce noisy behaviors. Thus, forcing the user model to directly maximize the similarity between the augmented views may result in a negative transfer. To this end, we propose to replace the contrastive learning task with a new pretext task: Augmentation-Adaptive SelfSupervised Ranking (AdaptSSR), which alleviates the requirement of semantic consistency between the augmented views while pre-training a discriminative user model. Specifically, we adopt a multiple pairwise ranking loss which trains the user model to capture the similarity orders between the implicitly augmented view, the explicitly augmented view, and views from other users. We further employ an in-batch hard negative sampling strategy to facilitate model training. Moreover, considering the distinct impacts of data augmentation on different behavior sequences, we design an augmentation-adaptive fusion mechanism to automatically adjust the similarity order constraint applied to each sample based on the estimated similarity between the augmented views. Extensive experiments on both public and industrial datasets with six downstream tasks verify the effectiveness of AdaptSSR.
Untargeted Attack against Federated Recommendation Systems via Poisonous Item Embeddings and the Defense
Dec 11, 2022



Federated recommendation (FedRec) can train personalized recommenders without collecting user data, but the decentralized nature makes it susceptible to poisoning attacks. Most previous studies focus on the targeted attack to promote certain items, while the untargeted attack that aims to degrade the overall performance of the FedRec system remains less explored. In fact, untargeted attacks can disrupt the user experience and bring severe financial loss to the service provider. However, existing untargeted attack methods are either inapplicable or ineffective against FedRec systems. In this paper, we delve into the untargeted attack and its defense for FedRec systems. (i) We propose ClusterAttack, a novel untargeted attack method. It uploads poisonous gradients that converge the item embeddings into several dense clusters, which make the recommender generate similar scores for these items in the same cluster and perturb the ranking order. (ii) We propose a uniformity-based defense mechanism (UNION) to protect FedRec systems from such attacks. We design a contrastive learning task that regularizes the item embeddings toward a uniform distribution. Then the server filters out these malicious gradients by estimating the uniformity of updated item embeddings. Experiments on two public datasets show that ClusterAttack can effectively degrade the performance of FedRec systems while circumventing many defense methods, and UNION can improve the resistance of the system against various untargeted attacks, including our ClusterAttack.